Yelp is a major yellow pages portal in USA and some other countries. It provides large amount of data on various businesses - phone numbers, addresses, descriptions, reviews, working hours and so on. Yelp provides a public API, but it is rate-limited to 500 requests per 24 hours. Thus we will be doing some web scraping to extract data from Yelp web pages.
Let us do some planning and strategy work first. This entails browsing the page with Chrome DevTools open, taking some notes and also loading some pages via Scrapy shell, e.g:
$ scrapy shell "https://www.yelp.com/search?find_desc=Pizza&find_loc=San+Francisco%2C+CA%2C+United+States"
2023-08-11 14:06:14 [scrapy.utils.log] INFO: Scrapy 2.8.0 started (bot: scrapybot)
2023-08-11 14:06:14 [scrapy.utils.log] INFO: Versions: lxml 4.9.2.0, libxml2 2.9.13, cssselect 1.2.0, parsel 1.7.0, w3lib 2.1.1, Twisted 22.10.0, Python 3.11.4 (main, Jun 20 2023, 17:23:00) [Clang 14.0.3 (clang-1403.0.22.14.1)], pyOpenSSL 23.1.1 (OpenSSL 3.1.0 14 Mar 2023), cryptography 40.0.1, Platform macOS-13.3.1-arm64-arm-64bit
2023-08-11 14:06:14 [scrapy.crawler] INFO: Overridden settings:
{'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter',
'LOGSTATS_INTERVAL': 0}
2023-08-11 14:06:14 [py.warnings] WARNING: /opt/homebrew/lib/python3.11/site-packages/scrapy/utils/request.py:232: ScrapyDeprecationWarning: '2.6' is a deprecated value for the 'REQUEST_FINGERPRINTER_IMPLEMENTATION' setting.
It is also the default value. In other words, it is normal to get this warning if you have not defined a value for the 'REQUEST_FINGERPRINTER_IMPLEMENTATION' setting. This is so for backward compatibility reasons, but it will change in a future version of Scrapy.
See the documentation of the 'REQUEST_FINGERPRINTER_IMPLEMENTATION' setting for information on how to handle this deprecation.
return cls(crawler)
2023-08-11 14:06:14 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2023-08-11 14:06:14 [scrapy.extensions.telnet] INFO: Telnet Password: 20481848a3d75456
2023-08-11 14:06:14 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage']
2023-08-11 14:06:15 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2023-08-11 14:06:15 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2023-08-11 14:06:15 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2023-08-11 14:06:15 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2023-08-11 14:06:15 [scrapy.core.engine] INFO: Spider opened
2023-08-11 14:06:17 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.yelp.com/search?find_desc=Pizza&find_loc=San+Francisco%2C+CA%2C+United+States> (referer: None)
2023-08-11 14:06:17 [asyncio] DEBUG: Using selector: KqueueSelector
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x107083e10>
[s] item {}
[s] request <GET https://www.yelp.com/search?find_desc=Pizza&find_loc=San+Francisco%2C+CA%2C+United+States>
[s] response <200 https://www.yelp.com/search?find_desc=Pizza&find_loc=San+Francisco%2C+CA%2C+United+States>
[s] settings <scrapy.settings.Settings object at 0x106213ed0>
[s] spider <DefaultSpider 'default' at 0x108044bd0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
2023-08-11 14:06:17 [asyncio] DEBUG: Using selector: KqueueSelector
Note the sucessfull request here - it means we’re not blocked by any security mechanism (yet).
{kind=link}
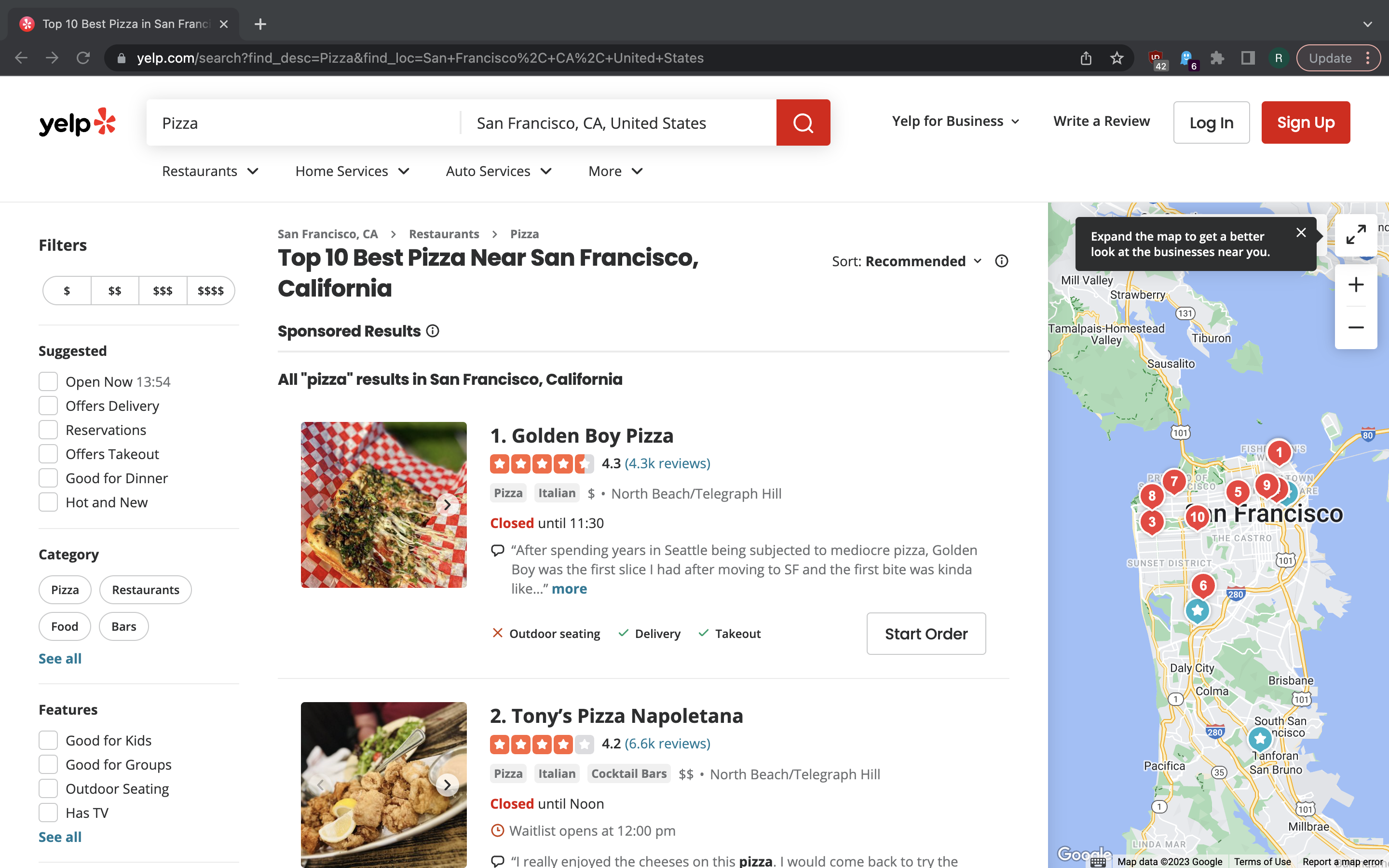
Like many other websites in yellow pages world, Yelp has search feature with pagination and links to company detail pages. There’s also a map on he right hand side. If we wanted to get the map annotation coordinates we could extract them from JSON that is cooked into the page source. Yelp frontend is API-driven to a degree, but we can load the full HTML for each page. In this example, we will be running XPath queries on the pages downloaded by Scrapy.
For example, we can extract links to company detail pages like this:
In [1]: response.xpath('//a[starts-with(@href, "/biz/")]/@href').getall()
Out[1]:
['/biz/golden-boy-pizza-san-francisco?osq=Pizza',
'/biz/golden-boy-pizza-san-francisco?osq=Pizza',
'/biz/golden-boy-pizza-san-francisco?hrid=QySEJtXN3DGb0KEVAmxF6w&osq=Pizza',
'/biz/golden-boy-pizza-san-francisco?hrid=QySEJtXN3DGb0KEVAmxF6w&osq=Pizza',
'/biz/golden-boy-pizza-san-francisco?hrid=QySEJtXN3DGb0KEVAmxF6w&osq=Pizza',
'/biz/golden-boy-pizza-san-francisco?hrid=QySEJtXN3DGb0KEVAmxF6w&osq=Pizza',
'/biz/PTFxtXS47ZVRCdZIrEWvGw?show_platform_modal=True',
'/biz/tonys-pizza-napoletana-san-francisco?osq=Pizza',
'/biz/tonys-pizza-napoletana-san-francisco?osq=Pizza',
...
The XPath query here is based on company page URL path always starting with
/biz/. We see some duplication here, but that’s not going to be a problem
as Scrapy will deduplicate the requests for us.
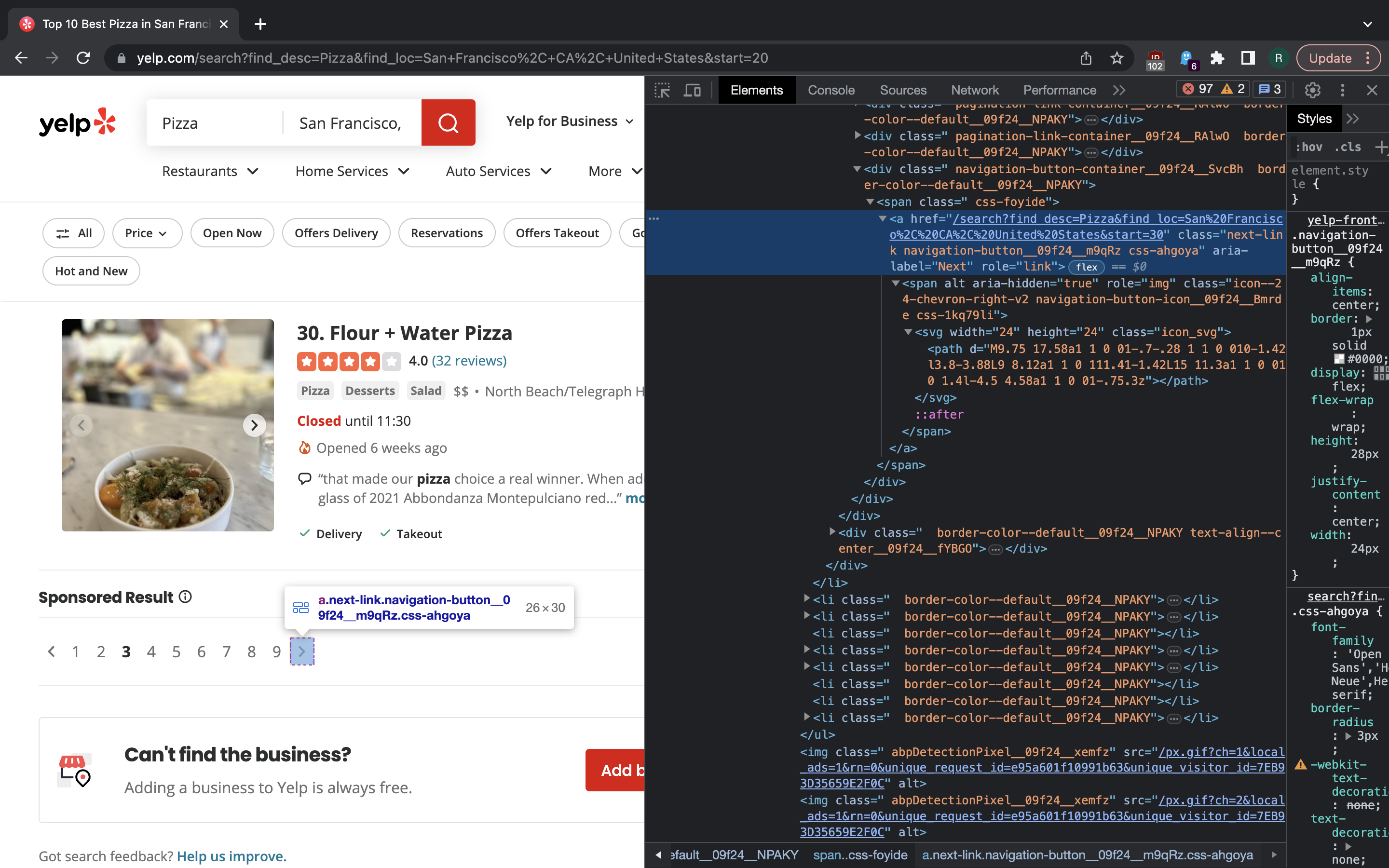
We also need a link to next page of search results. That can be extracted from
“>” element that we can match by aria-label being set to Next. The XPath
query here is also rather simple:
In [2]: response.xpath('//a[@aria-label="Next"]/@href').get()
Out[2]: 'https://www.yelp.com/search?find_desc=Pizza&find_loc=San%20Francisco%2C%20CA%2C%20United%20States&start=10'
{kind=link}
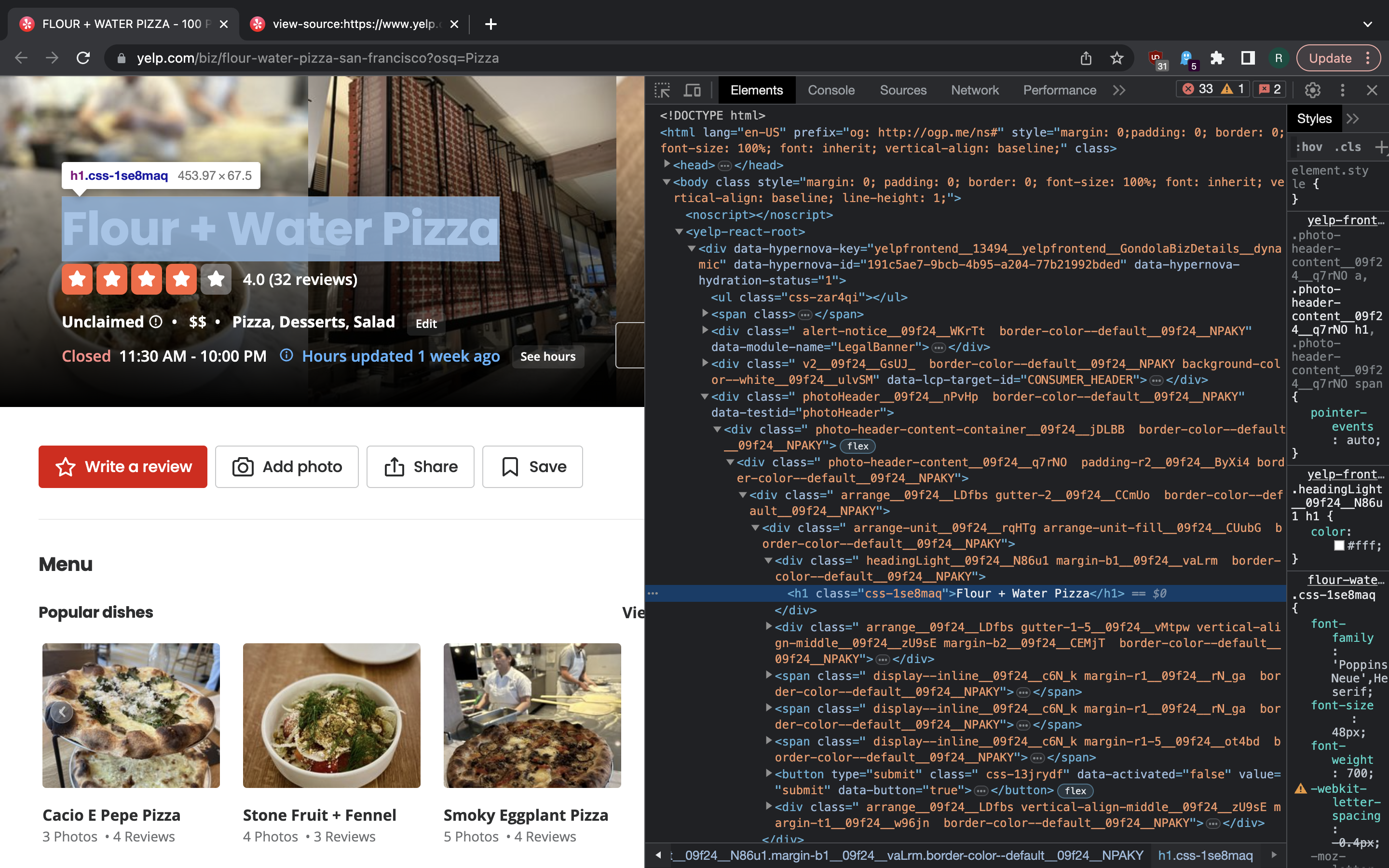
Now we can explore the company details page. Let us also load it in Scrapy shell:
In [3]: fetch("https://www.yelp.com/biz/flour-water-pizza-san-francisco?osq=Pizza")
2023-08-11 14:24:22 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.yelp.com/biz/flour-water-pizza-san-francisco?osq=Pizza> (referer: None)
Again, we get a fairly simple case of HTML being created on the server with not much done on the client side to render the data. Thus we can also run some simple XPath queries here to extract some information on the company:
In [4]: response.xpath("//h1/text()").get()
Out[4]: 'Flour + Water Pizza'
In [5]: response.xpath('//div[./p/a[text()="Get Directions"]]/p[last()]/text()').get()
Out[5]: '532 Columbus Ave San Francisco, CA 94133'
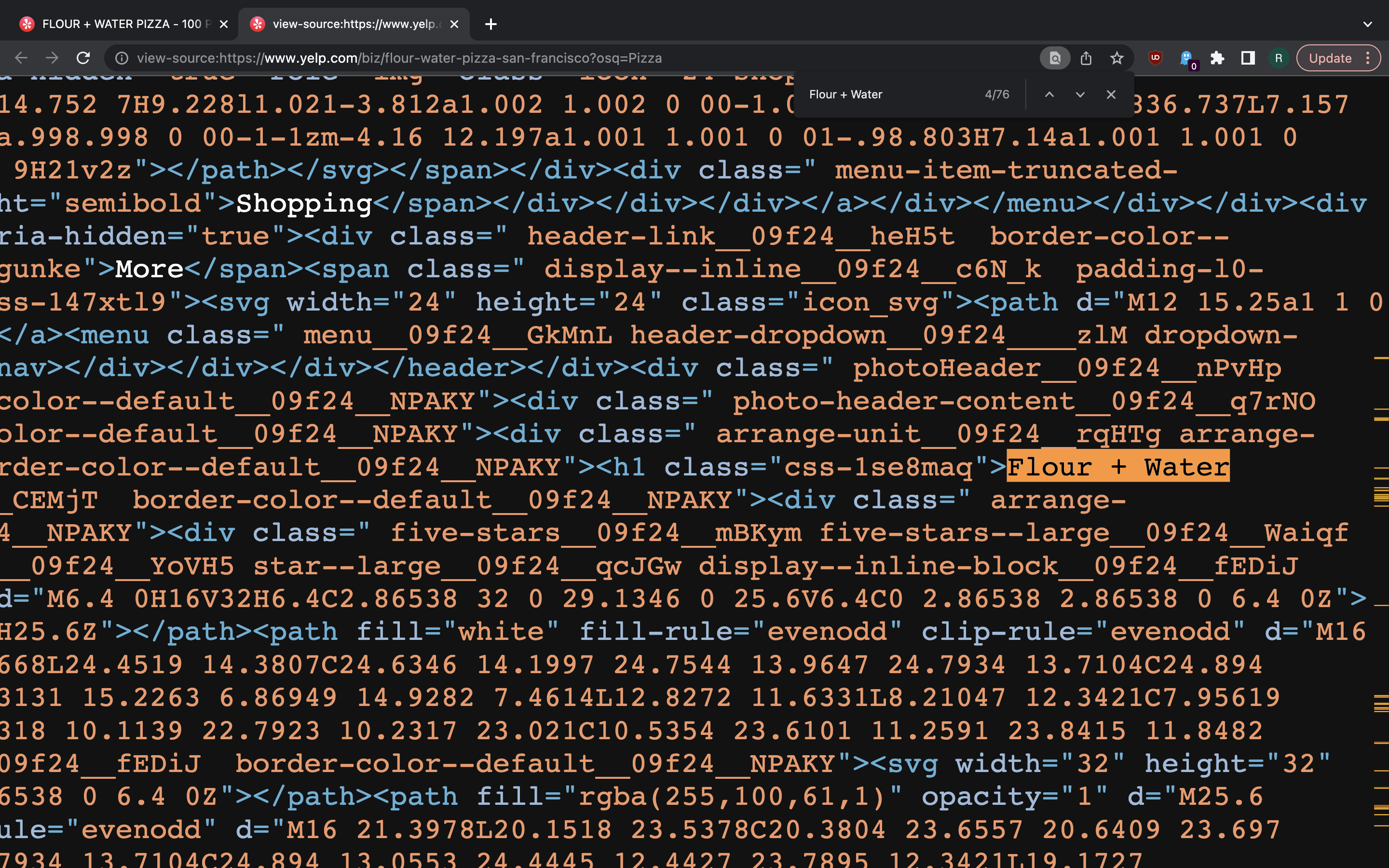
In [6]: response.xpath('//img[contains(@src, "maps.googleapis.com")]/@src').get()
Out[6]: 'https://maps.googleapis.com/maps/api/staticmap?size=315x150&sensor=false&client=gme-yelp&language=en&scale=1&zoom=15¢er=37.800084%2C-122.409429&markers=scale%3A1%7Cicon%3Ahttps%3A%2F%2Fyelp-images.s3.amazonaws.com%2Fassets%2Fmap-markers%2Fannotation_32x43.png%7C37.800084%2C-122.409429&signature=IGF-J6T8eel638VQaoUG3pY1BtA='
{kind=link}
{kind=link}
The little map from Google Maps is not interactive. It’s a static image generated
by Google Maps API. The URL usually (but not always) has a center parameter
with company location coordinates. In some cases this little map shows the
service coverage area. We will be extracting company coordinates from the image
source URL when possible.
{kind=link}
We run the following two commands to generate a Scrapy project with spider boilerplate:
$ scrapy startproject recon .
$ scrapy genspider yelp yelp.com
We edit items.py file to create an item class for data we scrape from Yelp company page:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class YelpItem(scrapy.Item):
# define the fields for your item here like:
yelp_biz_id = scrapy.Field()
category = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
phone_number = scrapy.Field()
website = scrapy.Field()
address = scrapy.Field()
latitude = scrapy.Field()
longitude = scrapy.Field()
gmaps_img_url = scrapy.Field()
yelp_url = scrapy.Field()
We got the usual fields here - company name, address, phone number, address website URL and so on. We also include the URL to page we scrape to enable checks on the scraped data.
The Scrapy spider code in yelp.py file is as follows:
import scrapy
from urllib.parse import urlencode, urlparse, parse_qsl
from recon.items import YelpItem
class YelpSpider(scrapy.Spider):
name = "yelp"
allowed_domains = ["yelp.com"]
start_urls = ["http://yelp.com/"]
locations = None
queries = None
def __init__(self, locations="United States", queries="Pizza|Coffee"):
super().__init__()
self.locations = locations.split("|")
self.queries = queries.split("|")
def start_requests(self):
for location in self.locations:
for query in self.queries:
url = "https://www.yelp.com/search"
params = {"find_desc": query, "find_loc": location}
url = url + "?" + urlencode(params)
yield scrapy.Request(
url, callback=self.parse_company_list, meta={"category": query}
)
def parse_company_list(self, response):
category = response.meta.get("category")
company_links = response.xpath(
'//a[starts-with(@href, "/biz/")]/@href'
).getall()
company_links = list(map(lambda cl: cl.split("?")[0], company_links))
company_links = list(set(company_links))
for company_link in company_links:
yield response.follow(
company_link,
callback=self.parse_company_details,
meta={"category": category},
)
next_page_url = response.xpath('//a[@aria-label="Next"]/@href').get()
if next_page_url is not None:
yield scrapy.Request(
next_page_url,
callback=self.parse_company_list,
meta={"category": category},
)
def parse_company_details(self, response):
category = response.meta.get("category")
item = YelpItem()
item["category"] = category
item["yelp_biz_id"] = response.xpath(
'//meta[@name="yelp-biz-id"]/@content'
).get()
item["name"] = response.xpath("//h1/text()").get()
item["description"] = response.xpath(
'//meta[@property="og:description"]/@content'
).get()
if item["description"] is not None:
item["description"] = item["description"].replace("\n", " ").strip()
item["phone_number"] = response.xpath(
'//div[./p[text()="Phone number"]]/p[last()]/text()'
).get()
item["website"] = response.xpath(
'//div[./p[text()="Business website"]]/p[last()]/a/@href'
).get()
if item["website"] is not None and item["website"].startswith("/biz_redir"):
o = urlparse(item["website"])
params = parse_qsl(o.query)
params = dict(params)
item["website"] = params.get("url")
item["address"] = response.xpath(
'//div[./p/a[text()="Get Directions"]]/p[last()]/text()'
).get()
gmaps_img_url = response.xpath(
'//img[contains(@src, "maps.googleapis.com")]/@src'
).get()
o = urlparse(gmaps_img_url)
gmaps_params = parse_qsl(o.query)
gmaps_params = dict(gmaps_params)
self.logger.debug(gmaps_params)
center = gmaps_params.get("center")
if center is None:
try:
center = gmaps_params.get("markers").split("|")[-1]
except:
pass
if center is not None:
latitude, longitude = center.split(",")
item["latitude"] = latitude
item["longitude"] = longitude
item["gmaps_img_url"] = gmaps_img_url
item["yelp_url"] = response.url
yield item
This spider is parametrised by location(s) and search queries that can be
passed via CLI. Since both can include commas in their values we expect the
user to use pipe symbol as separator. This aspect is accomplished in the
constructor method (__init__). Note that Yelp limits the amount of search
results per query-location pair, which makes search space sharding potentially
applicable here.
In start_requests(), a standard Scrapy spider method, we iterate across
both values of both parameters in nested loops to generate requests to
initial search pages. We pass parse_company_list() as callback to request.
When Scrapy fetches the page, it calls this method to parse it. At this
callback, we do the following:
- We extract company page links (relative URLs) and generate requests to get
them. This time callback is another method -
parse_company_details. - We extract the URL of next search page if there is one and generate a request to it. Since it will be the same kind of page with company links, the callback is the same.
We use the meta dictionary to pass the original search query along the
request flow, as we want to preserve it in the scraped data item. Commonly
the query is a business category. That’s why we name it as such.
In the parse_company_details method we apply XPath queries based on the
page structure to extract the data we need. We already discussed a small
complication with coordinates, but there’s also something we need to do
about the website URL. To track clicks to the company website, Yelp links it
through a redirect. Thus we use urlparse and parse_qsl functions from
urllib.parse
module to get a clean, direct URL. The code to extract rest of the fields is
rather straightforward and trivially based on DOM structure. If the XPath
queries look puzzling to you please read an earlier post on
the very basics of XPath.
But there’s a little problem we have not addressed yet. Yelp does not have any agressive countermeasures deployed and it does not use any commercial solutions against scraping, but it does one annoying thing - temporary IP bans on excessive traffic. Thus we need some proxies here. I find that DC proxies are enough, but it’s best to force exit IP randomisation (e.g. rotating the proxy pool exit on every request). This is implemented in the following Scrapy middleware:
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from recon.settings import (
BRIGHT_DATA_ENABLED,
BRIGHT_DATA_ZONE_USERNAME,
BRIGHT_DATA_ZONE_PASSWORD,
)
from w3lib.http import basic_auth_header
import random
class BrightDataDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
return cls()
def process_request(self, request, spider):
if not BRIGHT_DATA_ENABLED:
return None
request.meta["proxy"] = "http://brd.superproxy.io:22225"
username = BRIGHT_DATA_ZONE_USERNAME + "-session-" + str(random.random())
request.headers["Proxy-Authorization"] = basic_auth_header(
username, BRIGHT_DATA_ZONE_PASSWORD
)
Since I use Bright Data, this entails a little vendor lock-in. This is updated
version of middleware code from the
previous post.
Note that -session- string and a random number is appended to proxy zone
username. This approach is based on sample code from Bright Data.
To integrate this middleware into the Scrapy project, we have to edit the settings.py file as follows:
BRIGHT_DATA_ENABLED = True
BRIGHT_DATA_ZONE_USERNAME = "[REDACTED]"
BRIGHT_DATA_ZONE_PASSWORD = "[REDACTED]"
DOWNLOADER_MIDDLEWARES = {"recon.middlewares.BrightDataDownloaderMiddleware": 500}
I also decided to raise CONCURRENT_REQUESTS and RETRY_TIMES to make the
scraping more agressive:
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
RETRY_TIMES = 10
This covers the possibility of some exit IPs getting blocked by allowing for more retries to be made. It also speeds up the scraping by doing more requests concurrently.
Lastly, I disabled cookie handling, because we don’t need cookies to scrape this site:
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
I could probably have left this on, but now I eliminate the possibility of cookies being used to cross-correlate requests to thwart or hinder the scraping.
So if we wanted to scrape data about coffee shops and pizza places in both San Francisco, CA and New York City we could run the Scrapy project like this:
$ scrapy runspider -a "locations=San Francisco, CA|New York, NY" \
-a "queries=pizza|coffee" recon/spiders/yelp.py -O yelp.csv