By default, Scrapy framework provides a way to export scraped data into CSV, JSON, JSONL, XML files with a possibility to store them remotely. However, we may need more flexibility in how and where the scraped data will be stored. This is the purpose of Scrapy item pipelines. Scrapy pipeline is a component of Scrapy project for implementing post-processing and exporting of scraped data. We are going to discuss how to implement data export code in pipelines and provide a couple of examples.
At code level, pipeline is a Python class that implements one or more of the following methods:
open_spider()- called when scraping starts.process_item()- called when new item was scraped in the spider.close_spider()called when scraping ends.from_crawler()(class method) - factory method that is called from Scrapy crawler object to create an instance of pipeline class, possibly with some customizations based on project settings.
We will do our preparations to export data in open_spider(), process data one item at a time in
process_item() and finalise data export in close_spider() method.
For the sake of simplicity, we will use quotesbot Scrapy project. We will edit pipelines.py file to implement new pipelines and will also make minor changes to settings.py file to enable newly developed pipelines in the project.
Using openpyxl to write data to Excel file
Let us implement open_spider() first.
def open_spider(self, spider):
self.wb = openpyxl.Workbook()
self.ws = self.wb.active
self.ws.append(FIELDNAMES)
We instantiated openpyxl.Workbook object into instance variable and also saved a reference to
active work sheet (page within spreadsheet). Lastly, we created a header row in the spreadsheet
by appending list of fieldnames.
Now we can process items. Let us implement process_item() method.
def process_item(self, item, spider):
adapter = ItemAdapter(item)
self.ws.append([adapter.get("text"), adapter.get("author"), ",".join(adapter.get("tags"))])
return item
First, we wrapped the item we have received into ItemAdapter object that provides unified API for all kinds
of items that we can come across. For such a trivial example this may not be necessary, but it might prove to be useful
in larger, more complex Scrapy project and is a generally recommended thing to do. Next, we are calling append() on
openpyxl worksheet object with a list of strings to be appended, ordered in such a way that they line up with
order of fieldnames. This ensures that values of each field are lining up with the header row in the final document.
Note that we cannot write tags directly due to it being a list of strings. To address this issue, we convert it to
a single string by using comma character as separator.
Finally, we need to implement close_spider() method where we will call save() on openpyxl Workbook to perform
an actual writing to file system.
def close_spider(self, spider):
self.wb.save(XLSX_PATH)
The entire code for this pipeline is as follows:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from itemadapter import ItemAdapter
import openpyxl
from quotesbot.settings import XLSX_PATH
FIELDNAMES = ['text', 'author', 'tags']
class XLSXPipeline(object):
wb = None
ws = None
def open_spider(self, spider):
self.wb = openpyxl.Workbook()
self.ws = self.wb.active
self.ws.append(FIELDNAMES)
def process_item(self, item, spider):
adapter = ItemAdapter(item)
self.ws.append([adapter.get("text"), adapter.get("author"), ",".join(adapter.get("tags"))])
return item
def close_spider(self, spider):
self.wb.save(XLSX_PATH)
Now we need to enable this pipeline in settings.py and also set the XLSX_PATH configuration setting to some value.
We uncomment ITEM_PIPELINES dictionary and edit with a complete class name or our pipeline:
ITEM_PIPELINES = {
'quotesbot.pipelines.XLSXPipeline': 300,
}
We also set the XLSX_PATH:
XLSX_PATH = "quotes.xlsx"
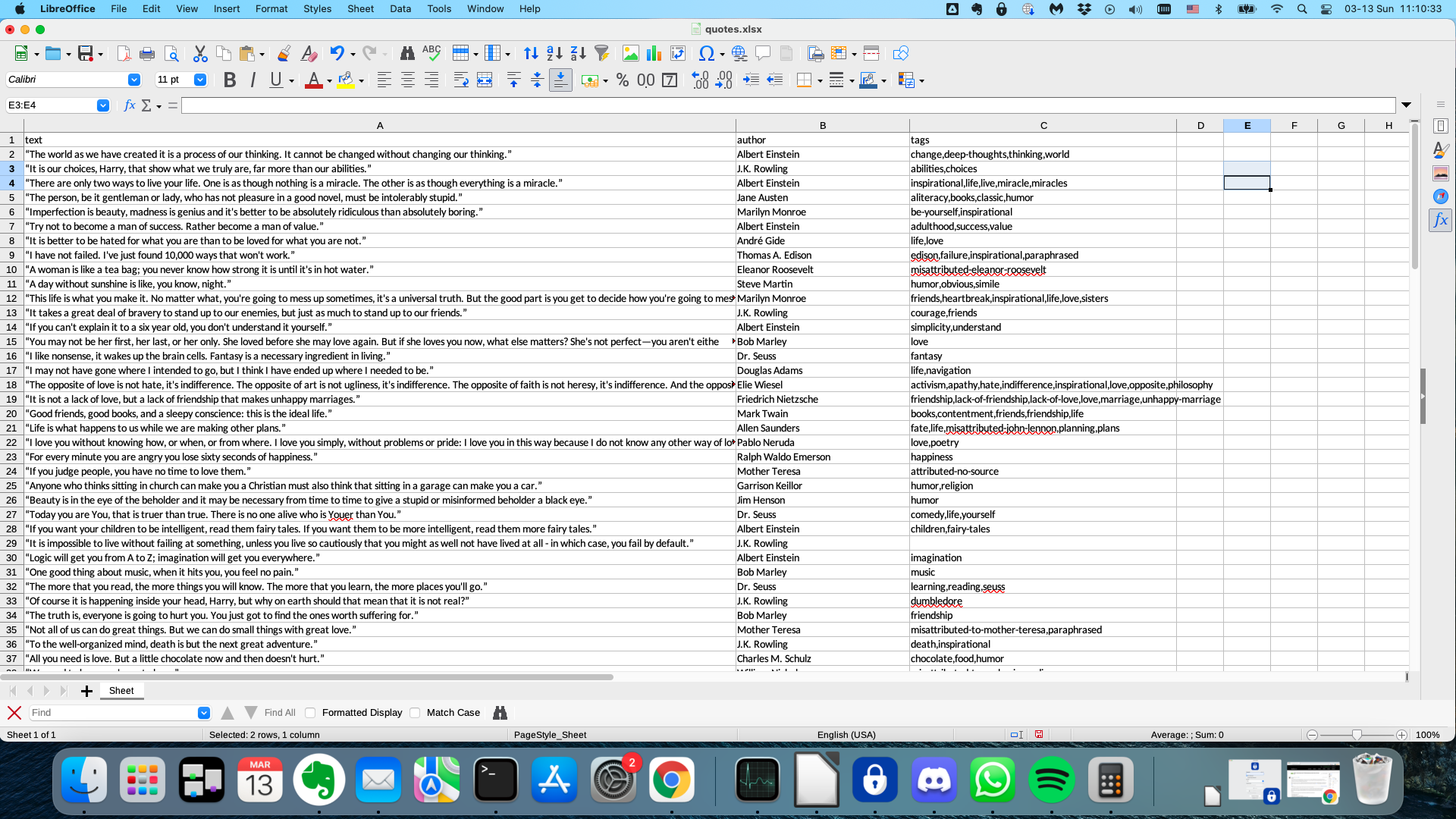
Running any of the two spiders creates an Excel spreadsheet with scraped data.
{kind=link}
Saving scraped data to SQLite
We have a two tiered structure to our data: at one level, there’s quotes and at another we have lists of tags, associated with each quote. In our openpyxl-based code we squashed the both levels into one by forcing each list of tags to became a comma-separated string. It would be nice to keep the initial structure when saving the data for storage. This is where a database comes in. For simplicity, we will use a database management system that is truly serverless in the most literal sense of the world: SQLite. We will be setting up our tables in a single file in local system and writing our data there.
Let us go through the same steps we did in our previous pipeline, but do them for SQLite now.
Implementing open_spider() involves creating a database connection object and two tables in the new database:
def open_spider(self, spider):
self.db_conn = sqlite3.connect(SQLITE_PATH)
self.db_conn.execute("CREATE TABLE quote(id INTEGER PRIMARY KEY, text TEXT, author TEXT);")
self.db_conn.execute("CREATE TABLE tag(id INTEGER PRIMARY KEY, text TEXT, quote_id, FOREIGN KEY(quote_id) REFERENCES quote(id));")
self.db_conn.commit()
One thing to note here is that tag table references quote table via foreign key, which represents a parent-child relationship
between quote an tag. Calling commit() on database connection object saves the changes into file. Generally execute() is not
directly called on DB connection directly like we do here - cursor object is used instead. We will be using the cursor in our next
method - process_item():
def process_item(self, item, spider):
adapter = ItemAdapter(item)
text = adapter.get("text")
author = adapter.get("author")
tags = adapter.get("tags", [])
cursor = self.db_conn.cursor()
cursor.execute("INSERT INTO quote(text, author) VALUES (?, ?);", (text, author))
quote_id = cursor.lastrowid
for t in tags:
cursor.execute("INSERT INTO tag(text, quote_id) VALUES (?, ?);", (t, quote_id))
self.db_conn.commit()
return item
In this method, we use SQLite Python API from vanilla Python installation to insert rows into both tables. We make sure that
tag row properly points to a corresponding quote row via the foreign key field.
Lastly, we need to implement close_spider() method that merely closes the DB connection:
def close_spider(self, spider):
self.db_conn.close()
Last thing we need to do is to update settings.py file so that part about pipelines is as follows:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'quotesbot.pipelines.XLSXPipeline': 300,
'quotesbot.pipelines.SQLitePipeline': 301,
}
XLSX_PATH = "quotes.xlsx"
SQLITE_PATH = "quotes.db"
In this case, the priority value of first pipeline is lower, thus making it be executed first. That does not matter in such a trivial example, but it might be important depending on the exact specifics of your project. If you have additional pipelines performing data cleaning, filtering or other changes you want them to be executed before the data export pipelines.
Running the Scrapy project again creates the quotes.db file that we can access via SQLite program:
$ sqlite3 quotes.db
-- Loading resources from /Users/[REDACTED]/.sqliterc
SQLite version 3.32.2 2020-06-04 12:58:43
Enter ".help" for usage hints.
sqlite> .schema
CREATE TABLE quote(id INTEGER PRIMARY KEY, text TEXT, author TEXT);
CREATE TABLE tag(id INTEGER PRIMARY KEY, text TEXT, quote_id, FOREIGN KEY(quote_id) REFERENCES quote(id));
sqlite> SELECT * FROM quote LIMIT 10;
id text author
---------- ------------------------------------------------------------------------------------------------------------------- ---------------
1 “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” Albert Einstein
2 “It is our choices, Harry, that show what we truly are, far more than our abilities.” J.K. Rowling
3 “There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everythin Albert Einstein
4 “The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.” Jane Austen
5 “Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.” Marilyn Monroe
6 “Try not to become a man of success. Rather become a man of value.” Albert Einstein
7 “It is better to be hated for what you are than to be loved for what you are not.” André Gide
8 “I have not failed. I've just found 10,000 ways that won't work.” Thomas A. Ediso
9 “A woman is like a tea bag; you never know how strong it is until it's in hot water.” Eleanor Rooseve
10 “A day without sunshine is like, you know, night.” Steve Martin
sqlite> SELECT * FROM tag WHERE quote_id = 1;
id text quote_id
---------- ---------- ----------
1 change 1
2 deep-thoug 1
3 thinking 1
4 world 1
In case you are wondering about formatting of output being nicer than it typically is: it can be configured to show data in columns by putting the following two lines into ~/.sqliterc:
.mode column on
.headers on
To sum it up, the code for entire pipeline that saves data to SQLite DB is as follows:
import sqlite3
from quotesbot.settings import SQLITE_PATH
from itemadapter import ItemAdapter
class SQLitePipeline(object):
db_conn = None
def open_spider(self, spider):
self.db_conn = sqlite3.connect(SQLITE_PATH)
self.db_conn.execute("CREATE TABLE quote(id INTEGER PRIMARY KEY, text TEXT, author TEXT);")
self.db_conn.execute("CREATE TABLE tag(id INTEGER PRIMARY KEY, text TEXT, quote_id, FOREIGN KEY(quote_id) REFERENCES quote(id));")
self.db_conn.commit()
def process_item(self, item, spider):
adapter = ItemAdapter(item)
text = adapter.get("text")
author = adapter.get("author")
tags = adapter.get("tags", [])
cursor = self.db_conn.cursor()
cursor.execute("INSERT INTO quote(text, author) VALUES (?, ?);", (text, author))
quote_id = cursor.lastrowid
for t in tags:
cursor.execute("INSERT INTO tag(text, quote_id) VALUES (?, ?);", (t, quote_id))
self.db_conn.commit()
return item
def close_spider(self, spider):
self.db_conn.close()