Beautiful Soup (also known as bs4) is a Python module for parsing HTML (and
also XML) documents. It is commonly used in web scraper development. Beautiful
Soup takes an HTML string and parses it into a tree structure that reflects
the structure of DOM tree, but has properties and methods related to
accessing data and running queries.
We can install it via PIP as beautifulsoup4. Furthermore, some operating
systems ship Beautiful Soup in their package managers. For example,
there’s python3-bs4 package on Debian APT.
Beautiful Soup does not perform parsing on it’s own. Instead, it uses a lower level HTML/XML parsing library and converts the results into it’s own data model. As of September 2023, there are following options for the HTML parsing library:
- Python’s vanilla HTML parser (
html.parser) - middling performance and average tolerance to malformed HTML. lxml- Python wrapper around libxml2 C library - very good performance, quite lenient for bad HTML.html5lib- Pure Python HTML5 parser that is slow, but can deal with some pretty messed up pages.
Since Beautiful Soup is an abstraction over these HTML/XML parsers we have some flexibility when choosing the underlying parser while keeping the same data model.
Let us explore how to use Beautiful Soup for web scraping. We start by using the lxml parser on a simple HTML document.
$ python3
Python 3.11.5 (main, Aug 24 2023, 15:09:45) [Clang 14.0.3 (clang-1403.0.22.14.1)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html_str, 'lxml')
>>> soup
<html><head><title>Title!</title></head><body><h1>The Title</h1></body></html>
>>> type(soup)
<class 'bs4.BeautifulSoup'>
We can regenerate the HTML document in a pretty-printed form:
>>> print(soup.prettify())
<html>
<head>
<title>
Title!
</title>
</head>
<body>
<h1>
The Title
</h1>
</body>
</html>
We can use object properties to traverse across the tree structure and extract stuff we may want to parse:
>>> soup.title
<title>Title!</title>
>>> soup.title.text
'Title!'
>>> soup.title.name
'title'
>>> soup.body.h1.text
'The Title'
To provide an example on how to run queries, let us have a bigger HTML document to parse:
<html>
<head>
<title>Product list</title>
</head>
<body>
<table border="1">
<thead>
<tr>
<th>Product name</th>
<th>Price</th>
<th>URL</th>
</tr>
</thead>
<tbody>
<tr>
<td id="productname" class="productname">Jordan 4 Retro</td>
<td id="price">$269</td>
<td><a id="pdpurl" href="https://stockx.com/air-jordan-4-retro-red-cement">link</a></td>
</tr>
<tr>
<td id="productname" class="productname">adidas Yeezy Boost 350 V2 Static (Non-Reflective) (2018/2023)</td>
<td id="price">$195</td>
<td><a id="pdpurl" href="https://stockx.com/adidas-yeezy-boost-350-v2-static">link</a></td>
</tr>
</tbody>
</table>
</body>
</html>
Now we can use find() method to find a single result or find_all() to find
multiple results:
>>> in_f = open("test.html", "r")
>>> html_str = in_f.read()
>>> in_f.close()
>>> soup = BeautifulSoup(html_str, "lxml")
>>> soup.find('title')
<title>Product list</title>
>>> soup.find_all(class_='productname')
[<td class="productname" id="productname">Jordan 4 Retro</td>, <td class="productname" id="productname">adidas Yeezy Boost 350 V2 Static (Non-Reflective) (2018/2023)</td>]
>>> soup.find_all(id='price')
[<td id="price">$269</td>, <td id="price">$195</td>]
>>> soup.find_all(attrs={'class':'productname', 'id':'productname'})
[<td class="productname" id="productname">Jordan 4 Retro</td>, <td class="productname" id="productname">adidas Yeezy Boost 350 V2 Static (Non-Reflective) (2018/2023)</td>]
To extract text recursively from a (sub)tree we can use get_text() method:
>>> print(soup.get_text())
Product list
Product name
Price
URL
Jordan 4 Retro
$269
link
adidas Yeezy Boost 350 V2 Static (Non-Reflective) (2018/2023)
$195
link
Let us fetch a more complex page for more advanced example (Bright Data Web Unlocker is used here):
>>> import requests
>>> proxy_url = "[REDACTED]"
>>> resp = requests.get("https://clutch.co/directory/iphone-application-developers", proxies={'https': proxy_url})
>>> resp = requests.get("https://clutch.co/directory/iphone-application-developers", proxies={'https': proxy_url}, verify=False)
/opt/homebrew/lib/python3.11/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'brd.superproxy.io'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
>>> resp
<Response [200]>
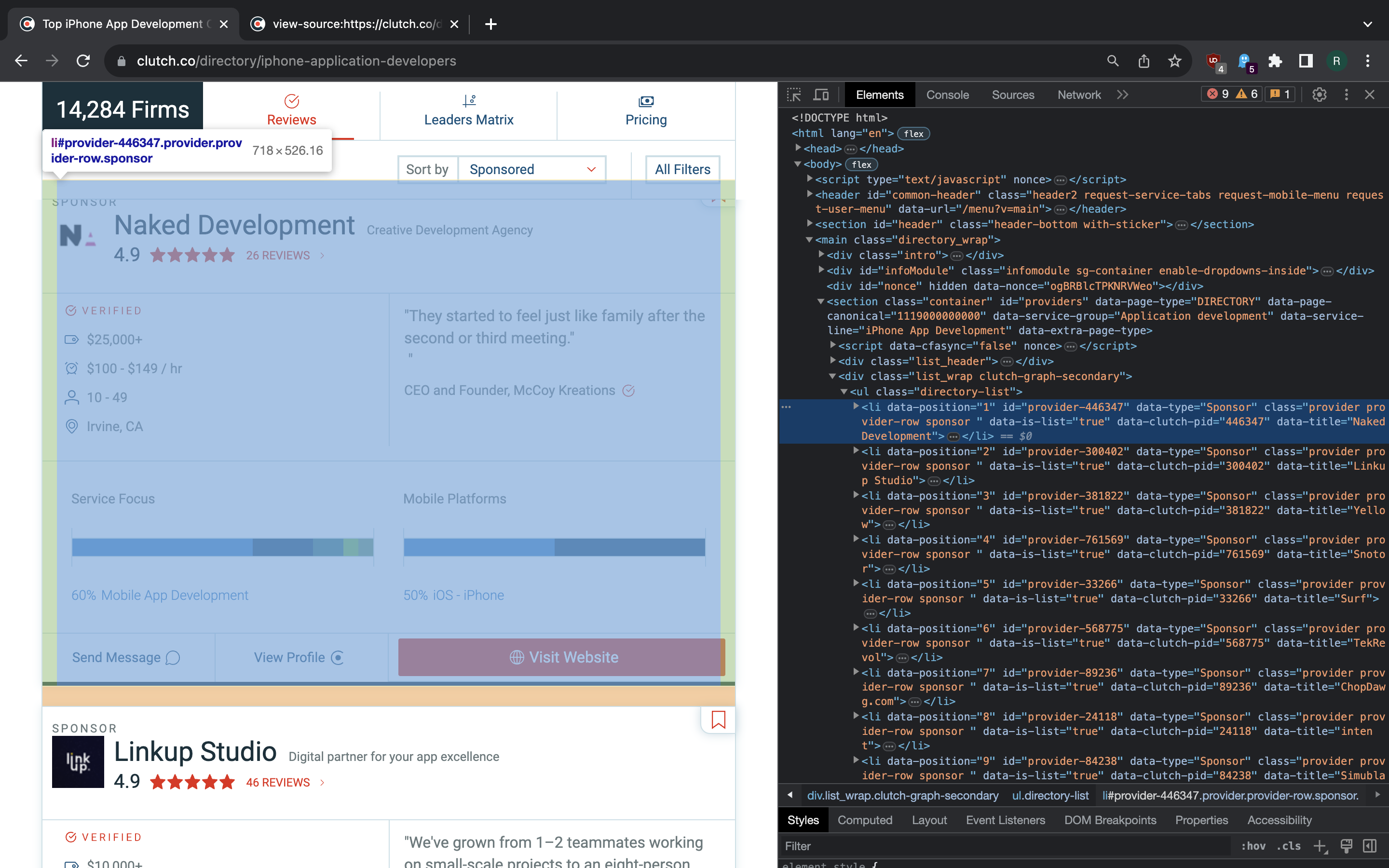
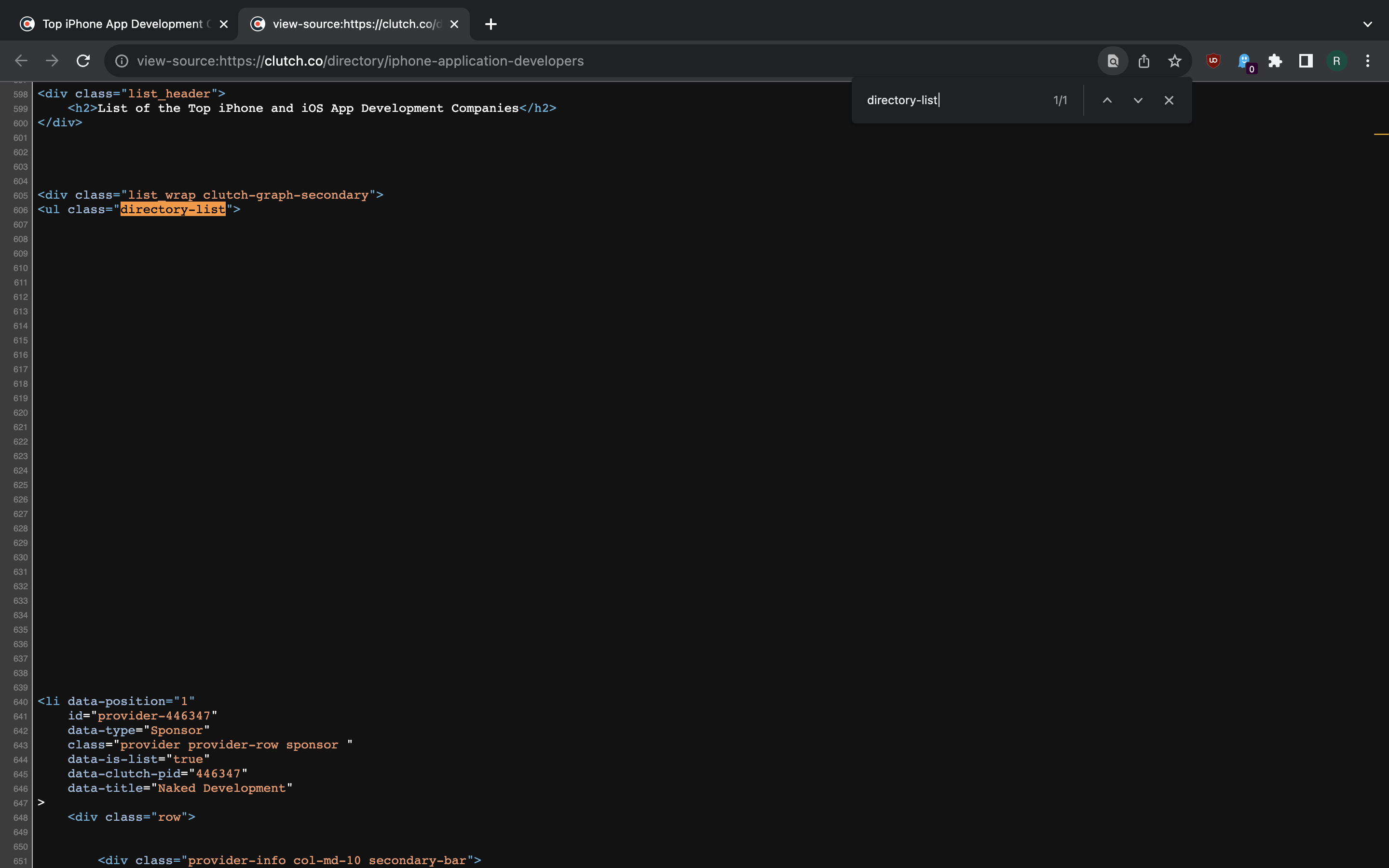
By inspecting the page we see that list items are children of <ul> element
with class directory-list.
Screenshot 1 Screenshot 2 Screenshot 3
{kind=link}
{kind=link}
{kind=link}
Now, let us try to parse it and extract some data based on structure we see when inspecting the page:
>>> soup = BeautifulSoup(resp.text, 'html.parser')
>>> ul = soup.find('ul', class_='directory-list')
>>> list_items = ul.find_all('li')
>>> li = list_items[0]
>>> title = li.find(attrs={'data-link_text': 'Profile Title'})
>>> title
<a class="company_title directory_profile" data-link_text="Profile Title" href="/profile/naked-development" target="_blank">
Naked Development
</a>
>>> title = li.find(attrs={'data-link_text': 'Profile Title'}).text
>>> title
'\n Naked Development\n '
>>> title = title.strip()
>>> title
'Naked Development'
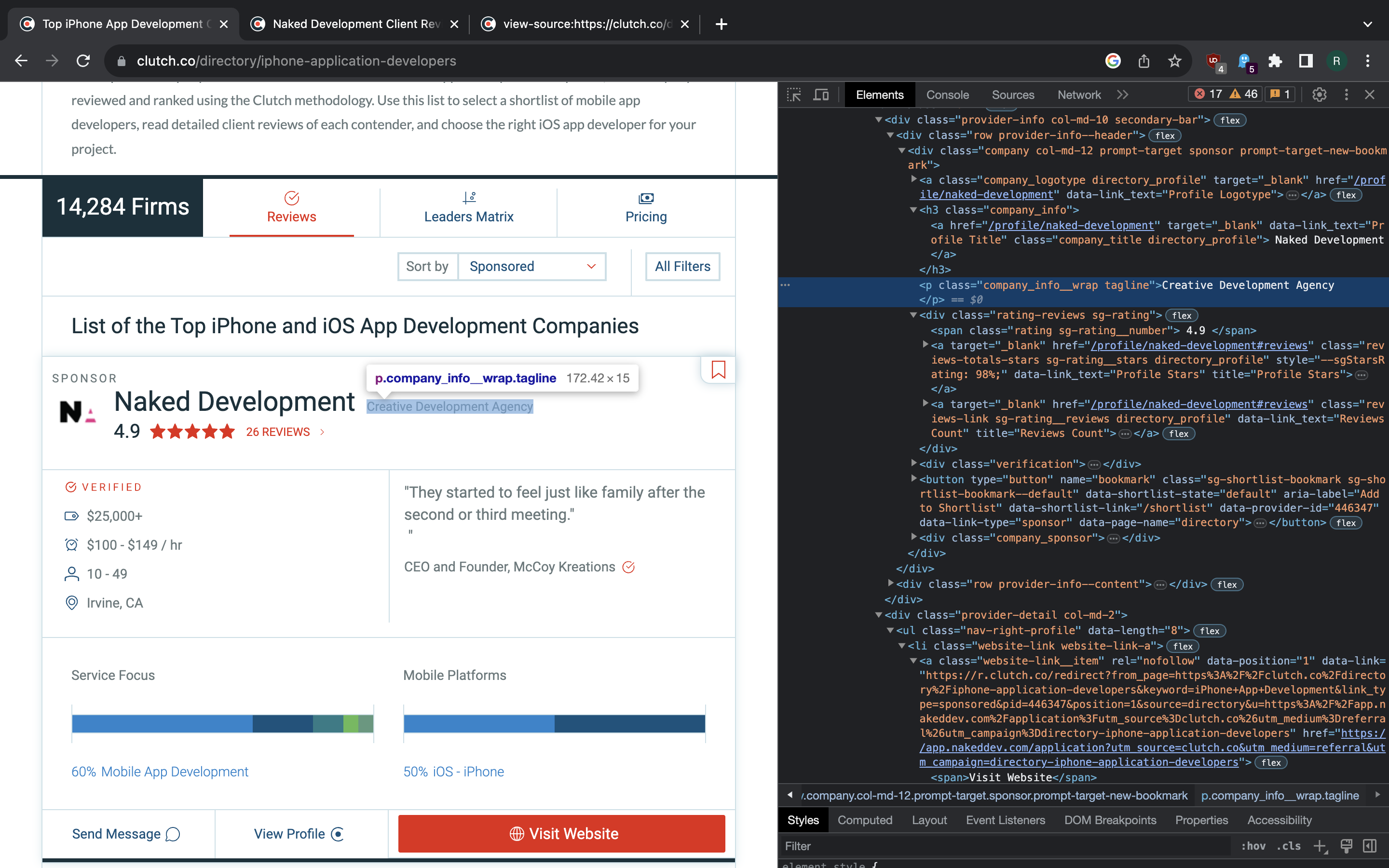
>>> li.find(class_="company_info__wrap").text
'Creative Development Agency'
>>> li.find(attrs={'data-link_text': 'Profile Title'}).attrs['href']
'/profile/naked-development'
>>> li.find(class_="website-link__item").attrs['href']
'https://app.nakeddev.com/application?utm_source=clutch.co&utm_medium=referral&utm_campaign=directory-iphone-application-developers'
Happy scraping!