First thing that happens when a program source code is parsed by compiler or interpreter is tokenization - cutting of code into substrings that are later organised into parse tree. However, this tree structure merely represents textual structure of the code. Further step is syntactic analysis - an activity of converting parse tree (also known as CST - concrete syntax tree) into another tree structure that represent logical (not textual) structure. This new tree structure that emerges from syntactic analysis is known as Abstract Syntax Tree (AST). AST is then further processed to yield some form of executable code, possibly with some optimizations being applied on the way.
AST represents code in terms of it’s logical building blocks and their relations to each other. Program/module is topmost node that has nodes representing expression statements, functions calls, variable declarations and many other things that collectively represent the code that was parsed.
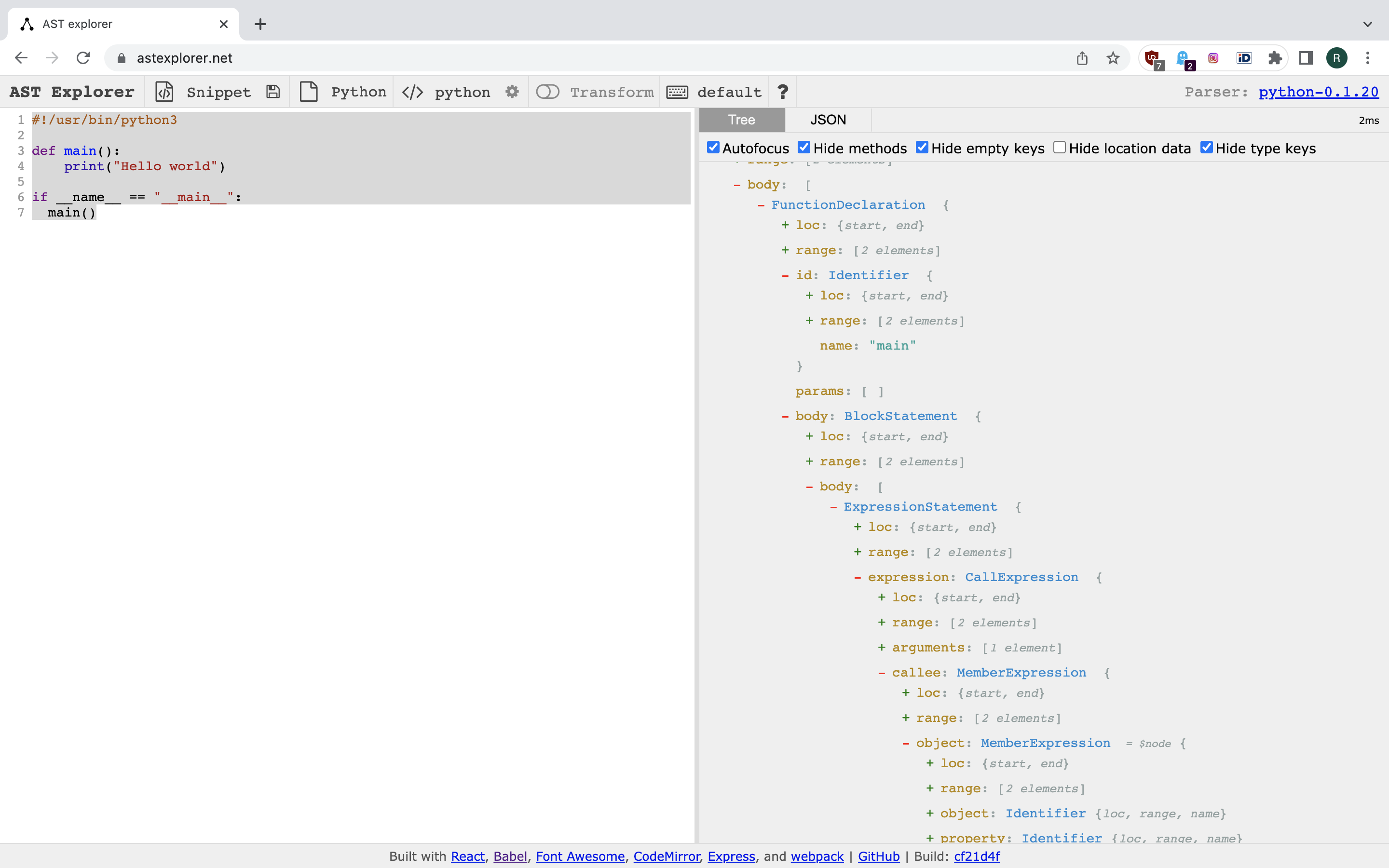
One way to see what ASTs are like is to play with ASTExplorer web app. For example, we can choose Python and put some Hello World example into code editor:
#!/usr/bin/python3
def main():
print("Hello world")
if __name__ == "__main__":
main()
By exploring the AST viewer on the right hand side we can see that main() function is
represented by FunctionDeclaration node with two children: Identifier holding the name
for the function and BlockStatement at property body. BlockStatement also has a body
property with an array holding a single ExpressionStatement node that points to some further
descendant nodes. I encourage everyone to play around with AST explorer to see what ASTs look like
for various programming languages. You will find that there is no single AST format out there
and that it can differ based on tooling even if the programming language is the same. However
all ASTs have top-down structure to them: at the top there is program/module/document node
that is being divided into smaller components as the tree goes deeper. Document formats
like HTML and JSON can also be parsed into Abstract Syntax Trees.
{kind=link}
We can also save the code into file named hello.py and try printing the AST with an
ast module from vanilla Python
distribution:
$ python -m ast hello.py
Module(
body=[
FunctionDef(
name='main',
args=arguments(
posonlyargs=[],
args=[],
kwonlyargs=[],
kw_defaults=[],
defaults=[]),
body=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[
Constant(value='Hello world')],
keywords=[]))],
decorator_list=[]),
If(
test=Compare(
left=Name(id='__name__', ctx=Load()),
ops=[
Eq()],
comparators=[
Constant(value='__main__')]),
body=[
Expr(
value=Call(
func=Name(id='main', ctx=Load()),
args=[],
keywords=[]))],
orelse=[])],
type_ignores=[])
LLVM tooling can also dump AST for the supported programming languages. For this example, let us implement Hello World in C:
#include <stdio.h>
int main(int argc, char **argv) {
(void)argc;
(void)argv;
printf("Hello, world!\n");
return 0;
}
Command to dump the AST would be the following:
$ clang -Xclang -ast-dump -fsyntax-only hello.c
Since we included stdio.h at the top it gets parsed as well, thus producing a fairly excessive amount of output. The code we wrote ourselves would be represented at the bottom of the output:
`-FunctionDecl 0x7fbc89941f60 <hello.c:3:1, line:10:1> line:3:5 main 'int (int, char **)'
|-ParmVarDecl 0x7fbc89941e00 <col:10, col:14> col:14 used argc 'int'
|-ParmVarDecl 0x7fbc89941e80 <col:20, col:27> col:27 used argv 'char **'
`-CompoundStmt 0x7fbc89942260 <col:33, line:10:1>
|-CStyleCastExpr 0x7fbc89942058 <line:4:3, col:9> 'void' <ToVoid>
| `-ImplicitCastExpr 0x7fbc89942040 <col:9> 'int' <LValueToRValue> part_of_explicit_cast
| `-DeclRefExpr 0x7fbc89942010 <col:9> 'int' lvalue ParmVar 0x7fbc89941e00 'argc' 'int'
|-CStyleCastExpr 0x7fbc899420c8 <line:5:3, col:9> 'void' <ToVoid>
| `-ImplicitCastExpr 0x7fbc899420b0 <col:9> 'char **' <LValueToRValue> part_of_explicit_cast
| `-DeclRefExpr 0x7fbc89942080 <col:9> 'char **' lvalue ParmVar 0x7fbc89941e80 'argv' 'char **'
|-CallExpr 0x7fbc899421d8 <line:7:3, col:27> 'int'
| |-ImplicitCastExpr 0x7fbc899421c0 <col:3> 'int (*)(const char *, ...)' <FunctionToPointerDecay>
| | `-DeclRefExpr 0x7fbc899420f0 <col:3> 'int (const char *, ...)' Function 0x7fbc89926548 'printf' 'int (const char *, ...)'
| `-ImplicitCastExpr 0x7fbc89942218 <col:10> 'const char *' <NoOp>
| `-ImplicitCastExpr 0x7fbc89942200 <col:10> 'char *' <ArrayToPointerDecay>
| `-StringLiteral 0x7fbc89942148 <col:10> 'char [15]' lvalue "Hello, world!\n"
`-ReturnStmt 0x7fbc89942250 <line:9:3, col:10>
`-IntegerLiteral 0x7fbc89942230 <col:10> 'int' 0
Beyond compilation, what are ASTs used for? Many developer tools rely on ASTs to implement things like linting, automatic refactoring, vulnerability detection and code obfuscation. Some open source license compliance tools perform AST-level checking to detect code reuse even if some variable names have been changed.
So if code is obfuscated by manipulating the AST, can it work the other way around? If we have some obfuscated JavaScript file that implements some countermeasures against automation (e.g. PerimeterX JS SDK) can we parse it into AST, then manipulate the AST to undo the obfuscations and regenerate JS code in more readable form? Turns out, that is possible and being done by developers working on advanced scraping/automation projects (e.g. sneaker bots and advanced proxy pools). This makes AST manipulation a valuable skill and a differentiator in scraping/automation market. Furthermore, undoing JS code obfuscation is also valuable for bug bounty hunting, as one may find things like API endpoints and credentials being hardcoded in the obfuscated code that nobody is supposed to read.