When looking into some targets for web scraping, you may come across pages
that contain a lot of data represented in JSON-like (but not quite JSON) format
passed to self.__next_f.push() Javascript function calls. What’s going on
here and how do we parse this stuff? To understand what this is about, we must
go through a little journey across the technological landscape of the modern
web. Note that I am not a frontend developer and don’t aspire to be. For the
most part, I extract data from web apps and web sites, not develop them. The
following is what I managed to understand from reading around.
So, it’s widely known that React is a very prominent frontend framework to develop web apps in JavaScript. Although one can develop web apps with the very basics - HTML, CSS and vanilla JavaScript, doing so is too simple for enterprise software teams and tech startups drunk on that sweet VC funding. They need more powerful abstractions, such as reusable components, UI state management, Virtual DOM to optimize performance by only redrawing parts of UI that changed and JSX syntax that extends Javascript language into Javascript-HTML hybrid dialect. More generally, React has emerged as a winner among many ZIRP-era Javascript frameworks by addressing the reactivity problem in web app development: how do we associate internal app state with visible UI stuff and how do we keep them in sync when one or the other changes.
Primarily React is only a frontend framework meant to develop code that runs in a browser. React alone cannot be used for full stack web development, as we also need something for the backend side of the app. To fill this gap, Next.js was developed. Next.js is another Javascript framework that works with React to provide features like request routing, performance optimization (e.g. making images smaller depending on the needs of frontend side) and Server Side Rendering (SSR). The latter will become important for our purposes in a moment. In addition to all of that, Next.js provides some tooling for easier deployment and nicer developer experience.
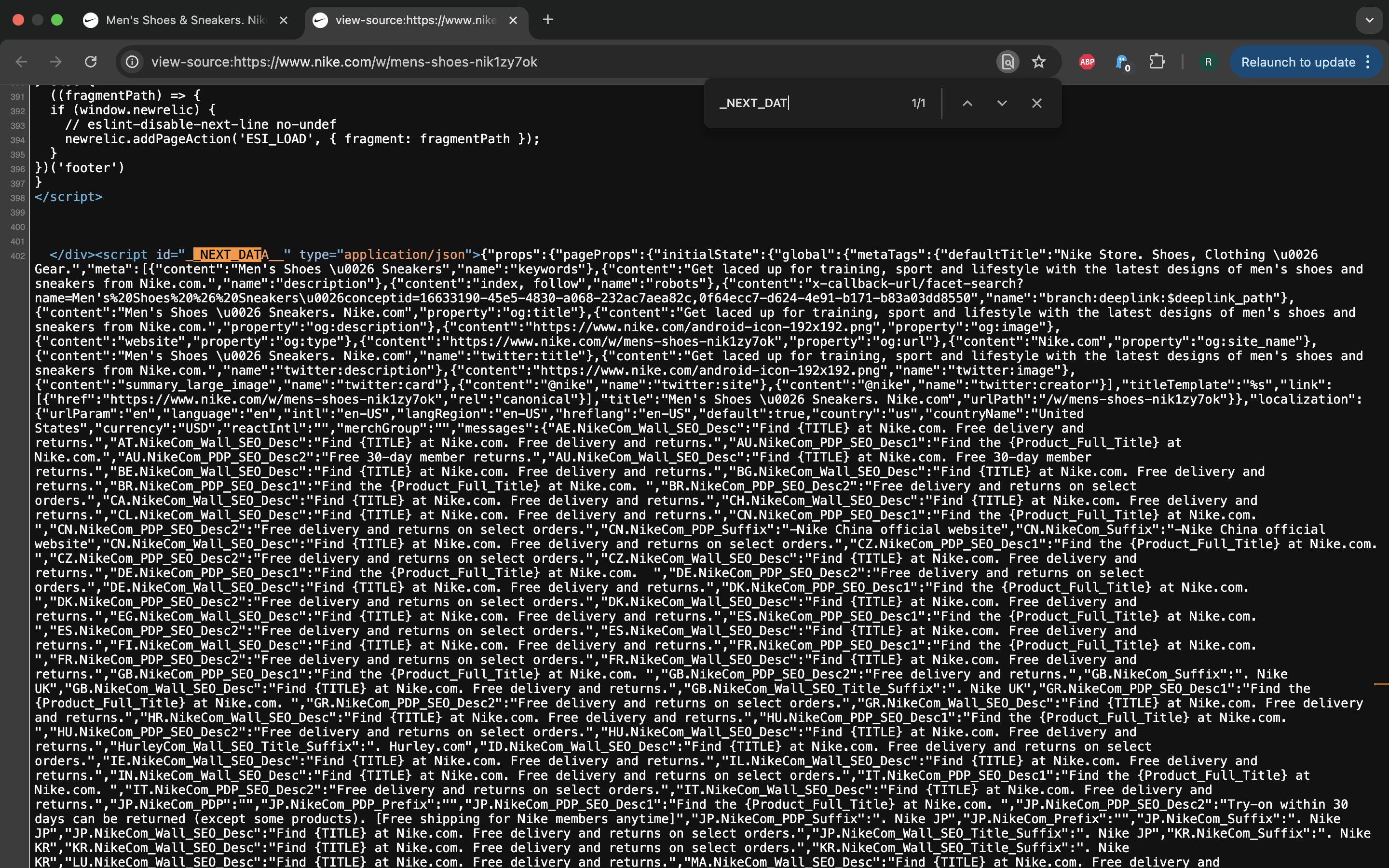
Those of us who work in web scraping have seen that many sites tend to have pages
with <script id="__NEXT_DATA__" type="application/json"> tag that contains
a large JSON document with all kinds of juicy data we can parse out of there.
This is related to concept called hydration - embedding data within HTML
document during server-side rendering so that it could be attached to React
data model when bootstrapping all the React client-side machinery that makes
the page interactive. For example, the first page of the product list is
fetched with this __NEXT_DATA__ shebang, but if you go to the next page of the
product list, REST API call will be initiated to fetch further data.
{kind=link}
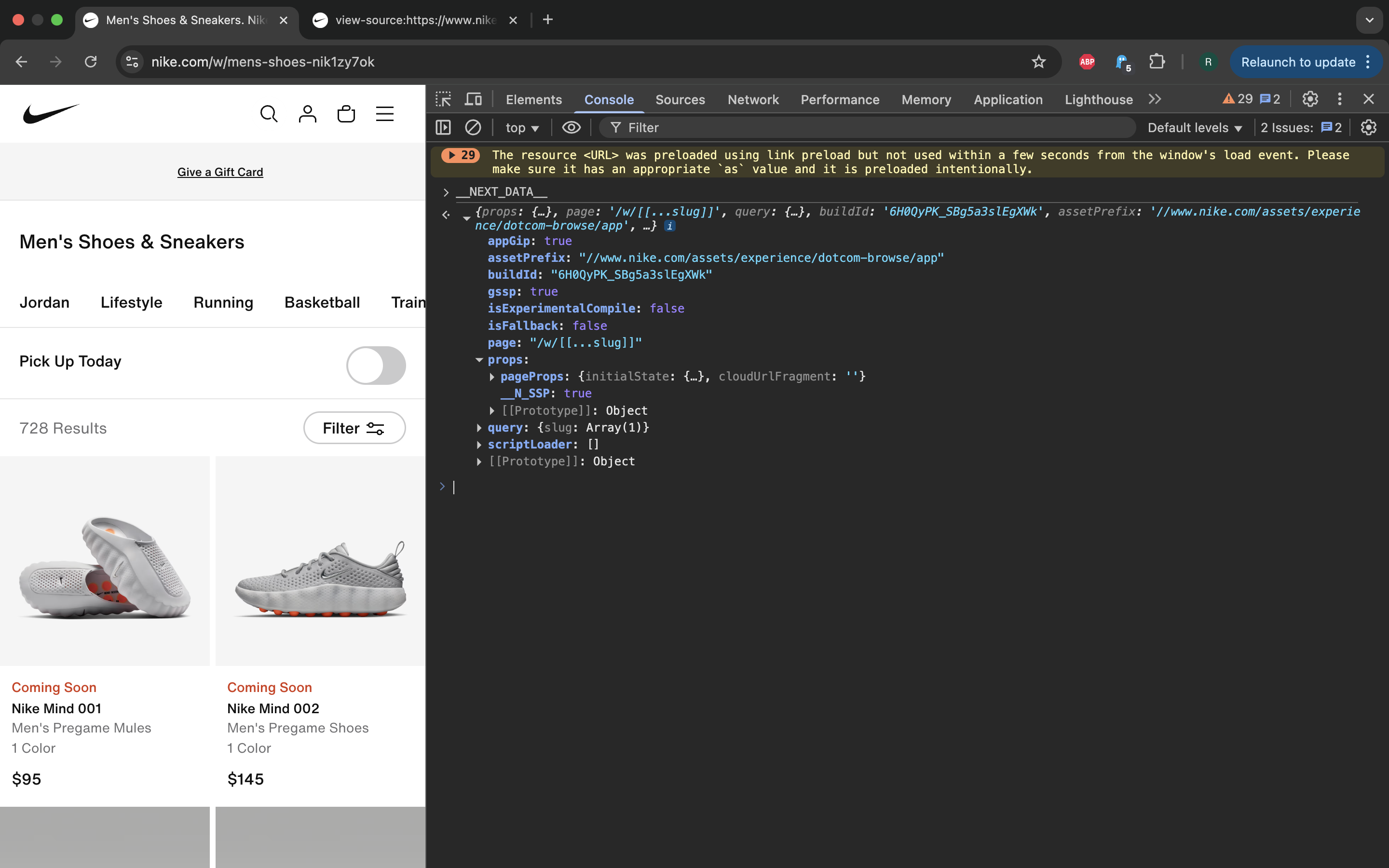
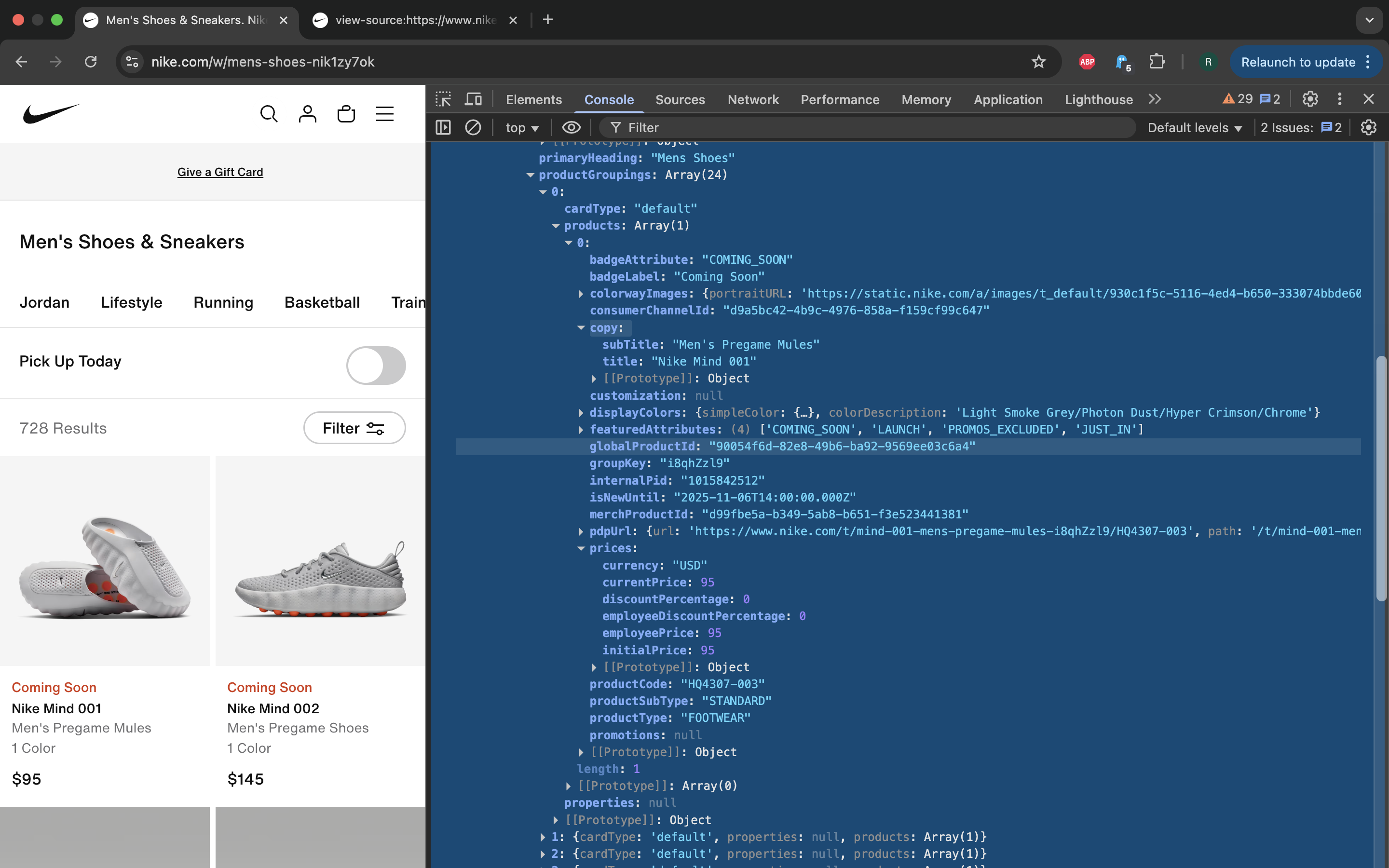
One simple way to browse this data is to type __NEXT_DATA__ into Console tab
of browser dev tools panel. You will be presented with tree structure UI to
explore it. An older post
gives an example of parsing real data from __NEXT_DATA__ JSON document.
{kind=link}
{kind=link}
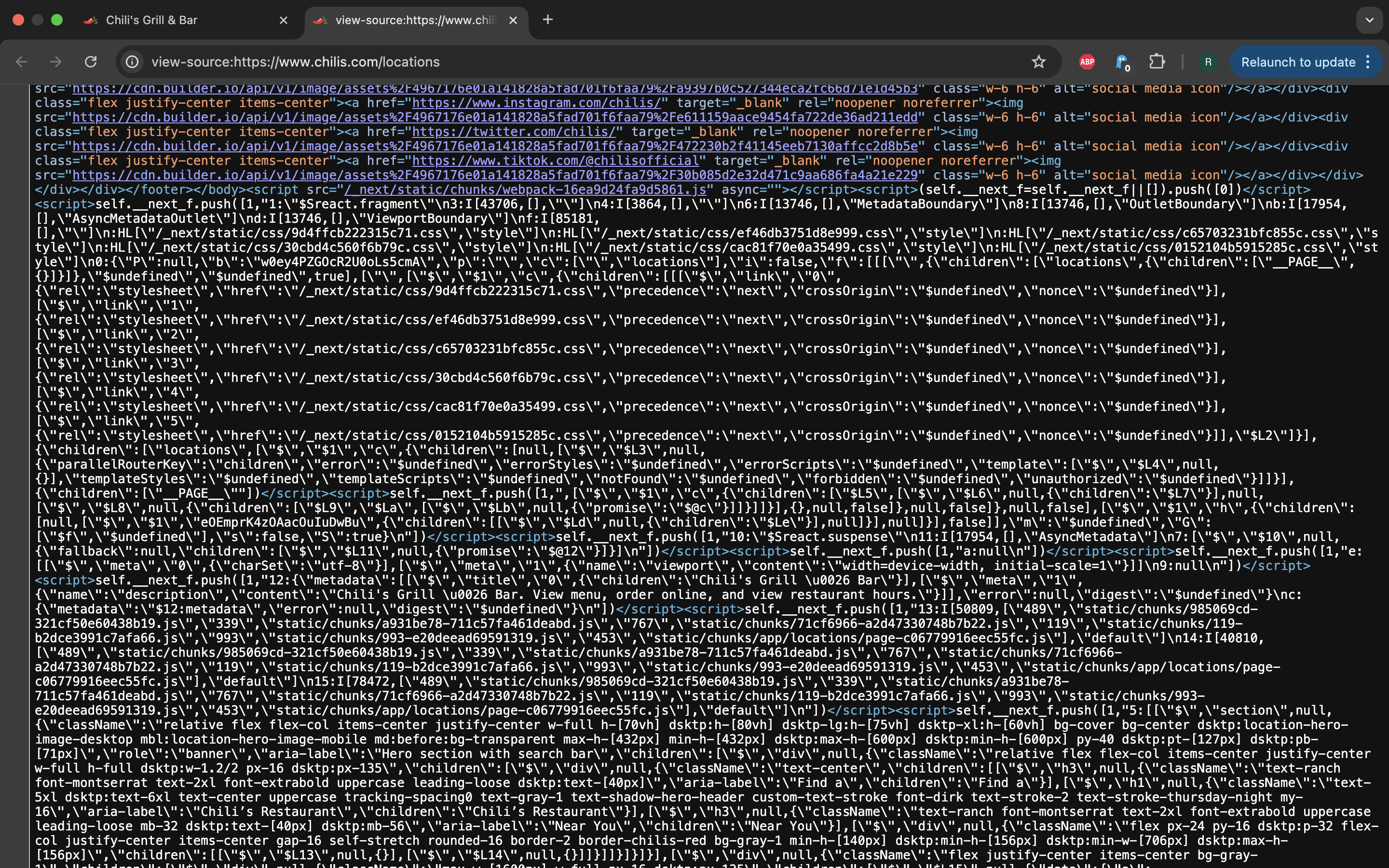
In some newer React/Next.js websites another approach is used to hydrate the
pages that relies on something called React Server Components - a new feature
of React that moves even more computation back to the backend side.
If React Server Components is used, that involves splitting the initial
data into chunks, serializing it to React-specific wire format and including
it into the page through those self.__next_f.push() calls.
{kind=link}
That may or may not make the pages smaller (see Next.js discussion #42170) and from a distance it looks like they’re making already complicated systems even more complicated. But as web scrapers developers we primarily care about extracting data from this mess. So how do we do that?
Serialised stuff in self.__next_f.push() calls is known as Next.js flight
data. We need to parse it somehow. We could read through React.js/Next.js
framework code and try to work it out, but fortunately someone already did the
hard part for us. There’s njsparser
Python module that we can use to scrape pages with Next.js flight data.
In njsparser project documentation we see the following Python snippet:
import requests
import njsparser
import json
# Here I get my page's html
response = requests.get("https://mediux.pro/user/r3draid3r04").text
# Then I parse it with njsparser
fd = njsparser.BeautifulFD(response)
# Then I iterate over the different classes `Data` in my flight data.
for data in fd.find_iter([njsparser.T.Data]):
# Then I make sure that the content of my data is not None, and
# check if the key `"user"` is in the data's content. If it is,
# then i break the loop of searching.
if data.content is not None and "user" in data.content:
break
else:
# If i didn't find it, i raise an error
raise ValueError
# Now i have the data of my user
user = data.content["user"]
# And I can print the string i was searching for before
print(user["tagline"])
Let us extend this snippet a little to provide a way to input proxy URL with page URL to see what can be parsed out of the page:
import requests
import njsparser
from pprint import pprint
proxy_url = input("Proxy URL: ")
if proxy_url.strip() == "":
proxy_url = None
proxies = {
"https": proxy_url
}
url = input("Page URL: ")
response = requests.get(url, proxies=proxies, verify=False)
print(response.url, response.status_code)
fd = njsparser.BeautifulFD(response.text)
for data in fd.find_iter([njsparser.T.Data, njsparser.T.Element]):
print(type(data))
pprint(data)
Now, we can explore a real page with Next.js flight data:
$ python3 njsparser_text.py
Proxy URL:
Page URL: https://www.chilis.com/locations
/Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/urllib3/connectionpool.py:1099: InsecureRequestWarning: Unverified HTTPS request is being made to host 'www.chilis.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#tls-warnings
warnings.warn(
https://www.chilis.com/locations?https= 200
Couldn't find an appropriate type for given class `None`. Giving `Element`.
Couldn't find an appropriate type for given class `None`. Giving `Element`.
<class 'njsparser.parser.types.Data'>
Data(value=['$',
'$10',
None,
{'children': ['$', '$L11', None, {'promise': '$@12'}],
'fallback': None}],
value_class=None,
index=7)
<class 'njsparser.parser.types.Element'>
Element(value={'digest': '$undefined',
'error': None,
'metadata': [['$',
'title',
'0',
{'children': "Chili's Grill & Bar"}],
['$',
'meta',
'1',
{'content': "Chili's Grill & Bar. View menu, "
'order online, and view restaurant '
'hours.',
'name': 'description'}]]},
value_class=None,
index=18)
<class 'njsparser.parser.types.Element'>
Element(value={'digest': '$undefined',
'error': None,
'metadata': '$12:metadata'},
value_class=None,
index=12)
<class 'njsparser.parser.types.Data'>
Data(value=['$',
'$L19',
None,
{'apiKey': '4967176e01a141828a5fad701f6faa79',
'content': {'createdBy': 'g4MEiL4rhtSHs8OUcuU01J0Q8EN2',
'createdDate': 1712696242376,
'data': {'blocks': [{'@type': '@builder.io/sdk:Element',
'@version': 2,
'component': {'name': 'Image',
'options': {'altText': '404 '
'Error '
'- '
'Page '
'Not '
'Found. '
'Click '
'to '
'head '
'back '
'to '
'chilis.com '
'homepage. ',
'aspectRatio': 0.563,
'backgroundPosition': 'center',
'backgroundSize': 'contain',
'fitContent': True,
'height': 594,
'image': 'https://cdn.builder.io/api/v1/image/assets%2F4967176e01a141828a5fad701f6faa79%2Fe821f528372449eca0aaeb5e230dbcc5?width=2000',
'lazy': False,
'lockAspectRatio': False,
'sizes': '(max-width: '
'638px) '
'100vw, '
'(max-width: '
'998px) '
'100vw, '
'143vw',
'srcset': '$1a',
'width': 1056}},
'id': 'builder-30ef217134004c3aad5e4895a0017b5e',
'linkUrl': '/',
'properties': {'href': '/'},
'responsiveStyles': {'large': {'boxSizing': 'border-box',
'cursor': 'pointer',
'display': 'flex',
'flexDirection': 'column',
'flexShrink': '0',
'height': '100',
'minHeight': '20px',
'minWidth': '20px',
'overflow': 'hidden',
'pointerEvents': 'auto',
'position': 'relative',
'width': '100%'}},
'tagName': 'a'},
{'@type': '@builder.io/sdk:Element',
'id': 'builder-pixel-vyr9xl1zoz',
'properties': {'alt': '',
'aria-hidden': 'true',
'height': '0',
'role': 'presentation',
'src': 'https://cdn.builder.io/api/v1/pixel?apiKey=4967176e01a141828a5fad701f6faa79',
'width': '0'},
'responsiveStyles': {'large': {'display': 'block',
'height': '0',
'opacity': '0',
'overflow': 'hidden',
'pointerEvents': 'none',
'width': '0'}},
'tagName': 'img'}],
'state': {'deviceSize': 'large',
'location': {'path': ['not-found'],
'pathname': '/not-found',
'query': {}}},
'themeId': False,
'title': '404 Error Page',
'url': '/not-found'},
'firstPublished': 1712696453909,
'folders': [],
'id': 'a6f4d1a5049d47839e72c55aecda96cb',
'lastUpdated': 1712959355757,
'lastUpdatedBy': 'g4MEiL4rhtSHs8OUcuU01J0Q8EN2',
'meta': {'breakpoints': {'medium': 1023, 'small': 768},
'hasLinks': True,
'kind': 'page',
'lastPreviewUrl': 'https://pp1.preview.chilis.com/not-found?builder.space=eecd8b66e2c94dd393b6f3fdd27468e7&builder.cachebust=true&builder.preview=page&builder.noCache=true&builder.allowTextEdit=true&__builder_editing__=true&builder.overrides.page=eecd8b66e2c94dd393b6f3fdd27468e7_a6f4d1a5049d47839e72c55aecda96cb&builder.overrides.eecd8b66e2c94dd393b6f3fdd27468e7_a6f4d1a5049d47839e72c55aecda96cb=eecd8b66e2c94dd393b6f3fdd27468e7_a6f4d1a5049d47839e72c55aecda96cb&builder.overrides.page:/not-found=eecd8b66e2c94dd393b6f3fdd27468e7_a6f4d1a5049d47839e72c55aecda96cb'},
'modelId': 'fc380e45ad4e4406a61d6c7dfb9d2479',
'name': '404 Error Page',
'published': 'published',
'query': [{'@type': '@builder.io/core:Query',
'operator': 'is',
'property': 'urlPath',
'value': '/not-found'}],
'rev': 'z7bgev4he7i',
'screenshot': 'https://cdn.builder.io/api/v1/image/assets%2F4967176e01a141828a5fad701f6faa79%2Ffdcffe6f669b4e7586b2f75ab97c59fb',
'testRatio': 1,
'variations': {}}}],
value_class=None,
index=24)
Just like in the original form, we get the data in chunks. Each chunk is Python object with nested structure inside. Not much to explain here - just traverse the structure and extract the fields you need.
Lastly, njsparser project ships with a small CLI tool to check the pages if they have Next.js data to parse:
$ njsparser "https://www.chilis.com/locations"
Couldn't find an appropriate type for given class `None`. Giving `Element`.
Couldn't find an appropriate type for given class `None`. Giving `Element`.
Build Id: -KU-QA00B1JuhGcqPQ6eQ
The site contains flight data.
Pages:
- https://www.chilis.com/_app
- https://www.chilis.com/_error
$ njsparser "https://www.nike.com/t/air-jordan-1-retro-high-og-pro-green-womens-shoes-Hnf3kV/FD2596-101"
Build Id: ixvlnhp8VLcjaN1TTvfqm
The site contains a __NEXT_DATA__ script.
Pages:
- https://www.nike.com/_app
- https://www.nike.com/_error
- https://www.nike.com/t/[slug]
- https://www.nike.com/t/[slug]/[styleColor]
To conclude, we learned about Next.js flight data and how to use an open source Python library to make it tractable within web scrapers written in Python.