Web scraping is a widely known way to gather information from external sources. However, it is not the only way. Another way is API scraping. We define API scraping as the activity of automatically extracting data from reverse engineered private APIs. In this post, we will go through an example of the reverse engineering private API of a mobile app and developing a simple API scraping script that reproduces API calls to extract the exact information that the app is showing on the mobile device.
To exemplify API scraping, we will be extracting a list of ongoing anime TV series form MyAnimeList Official app. The part of the app we are interested in is “This Season” subtab in “Seasonal” tab.
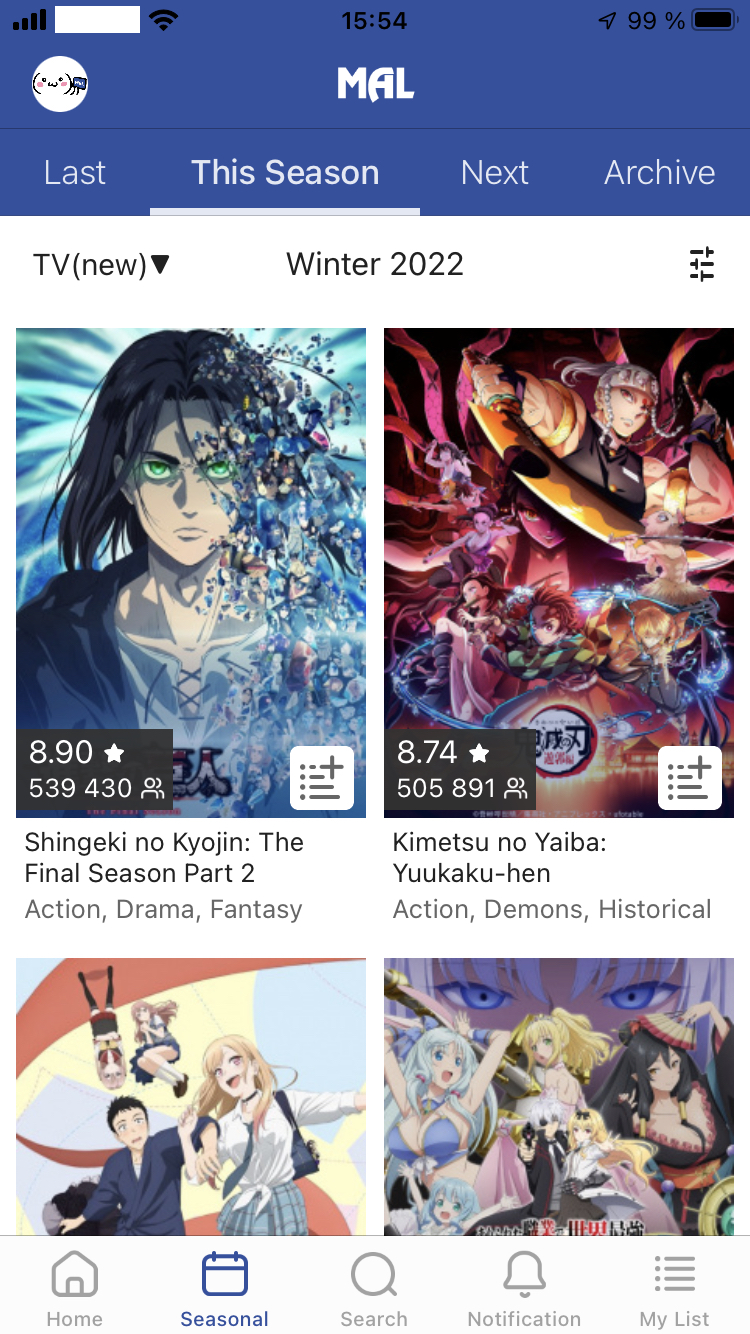{kind=link}
The tool we will be using for intercepting HTTP traffic is called mitmproxy. It is a little HTTP proxy server that can be launched on your computer and provide a way to inspect and modify the HTTP traffic even if TLS is used. Luckily MAL app does not perform TLS cert pinning which makes it fairly easy to intercept private API calls with a proper setup.
In this post, I won’t be covering how to set up mitmproxy with your mobile device as there are many blog posts and Youtube videos detailing on how to do this with both iOS and Android devices. You may want to check out:
- Intercept iOS/Android Network Calls using mitmproxy on Medium
- Reverse Engineering a Private API with mitmproxy on Youtube
Once mitmproxy is running in the local network and iPhone is configured to pass HTTP requests through mitmproxy instance, we are ready to do some reverse engineering of API communications. We start by performing user actions on the app and see requests appearing in mitmproxy flow list. In mitmproxy parlance, flow is a collection of inter-related network messages. At this point, we are only concerned about HTTP flows that consist of HTTP requests and corresponding responses. Pay close attention to what HTTP flows correspond to which action is performed on the app. Occasionally you may want to press Z key to clean up the flow list so that the exact flows you want to see for specific action appear on the top of new list.
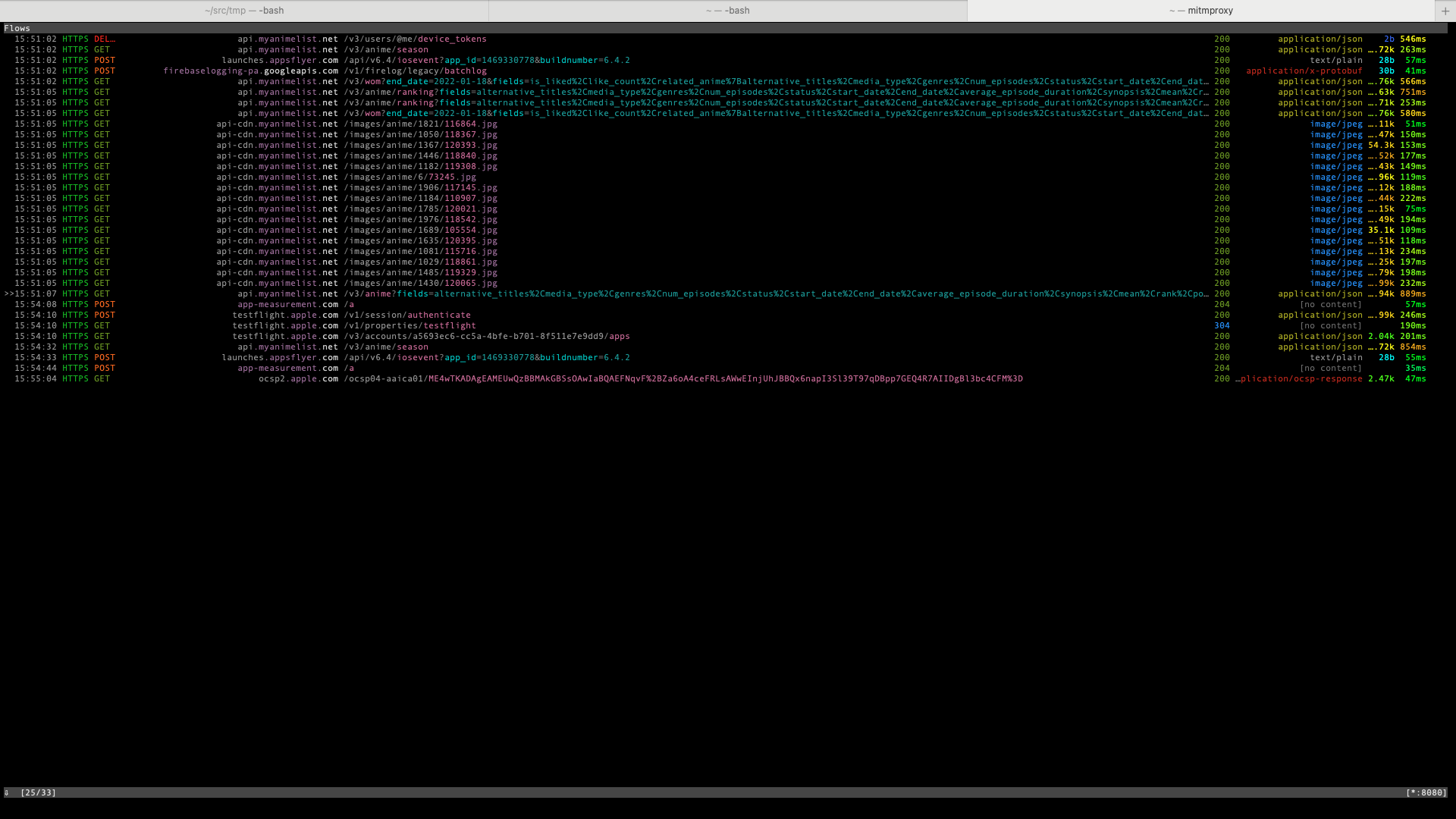{kind=link}
We can navigate the flow list with arrow keys and press Enter on the entry that we want to inspect closer. If we want to export requests, responses or both to a file that can be either curl(1) snippet or raw representation of HTTP messages, we can press the E key and mitmproxy will present a menu with several choices.
Flow details - request Flow details - response
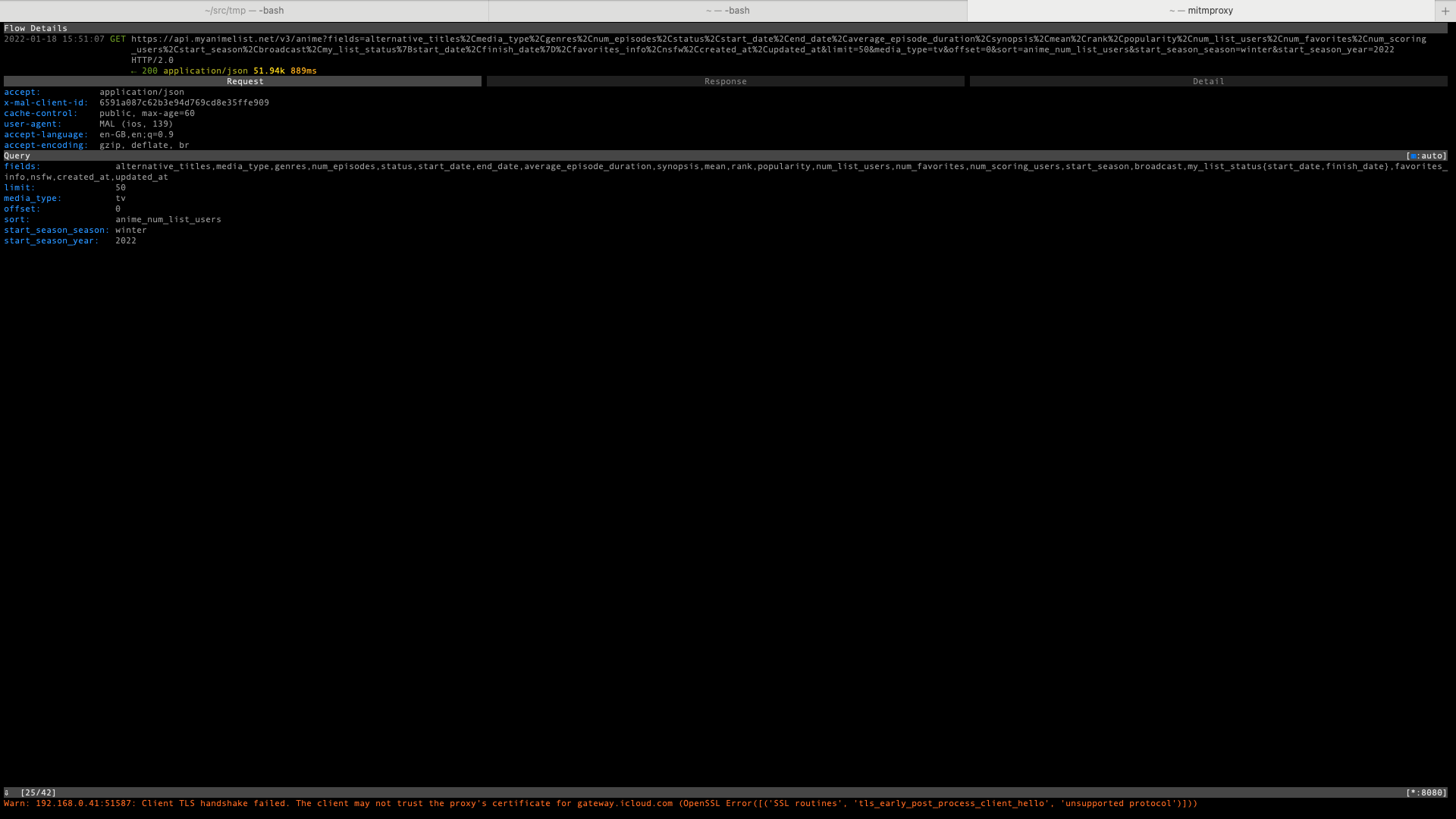{kind=link}
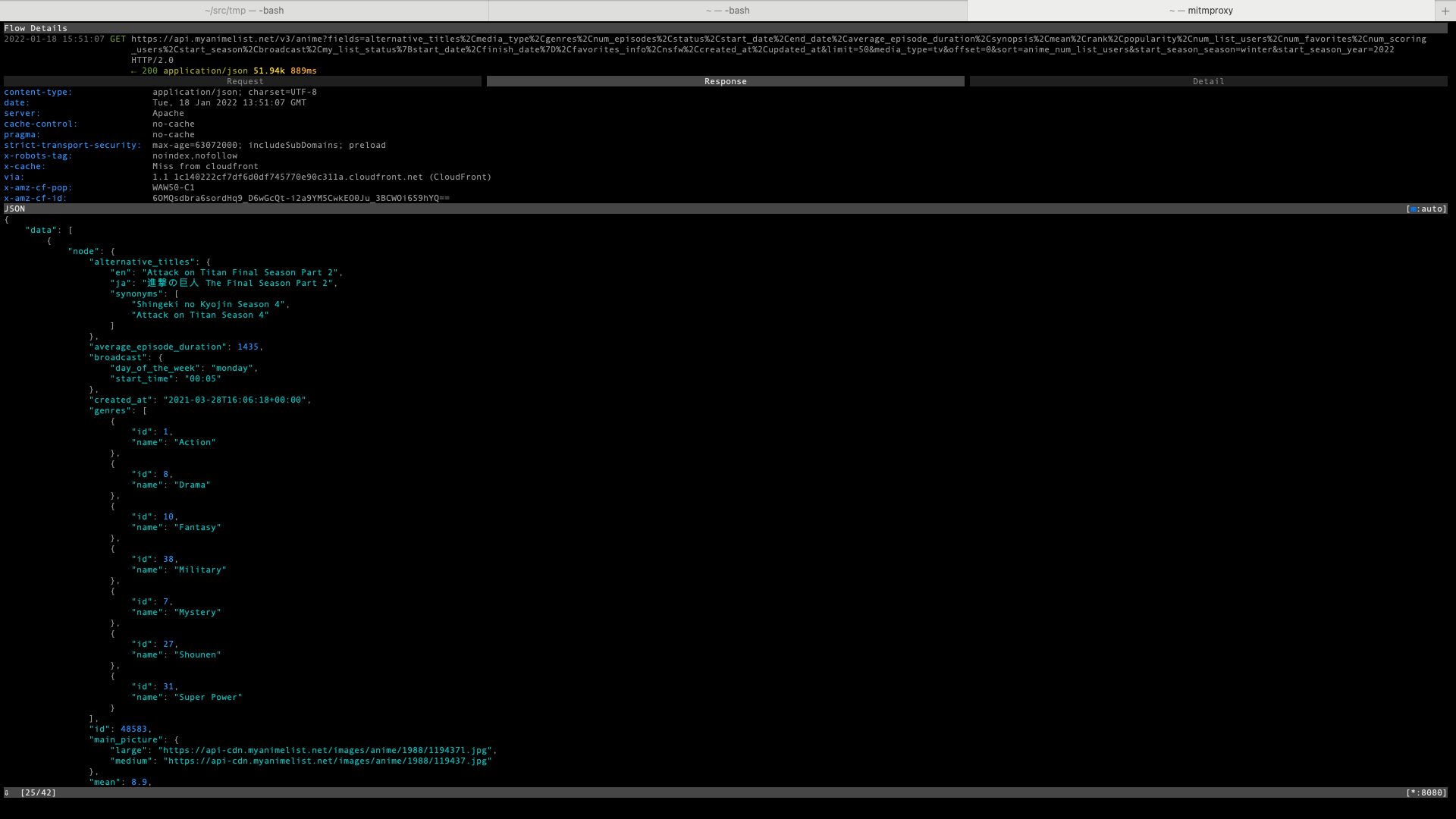{kind=link}
We discover that data about currently airing anime TV series is loaded via the following API request:
GET https://api.myanimelist.net/v3/anime?fields=alternative_titles%2Cmedia_type%2Cgenres%2Cnum_episodes%2Cstatus%2Cstart_date%2Cend_date%2Caverage_episode_duration%2Csynopsis%2Cmean%2Crank%2Cpopularity%2Cnum_list_users%2Cnum_favorites%2Cnum_scoring_users%2Cstart_season%2Cbroadcast%2Cmy_list_status%7Bstart_date%2Cfinish_date%7D%2Cfavorites_info%2Cnsfw%2Ccreated_at%2Cupdated_at&limit=50&media_type=tv&offset=0&sort=anime_num_list_users&start_season_season=winter&start_season_year=2022 HTTP/2.0
accept: application/json
x-mal-client-id: 6591a087c62b3e94d769cd8e35ffe909
cache-control: public, max-age=60
user-agent: MAL (ios, 139)
accept-language: en-GB,en;q=0.9
accept-encoding: gzip, deflate, br
content-length: 0
Let us discuss what we see here. This is a rather straightforward call to RESTful API that asks for a JSON response that can be
compressed. User-Agent header is custom to the app. x-mal-client-id seems to be an API key that is hardcoded into the app
and that we will be reusing in our script. The API call is to /v3/anime endpoint with a bunch of URL parameters narrowing down the
exact data the app wants to receive. Notably, it has start_season_season parameter with the value winter and start_season_year
parameter with the value 2022. We don’t want to hardcode these parameters and will be looking into earlier API calls to see
where the app gets these from.
Luckily for us, the app makes the following request that gets a JSON response with a list of seasons, one of which is marked as current.
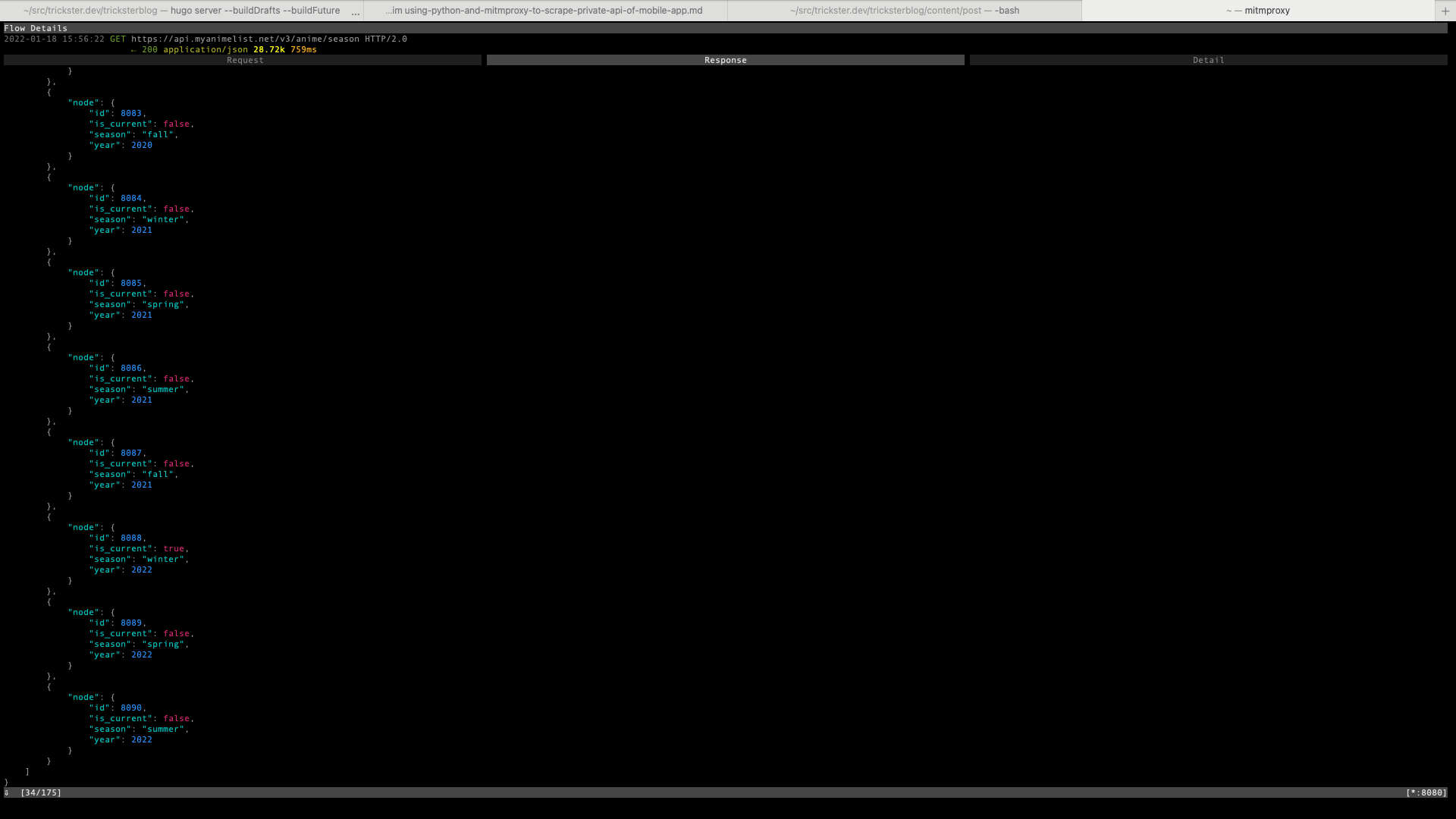{kind=link}
GET https://api.myanimelist.net/v3/anime/season HTTP/2.0
accept: */*
x-mal-client-id: 6591a087c62b3e94d769cd8e35ffe909
cache-control: public, max-age=60
user-agent: MAL (ios, 139)
accept-language: en-GB,en;q=0.9
accept-encoding: gzip, deflate, br
content-length: 0
Now, let us export curl(1) snippets for both of these requests and use curlconverter to convert them to Python snippets.
mitmproxy gives us the following snippet to reproduce the early API call that gets a list of seasons:
curl -H 'accept: */*' -H 'x-mal-client-id: 6591a087c62b3e94d769cd8e35ffe909' -H 'cache-control: public, max-age=60' -H 'user-agent: MAL (ios, 139)' -H 'accept-language: en-GB,en;q=0.9' --compressed https://api.myanimelist.net/v3/anime/season
Curlconverter converts it to the following Python snippet;
import requests
headers = {
'accept': '*/*',
'x-mal-client-id': '6591a087c62b3e94d769cd8e35ffe909',
'cache-control': 'public, max-age=60',
'user-agent': 'MAL (ios, 139)',
'accept-language': 'en-GB,en;q=0.9',
}
response = requests.get('https://api.myanimelist.net/v3/anime/season', headers=headers)
Curl snippet to get list of ongoing anime TV shows is as follows:
curl -H 'accept: application/json' -H 'x-mal-client-id: 6591a087c62b3e94d769cd8e35ffe909' -H 'cache-control: public, max-age=60' -H 'user-agent: MAL (ios, 139)' -H 'accept-language: en-GB,en;q=0.9' --compressed 'https://api.myanimelist.net/v3/anime?fields=alternative_titles%2Cmedia_type%2Cgenres%2Cnum_episodes%2Cstatus%2Cstart_date%2Cend_date%2Caverage_episode_duration%2Csynopsis%2Cmean%2Crank%2Cpopularity%2Cnum_list_users%2Cnum_favorites%2Cnum_scoring_users%2Cstart_season%2Cbroadcast%2Cmy_list_status%7Bstart_date%2Cfinish_date%7D%2Cfavorites_info%2Cnsfw%2Ccreated_at%2Cupdated_at&limit=50&media_type=tv&offset=0&sort=anime_num_list_users&start_season_season=winter&start_season_year=2022'
Corresponding Python snippet:
import requests
headers = {
'accept': 'application/json',
'x-mal-client-id': '6591a087c62b3e94d769cd8e35ffe909',
'cache-control': 'public, max-age=60',
'user-agent': 'MAL (ios, 139)',
'accept-language': 'en-GB,en;q=0.9',
}
params = (
('fields', 'alternative_titles,media_type,genres,num_episodes,status,start_date,end_date,average_episode_duration,synopsis,mean,rank,popularity,num_list_users,num_favorites,num_scoring_users,start_season,broadcast,my_list_status{start_date,finish_date},favorites_info,nsfw,created_at,updated_at'),
('limit', '50'),
('media_type', 'tv'),
('offset', '0'),
('sort', 'anime_num_list_users'),
('start_season_season', 'winter'),
('start_season_year', '2022'),
)
response = requests.get('https://api.myanimelist.net/v3/anime', headers=headers, params=params)
#NB. Original query string below. It seems impossible to parse and
#reproduce query strings 100% accurately so the one below is given
#in case the reproduced version is not "correct".
# response = requests.get('https://api.myanimelist.net/v3/anime?fields=alternative_titles%2Cmedia_type%2Cgenres%2Cnum_episodes%2Cstatus%2Cstart_date%2Cend_date%2Caverage_episode_duration%2Csynopsis%2Cmean%2Crank%2Cpopularity%2Cnum_list_users%2Cnum_favorites%2Cnum_scoring_users%2Cstart_season%2Cbroadcast%2Cmy_list_status%7Bstart_date%2Cfinish_date%7D%2Cfavorites_info%2Cnsfw%2Ccreated_at%2Cupdated_at&limit=50&media_type=tv&offset=0&sort=anime_num_list_users&start_season_season=winter&start_season_year=2022', headers=headers)
Now we have the building blocks ready to write a Python script that reproduces both API calls, parses JSON responses, extracts the data fields we are interested in, and saves them into CSV file. Take a look at the following code.
#!/usr/bin/python3
import csv
from pprint import pprint
import requests
FIELDNAMES = ["title", "synopsis", "status", "genres", "mean"]
def main():
out_f = open("cur_season.csv", "w", encoding="utf-8")
csv_writer = csv.DictWriter(out_f, fieldnames=FIELDNAMES, lineterminator="\n")
csv_writer.writeheader()
headers = {
"accept": "*/*",
"x-mal-client-id": "6591a087c62b3e94d769cd8e35ffe909",
"cache-control": "public, max-age=60",
"user-agent": "MAL (ios, 139)",
"accept-language": "en-GB,en;q=0.9",
}
resp1 = requests.get("https://api.myanimelist.net/v3/anime/season", headers=headers)
print(resp1.url)
json_dict = resp1.json()
season = None
year = None
for season_dict in json_dict.get("data", []):
node_dict = season_dict.get("node", dict())
if node_dict.get("is_current"):
season = node_dict.get("season")
year = node_dict.get("year")
break
params = {
"fields": "alternative_titles,media_type,genres,num_episodes,status,start_date,end_date,average_episode_duration,synopsis,mean,rank,popularity,num_list_users,num_favorites,num_scoring_users,start_season,broadcast,my_list_status{start_date,finish_date},favorites_info,nsfw,created_at,updated_at",
"limit": "50",
"media_type": "tv",
"offset": "0",
"sort": "anime_num_list_users",
"start_season_season": season,
"start_season_year": str(year),
}
resp2 = requests.get(
"https://api.myanimelist.net/v3/anime", headers=headers, params=params
)
print(resp2.url)
json_dict = resp2.json()
for show_dict in json_dict.get("data", []):
node_dict = show_dict.get("node", dict())
if node_dict.get("genres") is not None:
genres = list(map(lambda g: g.get("name"), node_dict.get("genres")))
else:
genres = []
row = {
"title": node_dict.get("title"),
"synopsis": node_dict.get("synopsis", "").replace("\n", " "),
"status": node_dict.get("status"),
"genres": ",".join(genres),
"mean": node_dict.get("mean"),
}
pprint(row)
csv_writer.writerow(row)
out_f.close()
if __name__ == "__main__":
main()
Resulting CSV file opened in LibreOffice
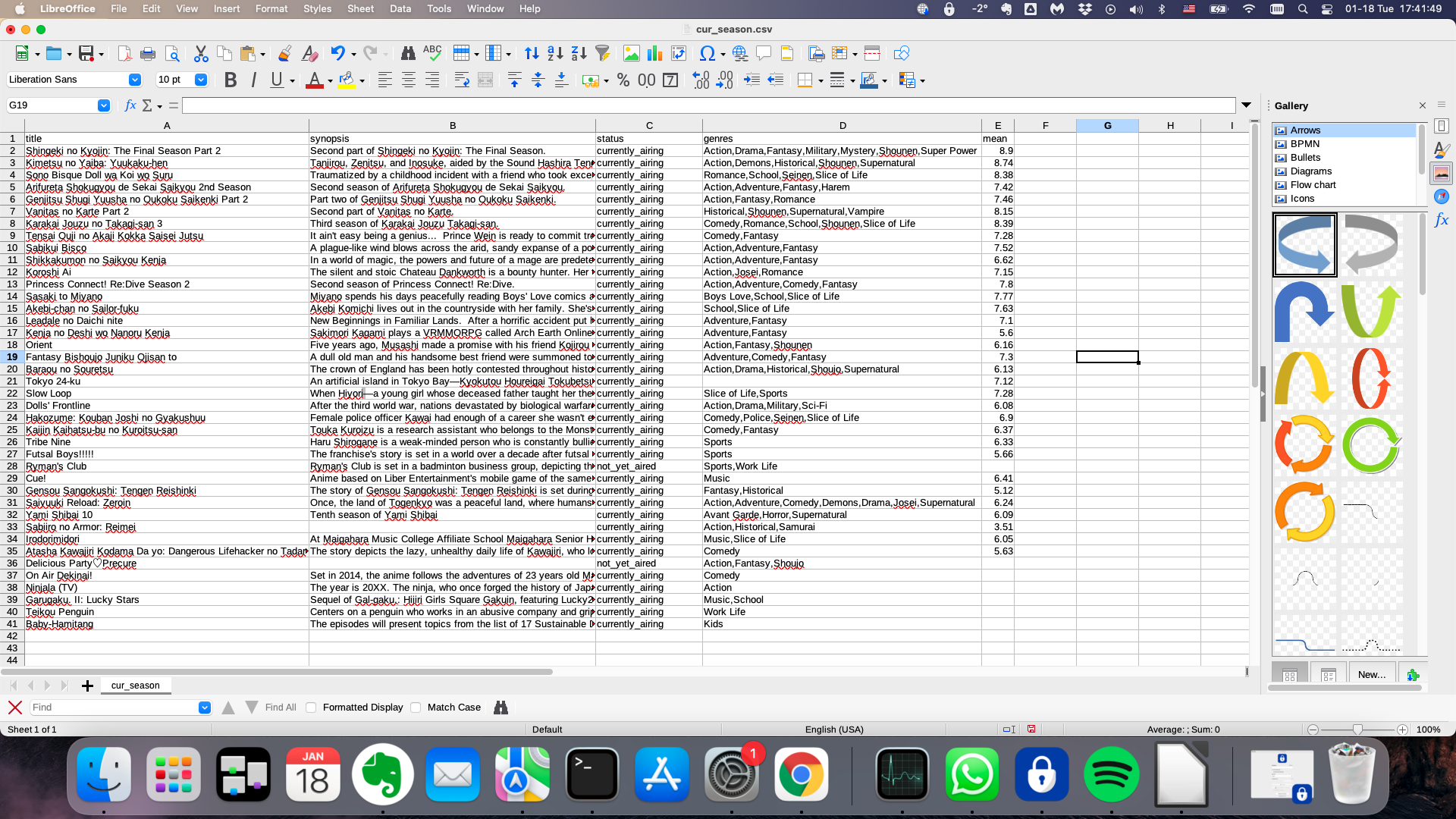{kind=link}
Could the very same information be scraped from the website? Of course. However, we were able to get it from mobile app backend in a pre-structured way which is not always easy when scraping the website. Furthermore, the approach we are using in this example is widely applicable to many mobile apps even if they don’t have a corresponding website and can be further extended into automating actions that the user would otherwise be doing manually. Some applications attempt to prevent API scraping by implementing X.509 certificate pinning, but there are ways to defeat it.