DNS is a network protocol and a distributed system that maps human-readable domain names to IP addresses. It can be thought of as a big phone book for internet hosts. Passive DNS recon is activity of using various data sources to map out a footprint of site or organisation without ever directly accessing the target or launching DNS requests. That’s basically doing OSINT on DNS names and records that are linked to the target. Passive DNS recon is not limited to the current state of DNS records, but also covers historical data and temporal analysis.
Passive DNS recon can be done for various purposes, such as:
- Investigating security incidents.
- Detecting shadow IT, misconfigurations and legacy/forgotten servers that might be insecure.
- Mapping out attack surface for the organisation.
- Detecting dangling subdomains linked to third party services that may provide opportunities for subdomain takeovers, perhaps leading to a bug bounty payment.
- Detecting third party SaaS and cloud services being used by the target.
- Gaining insights on business activities of competitors - for example, a SaaS company might have customer-specific subdomains.
- Finding origin server to scrape the site in a way that bypasses countermeasures implemented by content delivery network.
Let us go through some of the ways one can perform passive DNS recon, assuming we have one or more seed domains to start from.
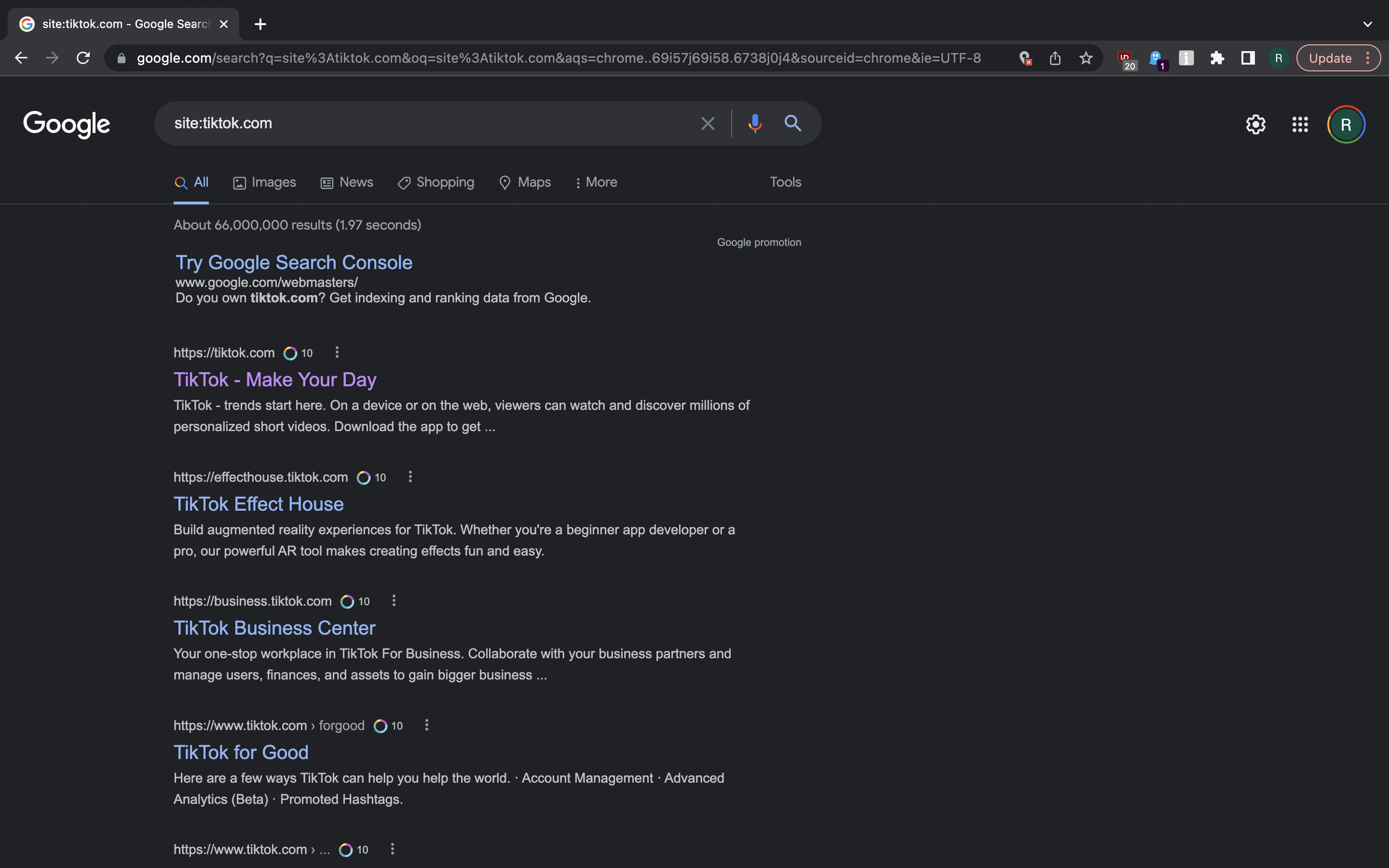
One way to do it is search engine dorking. We use site: operator
with our seed domain to find some results from the site. Some of the
results will probably be from subdomains. You exclude these subdomains
from search results by using -site: thingy to get some more subdomains:
site:tiktok.com
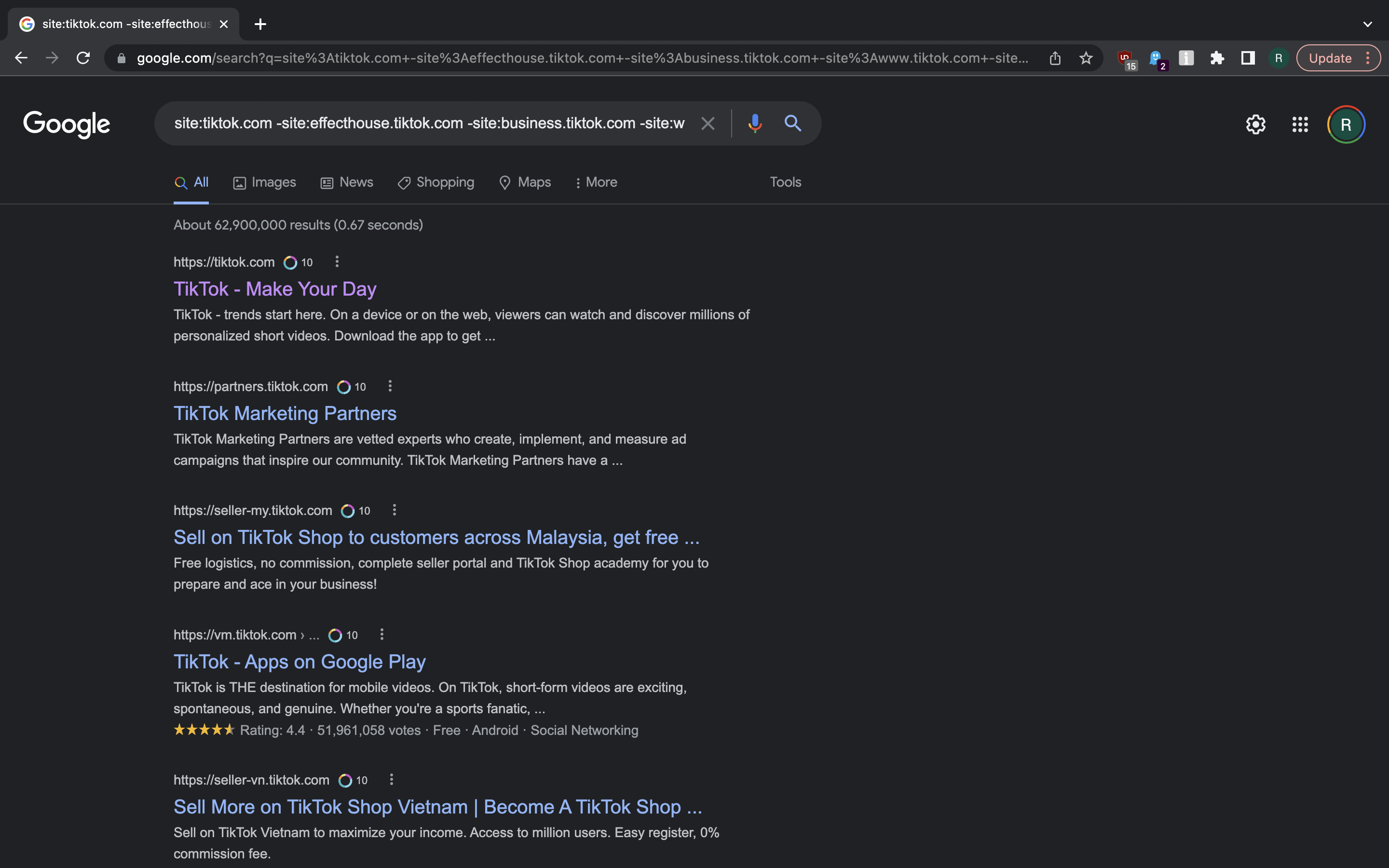
site:tiktok.com -site:effecthouse.tiktok.com -site:business.tiktok.com -site:www.tiktok.com -site:newsroom.tiktok.com
site:tiktok.com -site:effecthouse.tiktok.com -site:business.tiktok.com -site:www.tiktok.com -site:newsroom.tiktok.com -site:vm.tiktok.com -site:seller-vn.tiktok.com -site:careers.tiktok.com -site:ads.tiktok.com
...
{kind=link}
{kind=link}
This is performed until there are no more new subdomains. There’s recon-ng module based on this trick to automatically scrape subdomains from Google SERPs. One can also use Bright Data Search Engine Crawler or similar product to outsource search engine scraping via API. Furthermore, Bing and other search engines can also be used for finding subdomains.
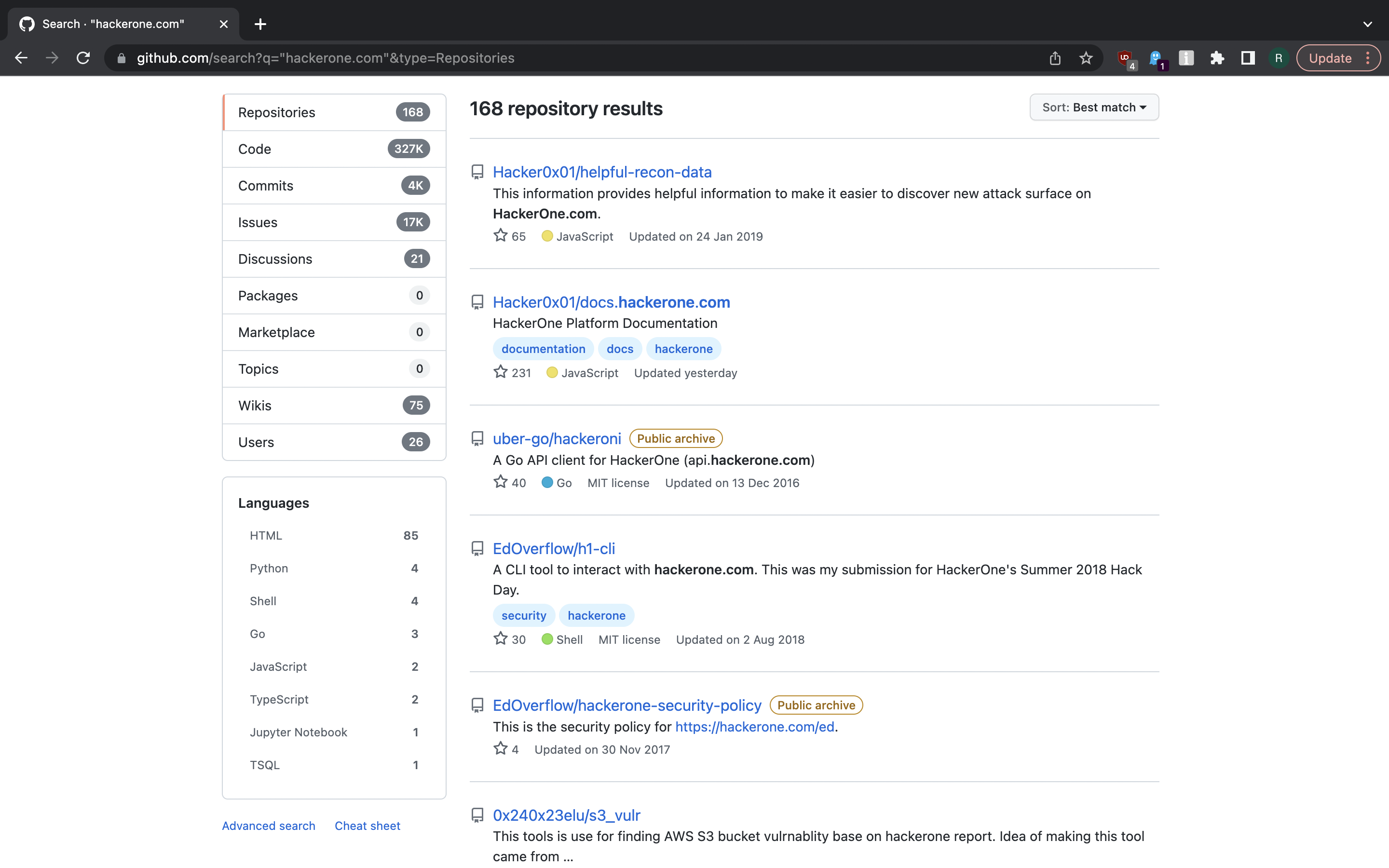
Github is another source for finding subdomains. Merely searching for seed domain in Github search (which can also be done via API) is likely to get you some subdomains that can be extracted with little string processing.
{kind=link}
Yet another source is Internet Archive/Wayback machine. It does not give you subdomains directly, but allows searching for URLs with wildcard queries:
$ curl "http://web.archive.org/cdx/search/cdx?url=*.hackerone.com/*&output=json&collapse=urlkey" > urls.json
Subdomains can be trivially extracted from these URLs.
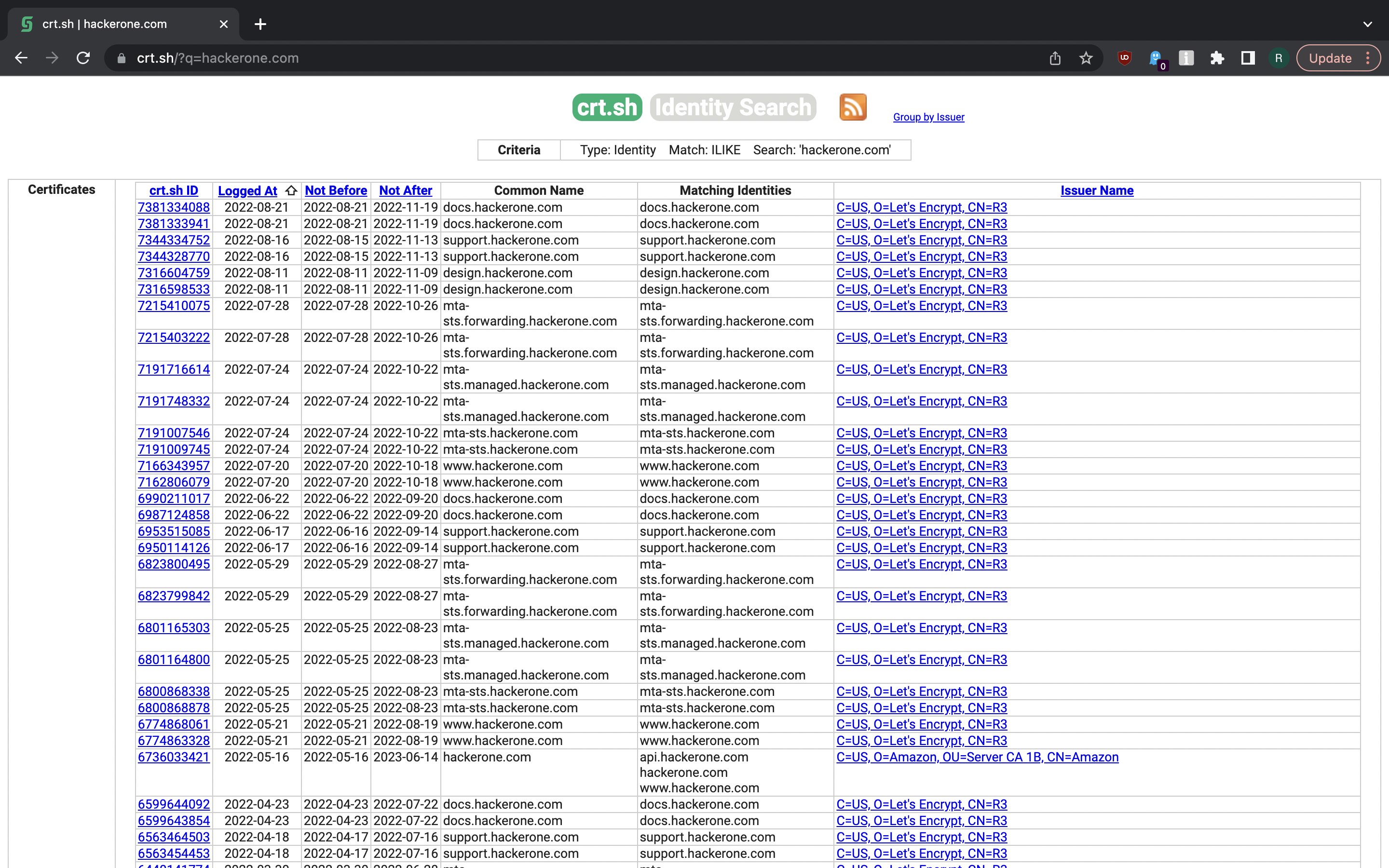
X.509 certificates can be mined to extract subdomains. To search through a lot
of certificates, one can use certificate transparency tool such as
crt.sh (it also exposes PostgreSQL database that you can
connect to with psql(1): psql -h crt.sh -p 5432 -U guest certwatch) or query Facebook’s
Certificate Transparency API.
{kind=link}
Some other sources for finding subdomains include:
Since DNS data is relevant to security, many companies in the world gather it for you and provide it for your analysis via some web UI or API. Some of these companies are:
- Censys
- Shodan
- SecurityTrails
- IntelligenceX
- RiskIQ
- ZoomEye
To gather as much subdomains as possible, one needs to have automated way to query many data sources. Two most prominent tools to do that are:
Chaos is a project that provides subdomain datasets for companies running public bounty program (gathered through active enumeration that is outside the scope of this post).
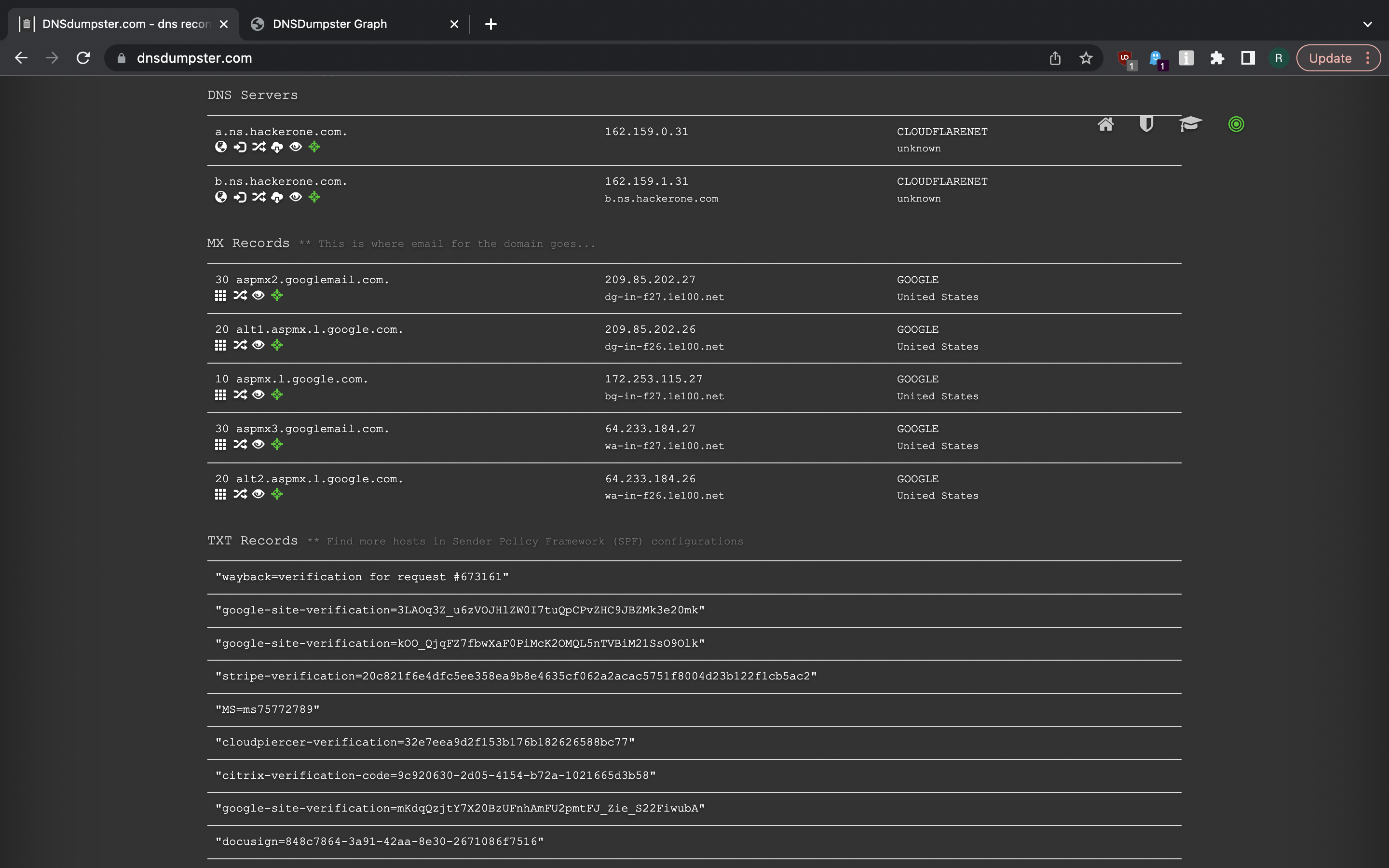
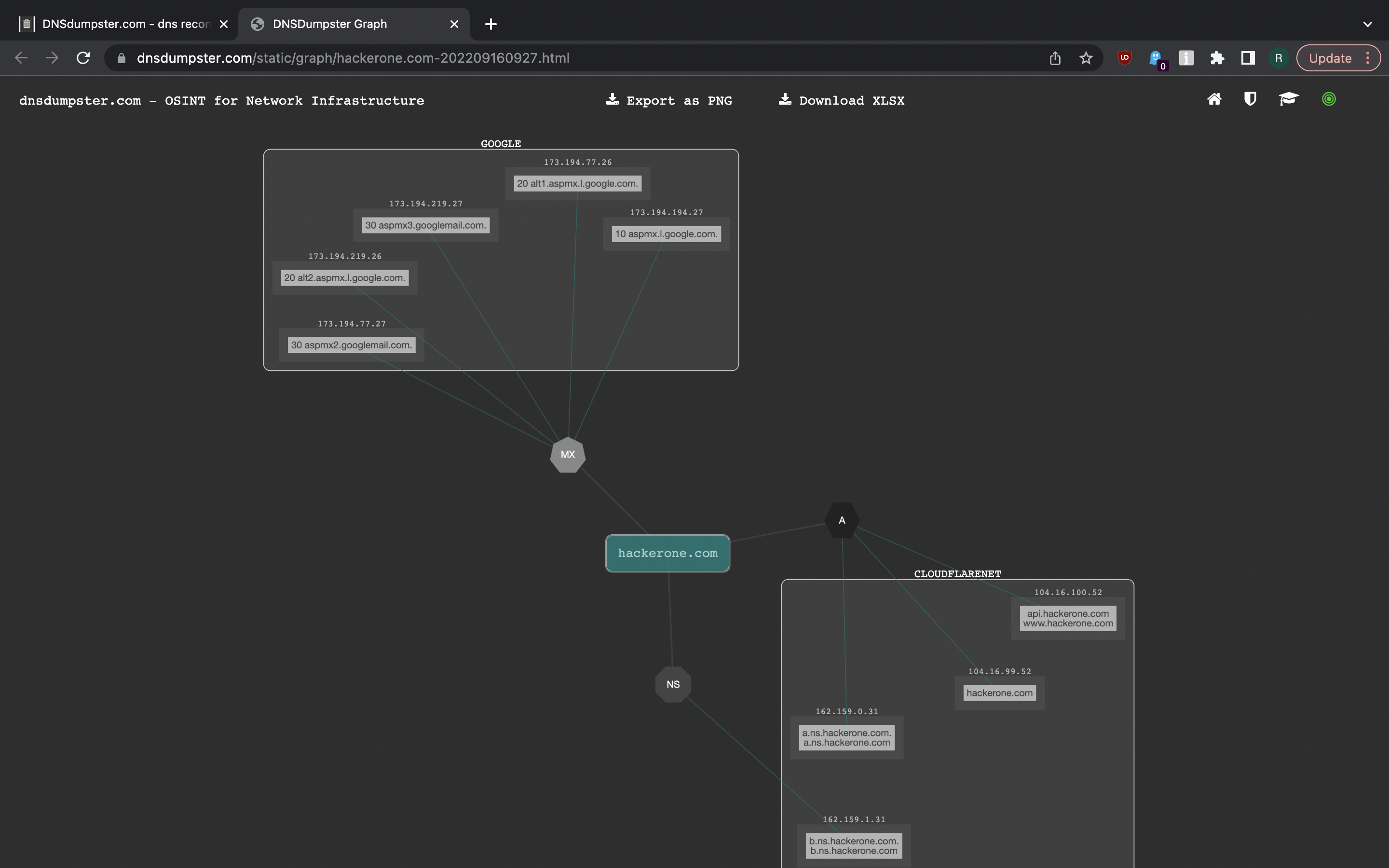
DNSdumpster is a free domain research tool one can use to find subdomains and DNS records. It also provides a nice graphical visualisation on links between records.
{kind=link}
{kind=link}