The following text assumes some knowledge and experience with Scrapy and is meant to provide a realistic example of scraping moderately difficult site that you may be doing as freelancer working in web scraping. This post is not meant for people completely unfamiliar with Scrapy. The reader is encouraged to read some content earlier in the blog that introduces Scrapy from ground up. This time, we are building up from the knowledge about basics of Scrapy and thus skipping some details.
For North America, Zillow is a number one portal for real estate listings for sale and rent. Due to its significance in real estate industry it is of interest for web scraping. We are going to use Python programming language and Scrapy framework to scrape information on various properties on Zillow. Let us assume that FSBO (for sale by owner) listings are of particular interest to us. They are sold directly by the owner and represent a business opportunity for realtor to help them make a sale.
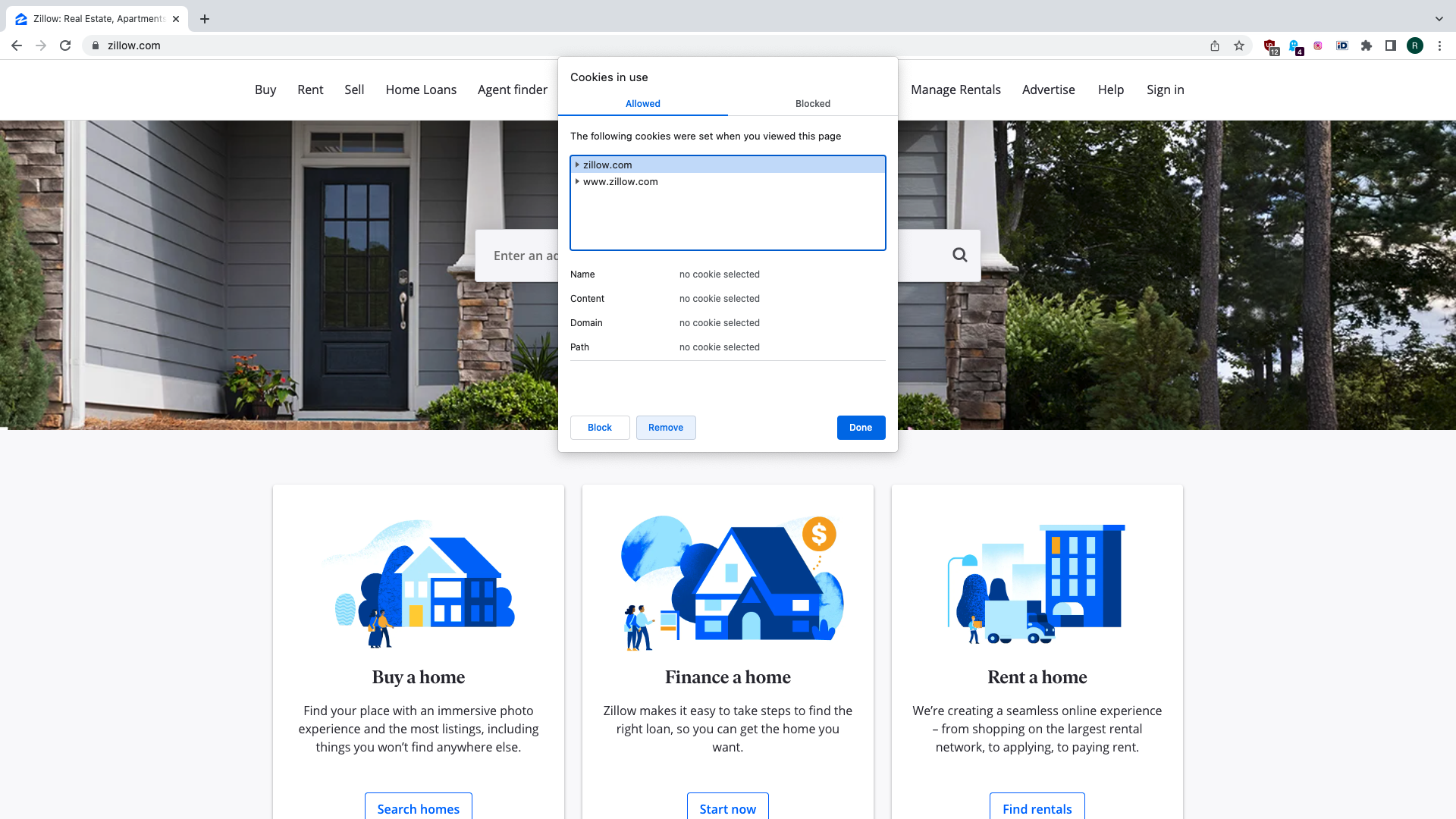
Before we write a first of code, we need to explore the site to plan a general strategy of how we are going to scrape it. We want to take a look how site handles cookies so we force-delete them from the browser to see how they are acquired in the request flow.
{kind=link}
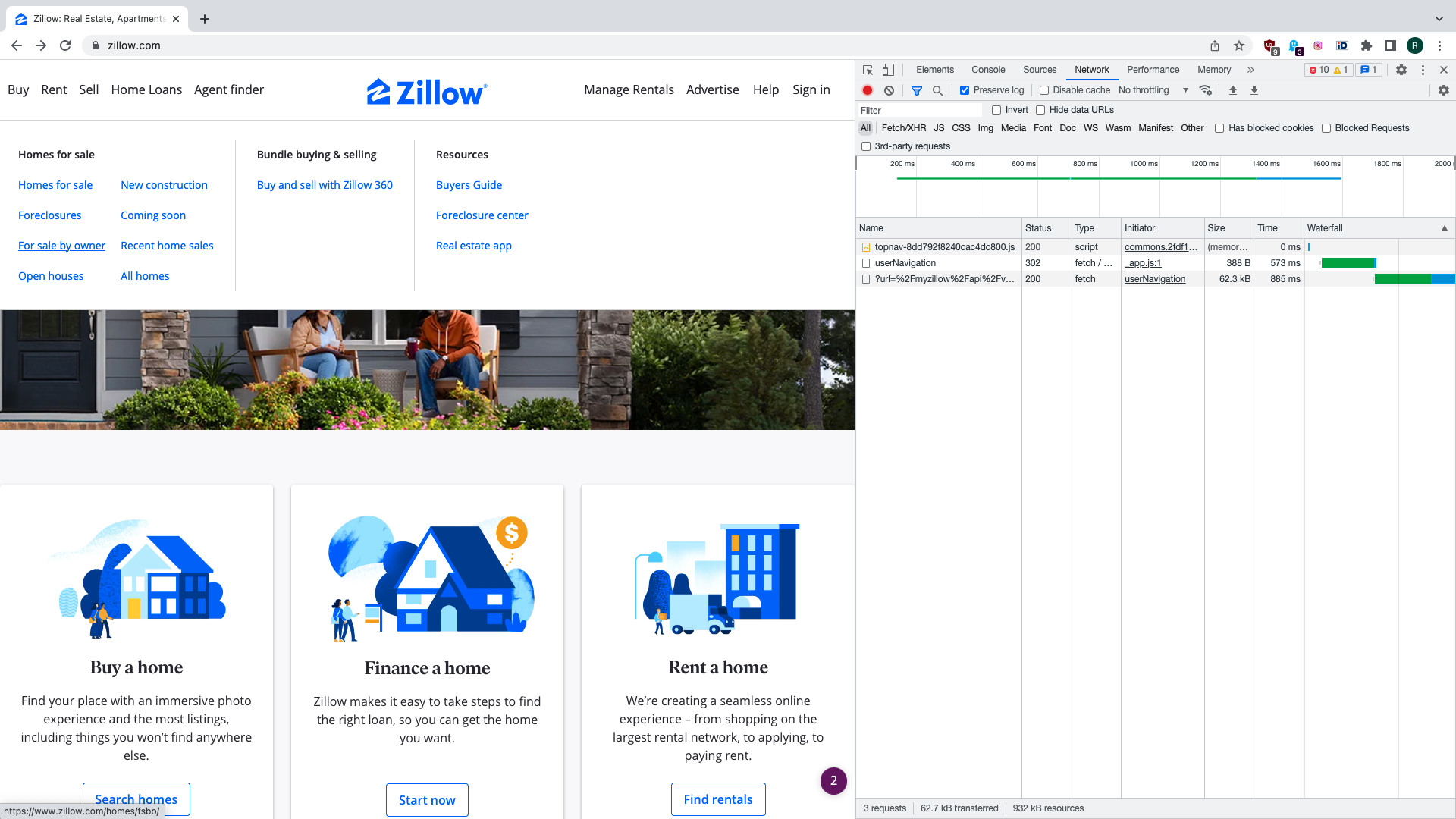
On the top header we see options to rent, buy, sell, etc. If we hover the word “Buy” with mouse cursor we can choose properties that are sold by the owner. We click this link with DevTools being open.
{kind=link}
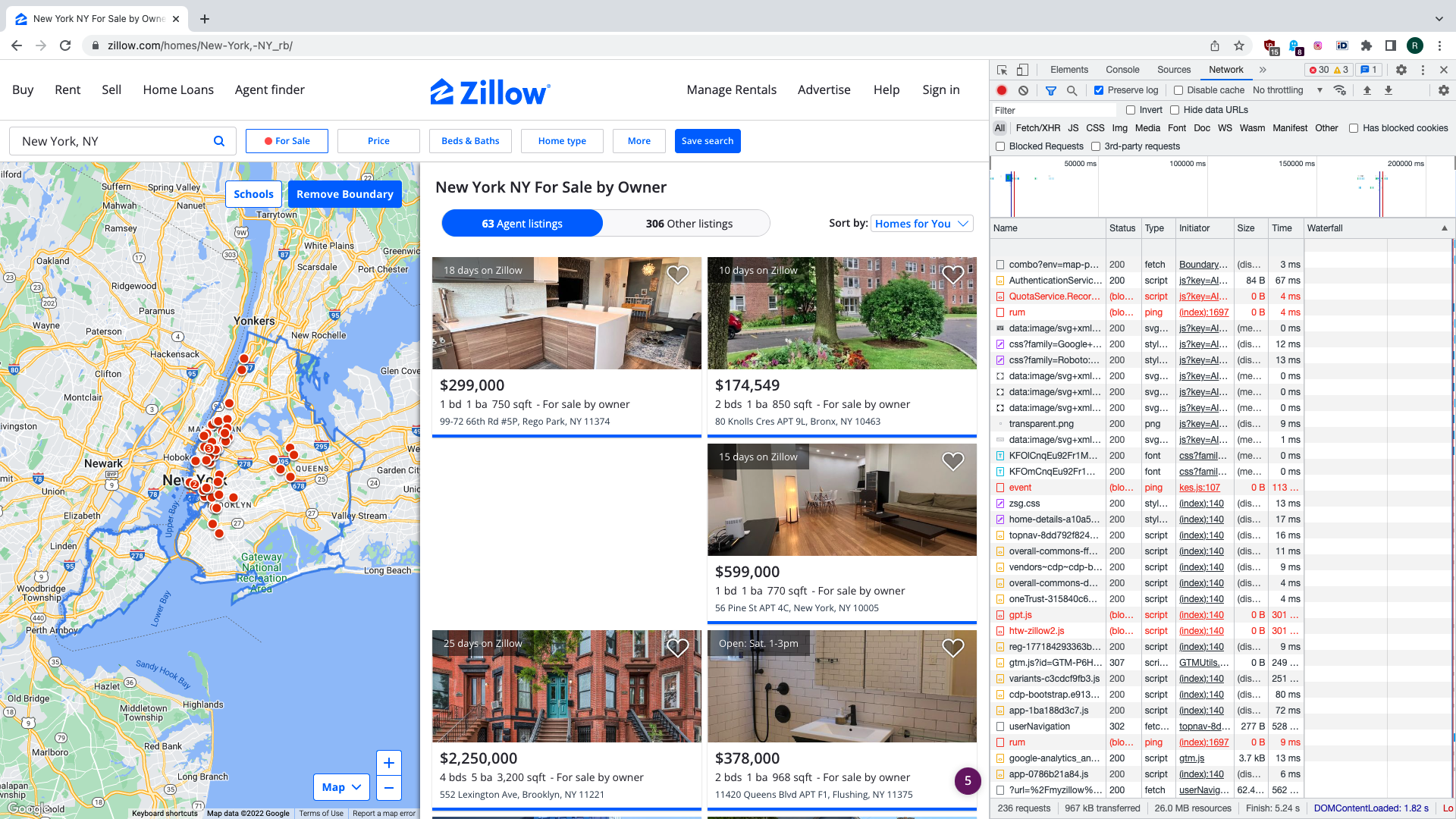
Now if we enter some location into search bar we only get the FSBO listings, but there’s nothing in the URL that seems to tell the site to only return such results. This suggests that cookies are being used for session management and to keep track of state between requests. Let us look bit deeper into this.
{kind=link}
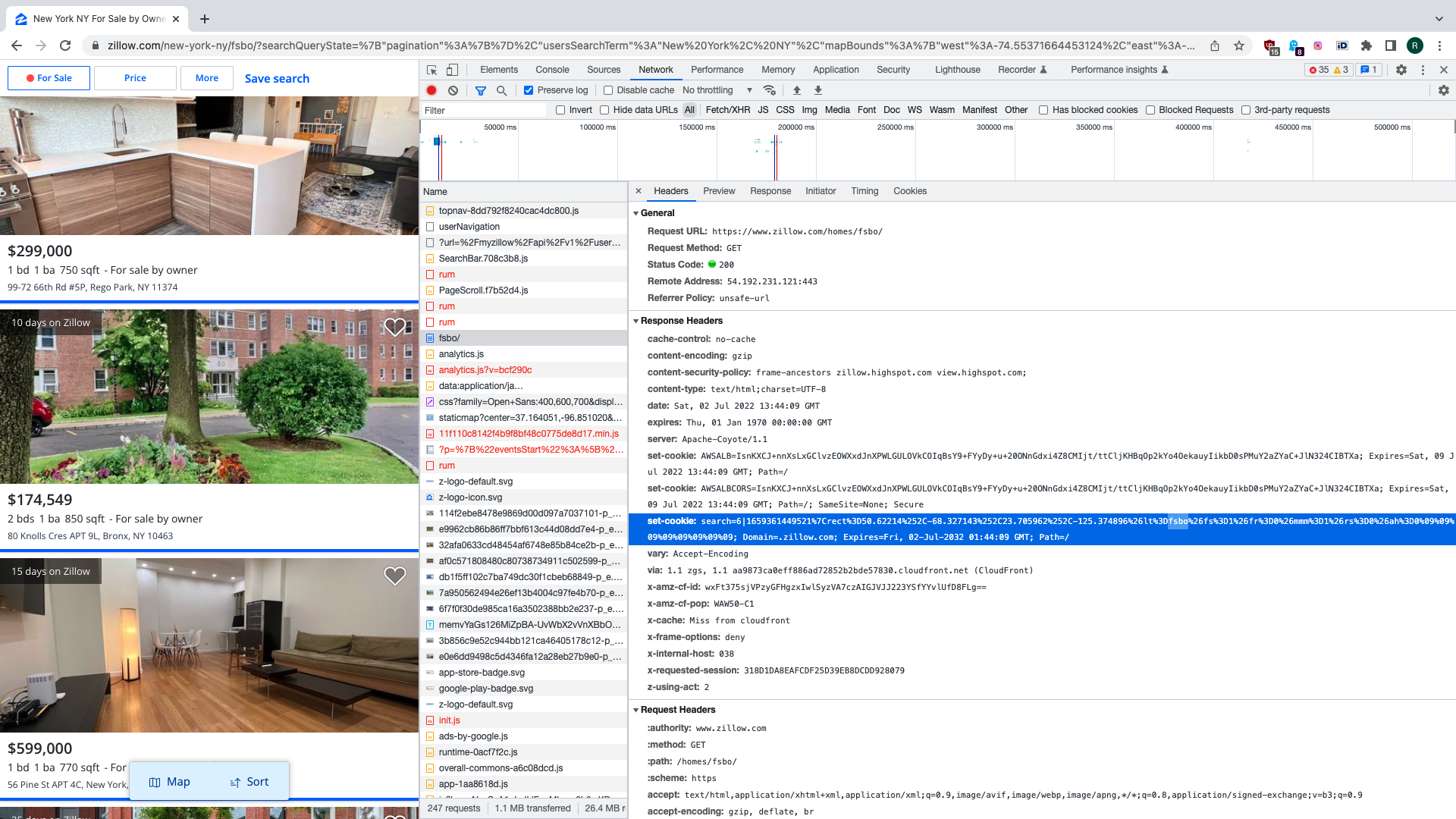
By scrolling up in the Network tab of DevTools panel we find the request that was sent
when we clicked the “For Sale By Owner” link earlier. In response, Zillow gives us some
cookies, one of which is named search and has letters fsbo in the value.
{kind=link}
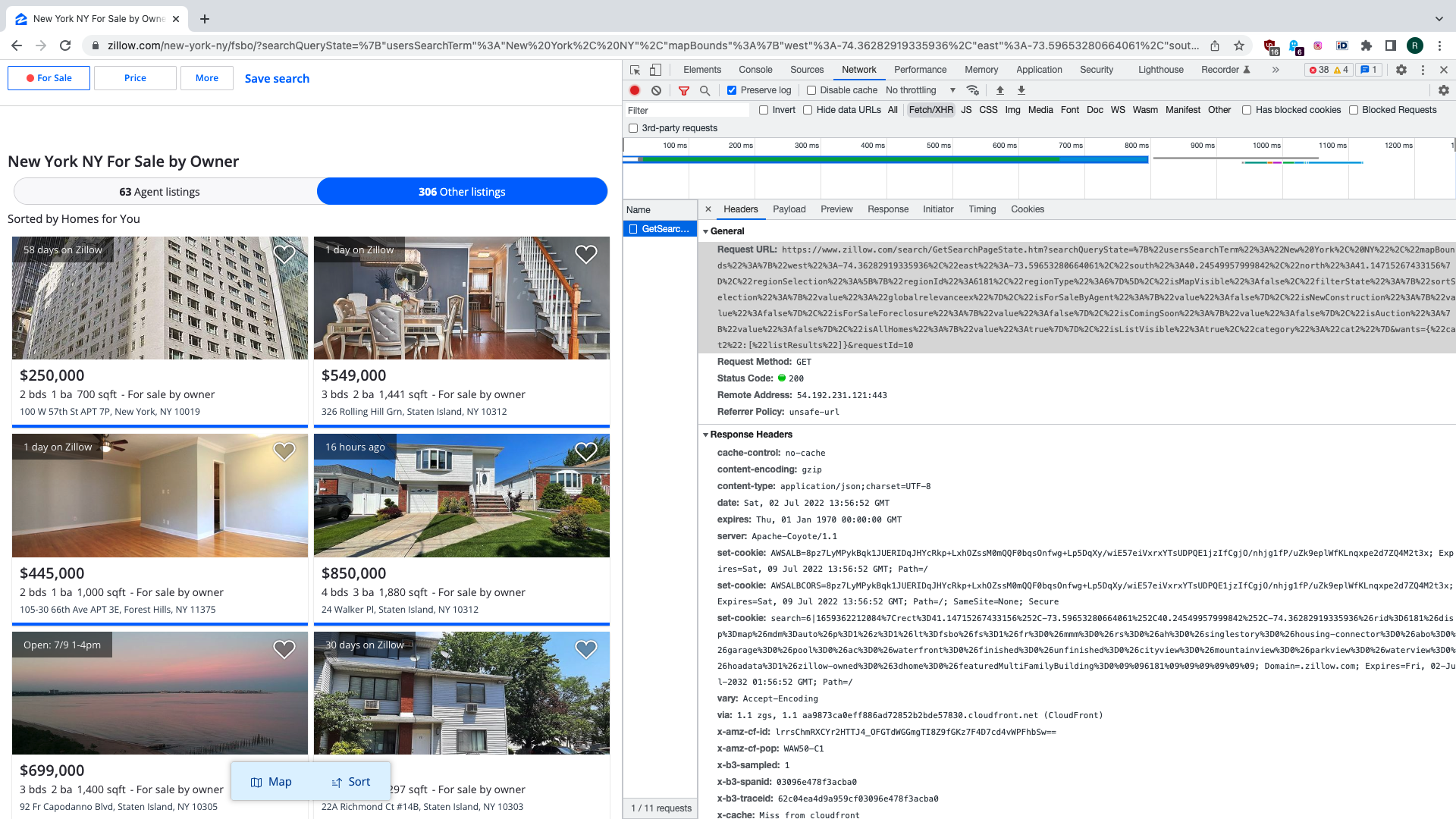
However there’s a bit of a problem. Search results section has two tabs. The first one which is on by default is for results that already have real estate agent helping with the sale. We are actually interested in results on the second tab. Let us see what happens when we switch the tab. We find that API request is made when we switch the tab to update the data being shown.
{kind=link}
{kind=link}
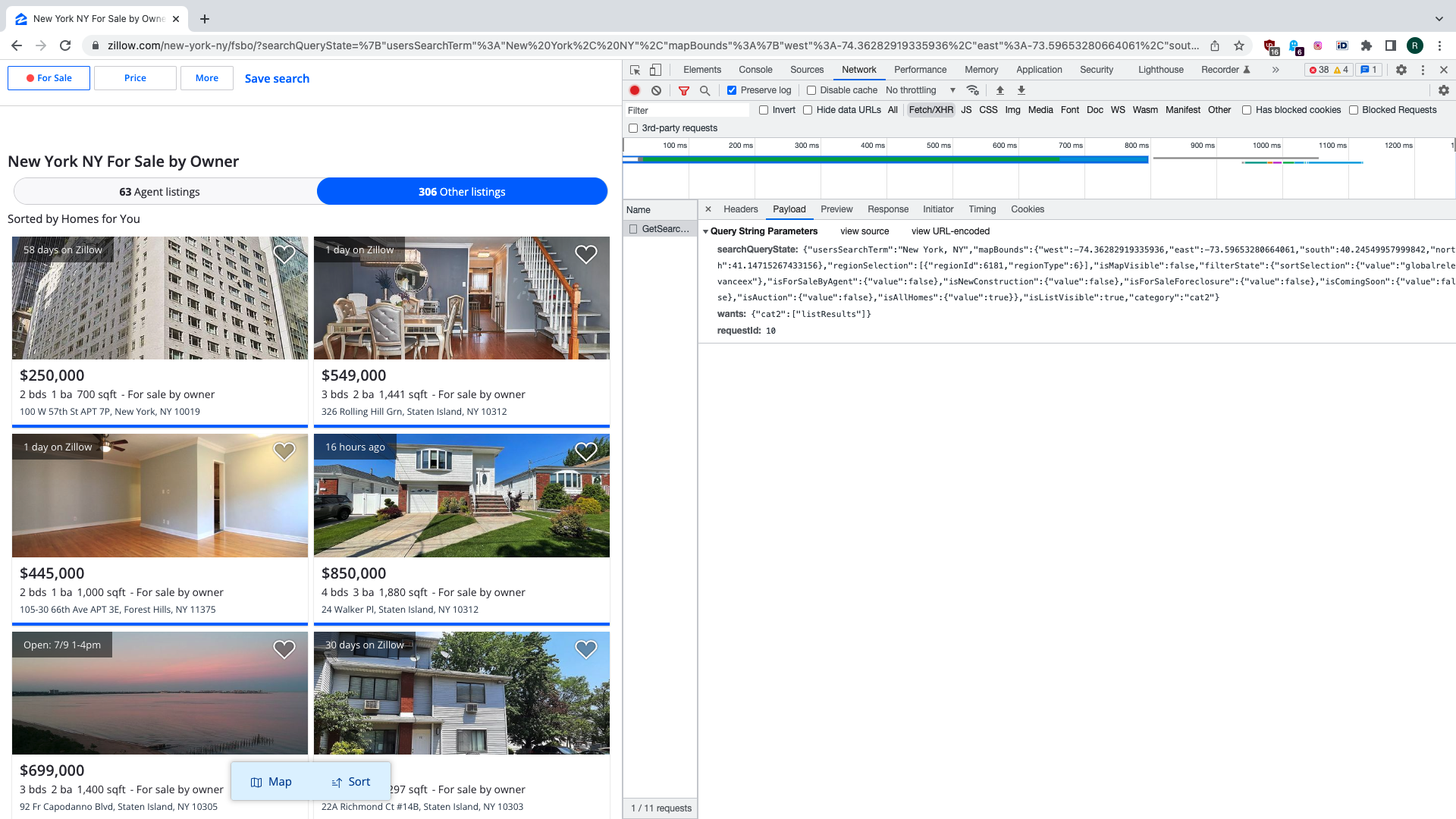
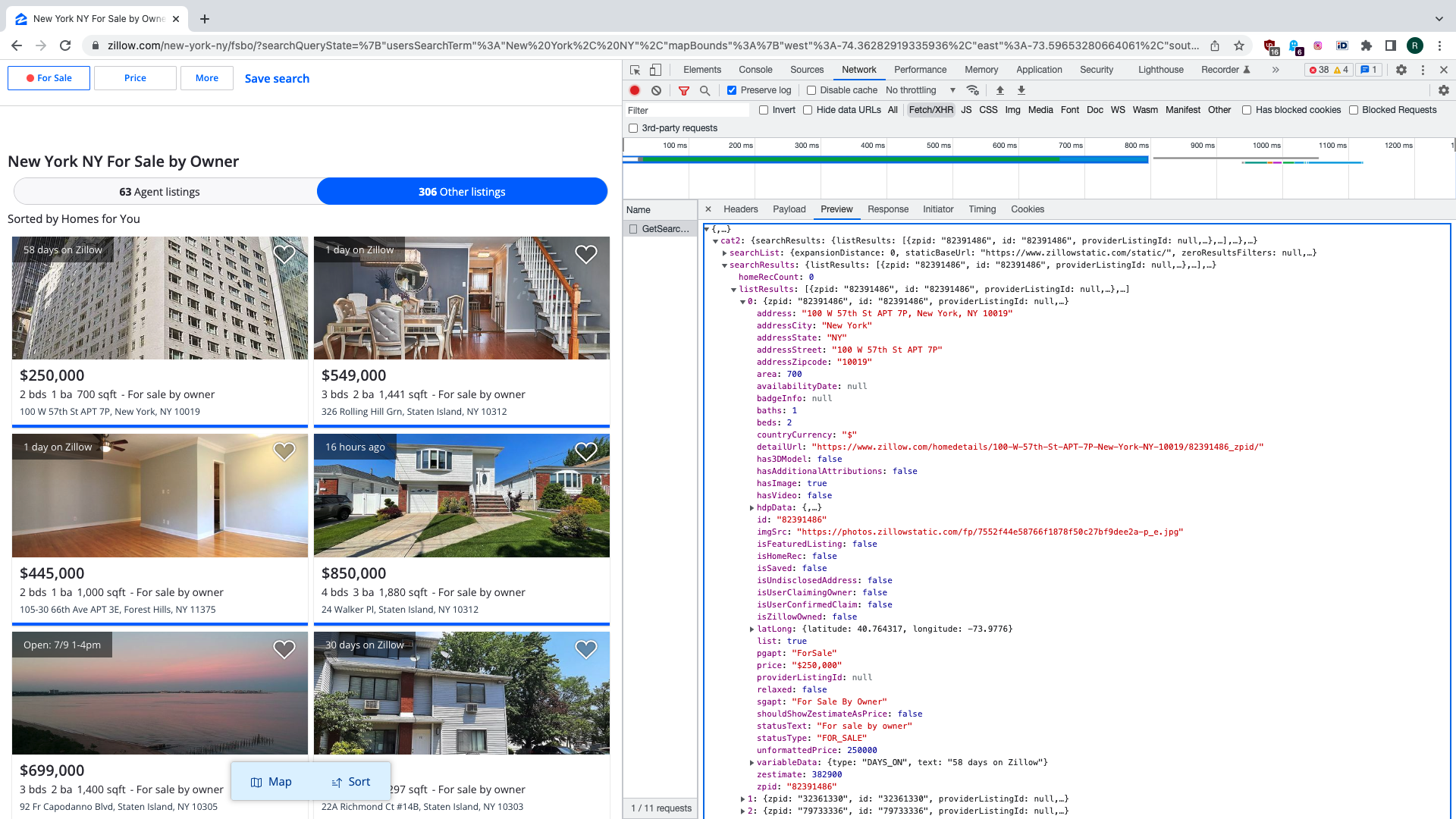
There are two key parameters to this request. One is for search query state that contains geographical boundaries and other search criteria. Another specifies which result category we want to get. Both are serialised as JSON strings. Response payload contains data about properties being found in JSON format. We are talking to a private API here.
{kind=link}
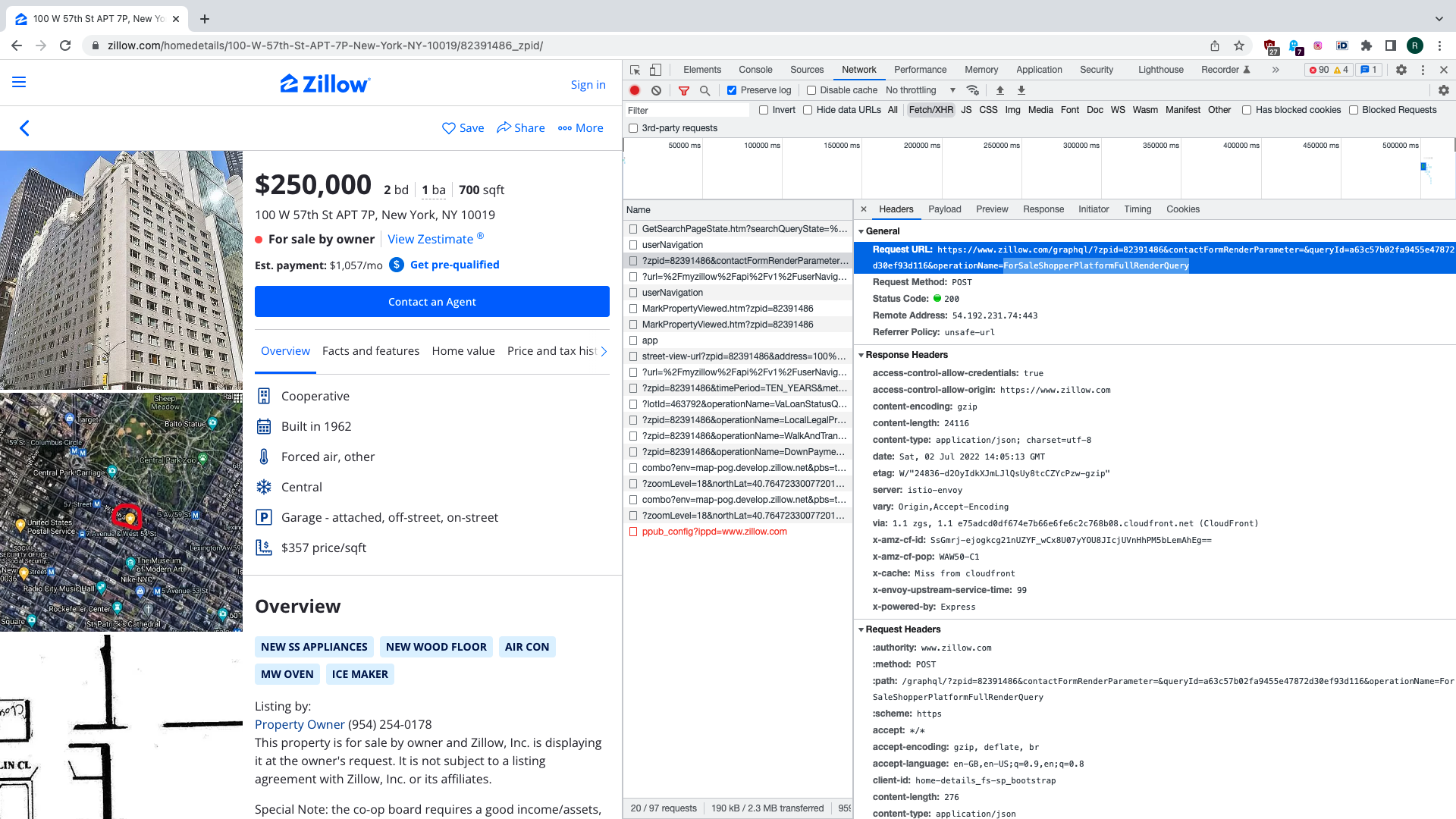
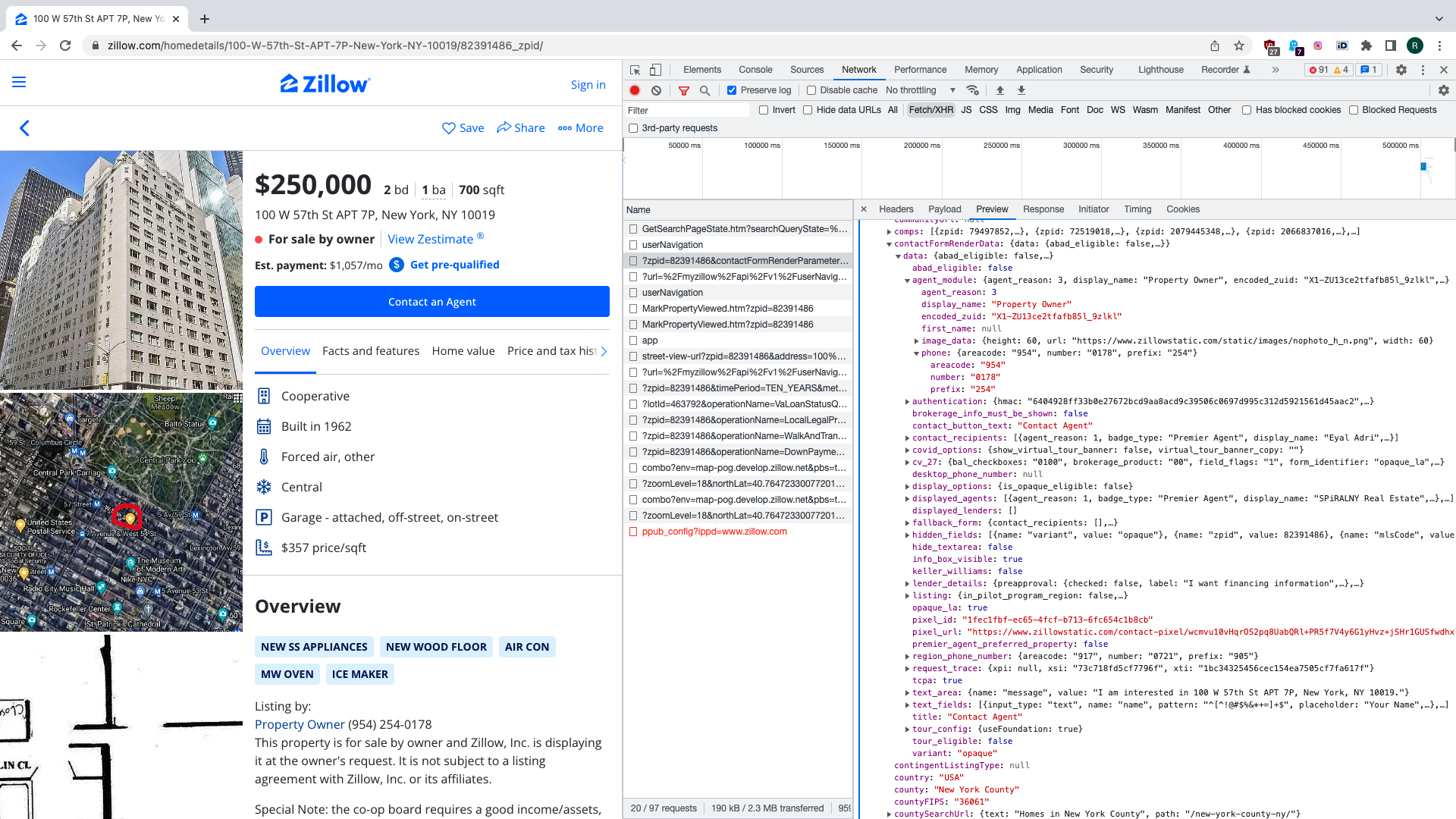
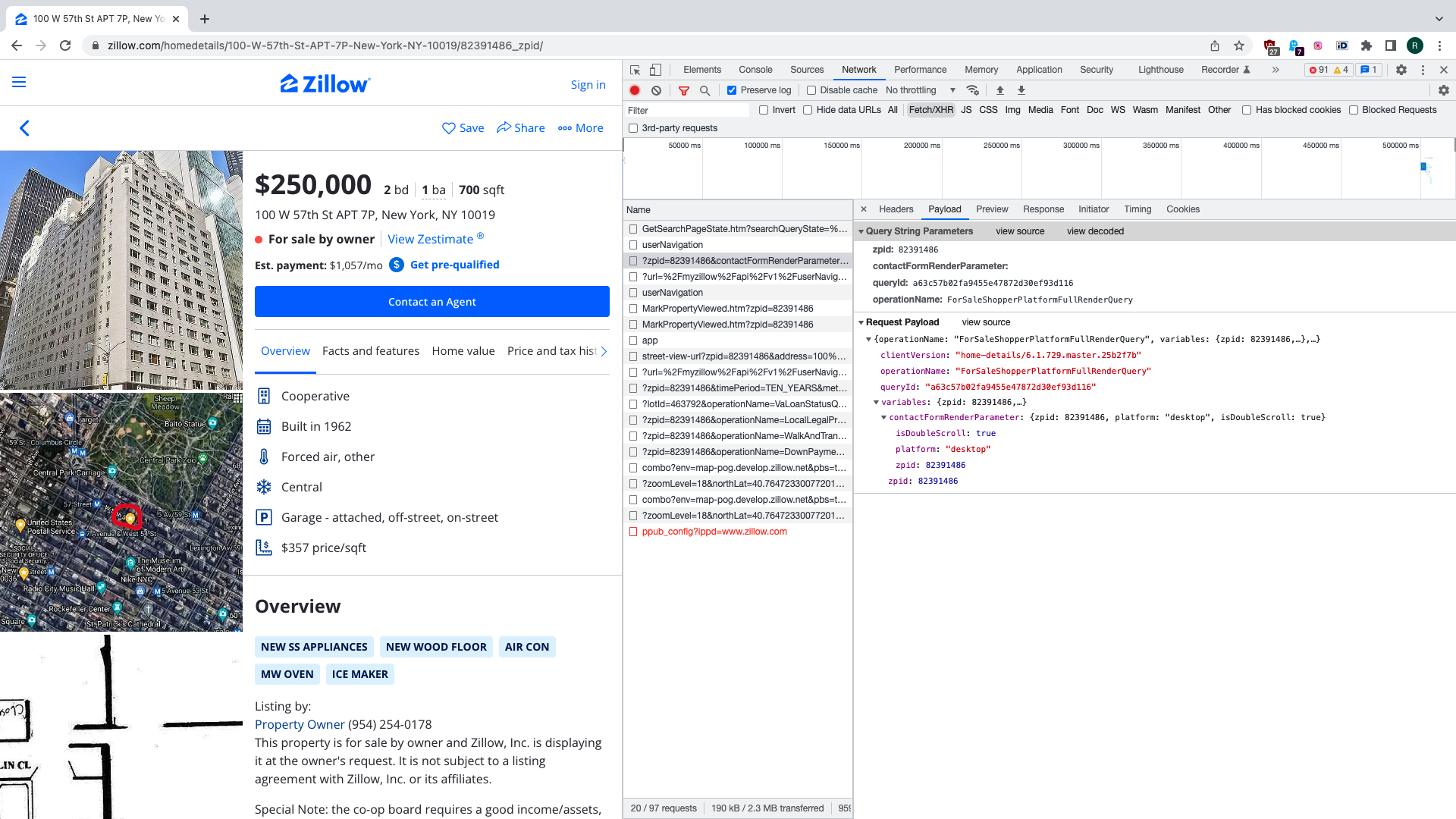
If we click on one of the search results we see that few more API requests are made. One
of them is of particular interest to us. There’s a request sent to /graphql endpoint
having ForSaleShopperPlatformFullRenderQuery value for URL parameter operationName.
In the response there’s bunch of data that is rendered into property details page,
including contact details for a person trying to sell their place. This request is
parametrised not only by URL paramers, but there’s also JSON payload with Zillow
property ID and operation name. We will be reproducing this request programmatically, as
well as the previous one that gives us search results.
Screenshot 7 Screenshot 8 Screenshot 9
{kind=link}
{kind=link}
{kind=link}
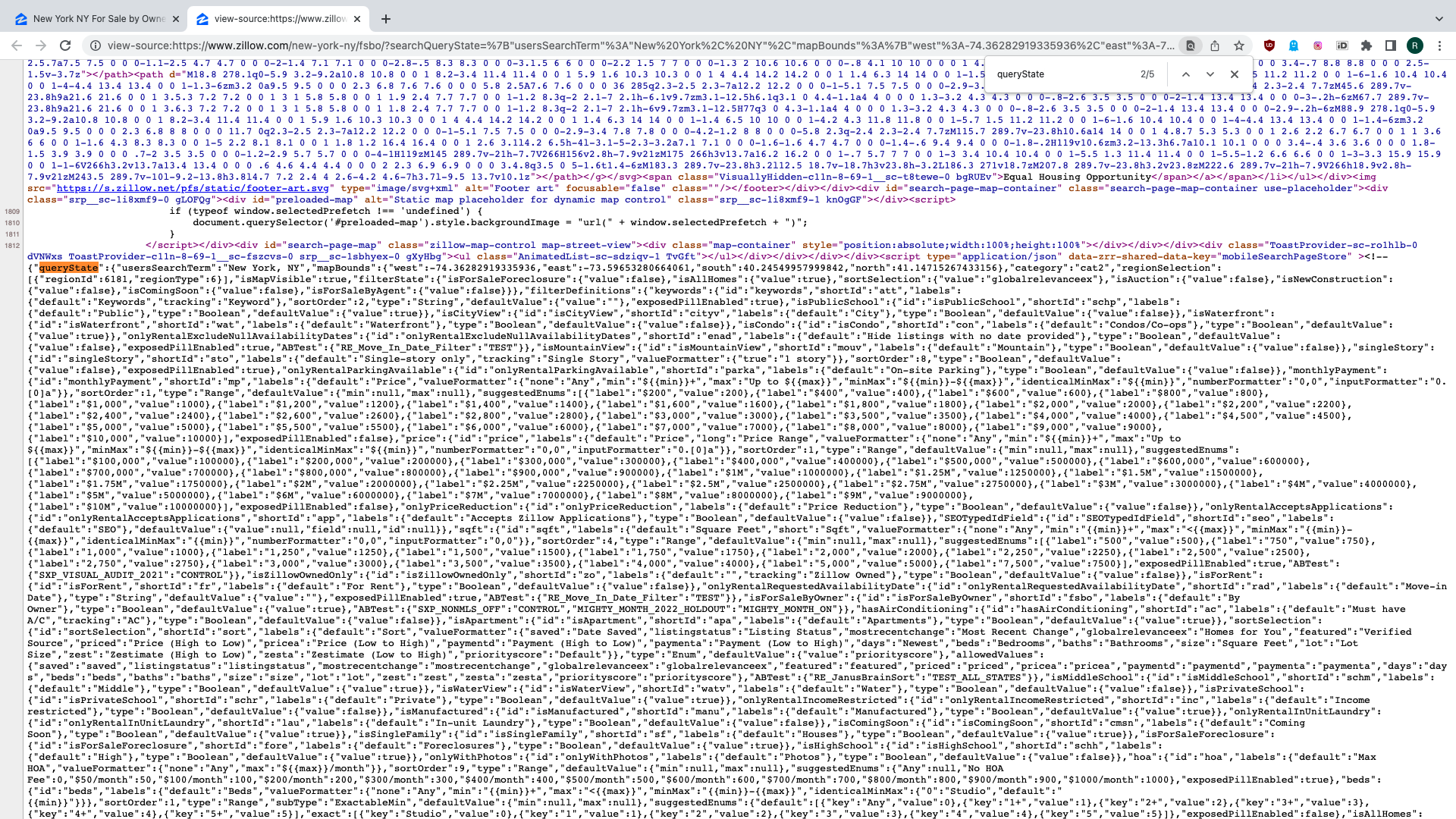
To start sending search API requests we need to generate or extract the
searchQueryState parameter. Turns out, it is available in the HTML of search results
page, assuming it was requested with the proper cookies.
{kind=link}
So the general strategy for scraping Zillow is the following:
- We reproduce the HTTP request for choosing FSBO listings so that proper cookies would be received by our code.
- Load the first (HTML) page of search results to extract the search query state.
- We iterate across all pages of search results by updating the part of search query state that deals with pagination.
- We extract the relevant parts from property detail API response and save them to output file. We also download property images.
In summary, we will be using a hybrid approach that starts with scraping a small piece of information from HTML page to bootstrap private API scraping.
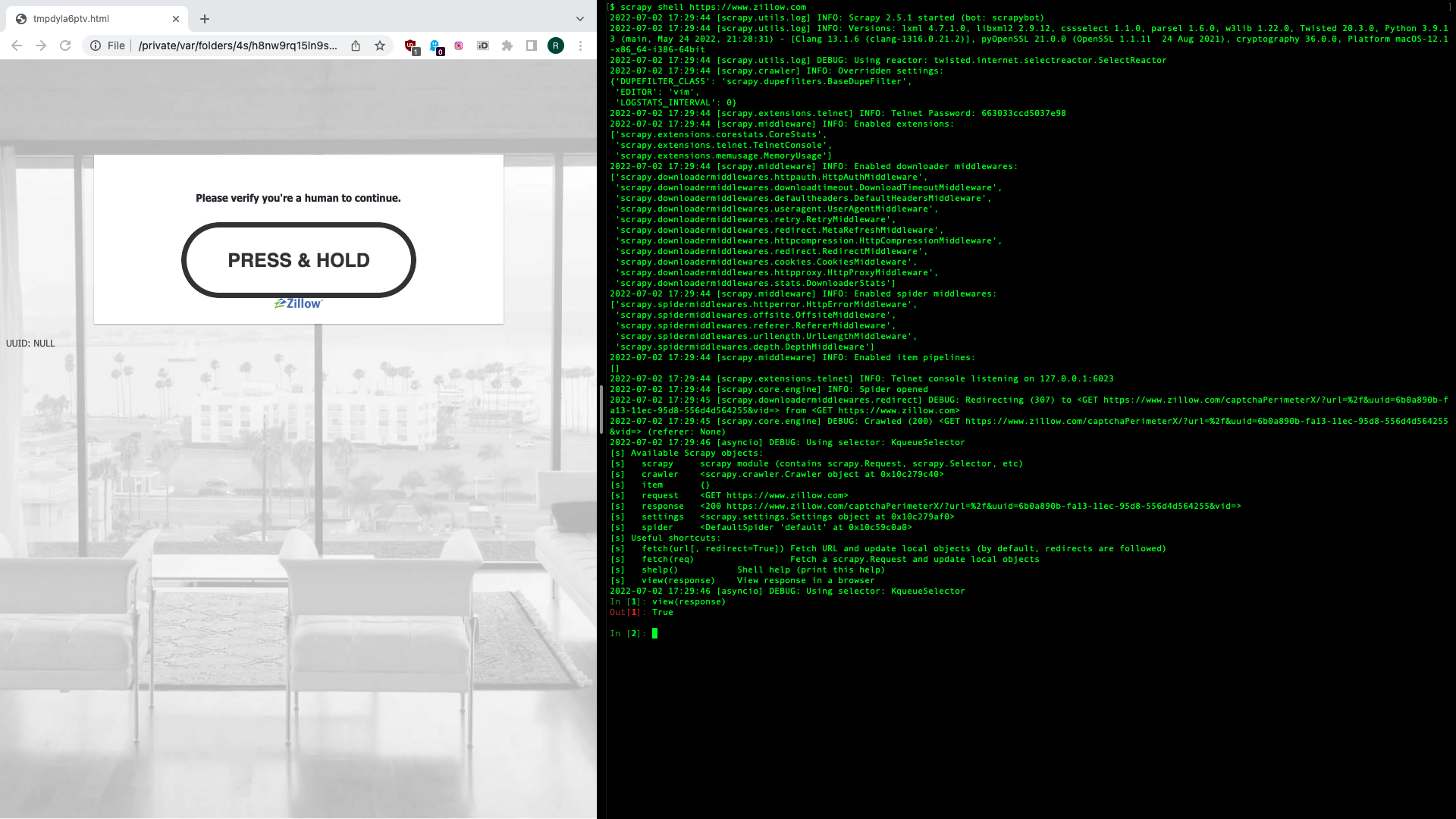
One last thing to consider is blocking evasion. As of 2022, Zillow uses PerimeterX for scraping countermeasures. This can be bypassed by using ISP proxies from Bright Data. We cannot use advanced proxies (such as Web Unlocker from Bright Data) here because they overtake cookie management and would not allow us to pass the cookie we received early in the flow.
{kind=link}
We create a Scrapy project with scrapy genspider command and use Scrapy CLI to create new spider class.
Now let us edit the settings.py file and tell it to disobey robots.txt rules:
ROBOTSTXT_OBEY = False
We also need to override default HTTP headers to make the requests look like they have been sent by a browser:
DEFAULT_REQUEST_HEADERS = {
'authority': 'www.zillow.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'sec-ch-ua': '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'accept-language': 'en-GB,en;q=0.9,en-US;q=0.8,lt;q=0.7',
}
In our spider class we may want to set things up for accepting a list of location search
URLs via command line interface. Since Zillow URLs tend to use commas we will use pipe symbol
for separation. We make a constructor method that takes an optional list of pipe-separated
URLs and sets them to start_urls property after splitting them:
def __init__(self, start_urls=None):
super().__init__()
if start_urls is not None:
self.start_urls = start_urls.split('|')
This enables us to either give a list of URLs via scrapy runspider command or fill them into
web UI in Scrapy Cloud. Scrapy framework ensures that the spider is initialized with the
parameter we passed in when starting a scraping job.
Once spider is inialized and launched by Scrapy framework, start_requests() method will be called.
We don’t proceed with loading pages listed in start_urls property just yet, because we need
to reproduce a step that gets the cookies. If we used requests module we could create a session
object for storing the cookies. That is not needed with Scrapy. We can simply generate a request
into URL that gives us the cookies we need - the default middleware in Scrapy will remember it for us.
def start_requests(self):
fsbo_url = 'https://www.zillow.com/homes/fsbo/'
yield scrapy.Request(fsbo_url, callback=self.start_main_requests)
In the next step we now proceed with loading HTML pages at URLs we got from the user:
def start_main_requests(self, response):
for start_url in self.start_urls:
yield scrapy.Request(start_url, callback=self.parse_property_list_html)
At next callback there’s parse_property_list_html() method that extracts the search query state and generates
the very first API request:
def parse_property_list_html(self, response):
js = response.xpath('//script[contains(text(), "searchQueryState")]/text()').get()
if js is not None:
parsed = js2xml.parse(js)
search_state_url = parsed.xpath('//string[contains(text(), "searchQueryState")]/text()')[0]
params = parse_qs(o.query)
search_query_state_json_str = params['searchQueryState'][0]
else:
json_str = response.xpath('//script[@data-zrr-shared-data-key="mobileSearchPageStore"]/text()').get()
if json_str is None:
self.logger.error("Failed to find search query state")
return
json_str = json_str.replace('<!--', '').replace('-->', '')
json_dict = json.loads(json_str)
search_query_state = json_dict.get('queryState')
search_query_state_json_str = json.dumps(search_query_state)
api_url = self.generate_api_url_from_search_query_state(search_query_state_json_str)
yield scrapy.Request(api_url, callback=self.parse_property_list_json)
There’s two ways to extract the search query state. One is to use XPath query that looks for JavaScript
snippet containing substring searchQueryState, parsing it into tree structure with js2xml module, then digging up
the part we need from there (js2xml is a convenient way to convert JS code into XML trees to run XPath queries against
them). Another approach is finding out a commented out JSON in the HTML, removing the comments, parsing it into Python
dictionary and extracting the part we need from that. Since the API expects search query state in JSON format we JSONify
it back before generating search API request URL. You may notice that we don’t do that in previous codepath. That’s because
the previous case depends on JS code having API URLs hardcoded in them that we can parse and extract searchQueryState
for reusing it. With this appraoch we cover some diversity in how the page might be structured to make the scraper more reliable.
We call a helper method to create a complete URL for the request and yield the request.
At then next callback method we process the search API response by extracting the part that contains search results and iterating across them:
def parse_property_list_json(self, response):
json_str = response.text
json_dict = json.loads(json_str)
search_results = json_dict.get('cat2', dict()).get('searchResults', dict()).get('listResults', [])
for result in search_results:
Only thing we need from here is ZPID - Zillow property ID. We use this to reproduce the request that client side JS code makes to get data for property details page:
zpid = result.get('zpid')
query_id = '4c19ac196fd0f1e7e30ca7e7f9af85d5'
operation_name = 'ForSaleDoubleScrollFullRenderQuery'
url_params = {
'zpid': zpid,
'contactFormRenderParameter': '',
'queryId': query_id,
'operationName': operation_name,
}
json_payload = {
'clientVersion' : "home-details/6.0.11.5970.master.8d248cb",
'operationName' : operation_name,
'queryId' : query_id,
'variables' : {
'contactFormRenderParameter' : {
'isDoubleScroll' : True,
'platform' : 'desktop',
'zpid' : zpid,
},
'zpid' : zpid
}
}
api_url = 'https://www.zillow.com/graphql/?' + urlencode(url_params)
yield JsonRequest(url=api_url, data=json_payload, callback=self.parse_property_page_json)
Since we need to pass JSON payload in the POST request we use JsonRequest class here.
We went through all the results in the current API page, but there might be more pages we may want to scrape.
In the API response there’s a field called nextUrl if further search results are available. It is not present
otherwise. So let us check for the presence of this field:
next_url = json_dict.get('cat2', dict()).get('searchList', dict()).get('pagination', dict()).get('nextUrl')
if next_url is not None:
If we found it, we need to extract old search query state from the URL of the request corresponding to the current
invocation of callback method we are writing and update the currentPage counter in pagination section:
o = urlparse(response.url)
old_params = parse_qs(o.query)
old_search_query_state_json_str = old_params['searchQueryState'][0]
search_query_state = json.loads(old_search_query_state_json_str)
if search_query_state.get('pagination') is None:
search_query_state['pagination'] = {'currentPage': 2}
else:
search_query_state['pagination']['currentPage'] += 1
search_query_state_json_str = json.dumps(search_query_state)
Then we create one more search API request:
api_url = self.generate_api_url_from_search_query_state(search_query_state_json_str)
yield scrapy.request(api_url, callback=self.parse_property_list_json)
When property detail API call succeeds, the parse_property_page_json() method will be called.
But now let us go to items.py file and define a item class for real estate properties we are scraping:
class Property(scrapy.Item):
url = scrapy.Field()
address = scrapy.Field()
city = scrapy.Field()
state = scrapy.Field()
zipcode = scrapy.Field()
price = scrapy.Field()
zestimate = scrapy.Field()
n_bedrooms = scrapy.Field()
n_bathrooms = scrapy.Field()
area = scrapy.Field()
latitude = scrapy.Field()
longitude = scrapy.Field()
phone = scrapy.Field()
# See: https://docs.scrapy.org/en/latest/topics/media-pipeline.html
image_urls = scrapy.Field()
images = scrapy.Field()
There are two fields that are bit special here: image_urls and images. These will be used by image downloading
pipeline bit later. In our spider code, we need to set image_urls to let image pipeline download the pictures.
In parse_property_page_json() we instantiate Property object and use basic Python dictionary operations to
set the relevant fields:
def parse_property_page_json(self, response):
json_dict = json.loads(response.text)
data_dict = json_dict.get('data', dict())
property_dict = data_dict.get('property')
if property_dict is None:
return
item = Property()
item['url'] = property_dict.get('hdpUrl')
if item.get('url') is not None:
item['url'] = urljoin(response.url, item['url'])
item['address'] = property_dict.get('streetAddress')
item['city'] = property_dict.get('address', dict()).get('city')
item['state'] = property_dict.get('address', dict()).get('state')
item['zipcode'] = property_dict.get('address', dict()).get('zipcode')
item['price'] = property_dict.get('price')
item['zestimate'] = property_dict.get('zestimate')
item['n_bedrooms'] = property_dict.get('bedrooms')
item['n_bathrooms'] = property_dict.get('bathrooms')
item['area'] = property_dict.get('livingArea')
item['latitude'] = property_dict.get('latitude')
item['longitude'] = property_dict.get('longitude')
contact_data_dict = property_dict.get('contactFormRenderData', dict()).get('data', dict())
agent_module = contact_data_dict.get('agent_module')
if agent_module is not None:
phone_dict = agent_module.get('phone')
if phone_dict is not None:
item['phone'] = "({}) {}-{}".format(phone_dict.get('areacode'), phone_dict.get('prefix'), phone_dict.get('number'))
huge_photos = property_dict.get('hugePhotos')
if huge_photos is not None:
item['image_urls'] = list(map(lambda img: img.get('url'), huge_photos))
yield item
Now let us edit settings.py some more to set up the images pipeline. We uncomment the pipelines section and put the images pipeline at the top priority:
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
#'zillow.pipelines.ZillowPipeline': 300,
}
We also set IMAGES_STORE to directory path that images will be saved in after they are downloaded and normalised into
a consistent format (make sure you have PIL installed).
IMAGES_STORE = 'images'
The complete spider code for scraping Zillow properties is as follows:
import scrapy
from scrapy.http import JsonRequest
from urllib.parse import urlparse, parse_qs, urlencode, urljoin
import json
import js2xml
from zillow.items import Property
class HomeSpider(scrapy.Spider):
name = 'home'
allowed_domains = ['zillow.com']
start_urls = [ 'https://www.zillow.com/homes/NY_rb/' ]
request_id = 1
def __init__(self, start_urls=None):
super().__init__()
if start_urls is not None:
self.start_urls = start_urls.split('|')
def start_requests(self):
fsbo_url = 'https://www.zillow.com/homes/fsbo/'
yield scrapy.Request(fsbo_url, callback=self.start_main_requests)
def start_main_requests(self, response):
for start_url in self.start_urls:
yield scrapy.Request(start_url, callback=self.parse_property_list_html)
def generate_api_url_from_search_query_state(self, search_query_state_json_str):
wants = {
'cat1' : ['total'],
'cat2' : ['listResults']
}
wants_json_str = json.dumps(wants)
new_params = {
'searchQueryState' : search_query_state_json_str,
'wants' : wants_json_str,
'requestId' : self.request_id,
}
api_url = 'https://www.zillow.com/search/GetSearchPageState.htm?' + urlencode(new_params)
self.request_id += 1
return api_url
def parse_property_list_html(self, response):
js = response.xpath('//script[contains(text(), "searchQueryState")]/text()').get()
if js is not None:
parsed = js2xml.parse(js)
search_state_url = parsed.xpath('//string[contains(text(), "searchQueryState")]/text()')[0]
params = parse_qs(o.query)
search_query_state_json_str = params['searchQueryState'][0]
else:
json_str = response.xpath('//script[@data-zrr-shared-data-key="mobileSearchPageStore"]/text()').get()
if json_str is None:
self.logger.error("Failed to find search query state")
return
json_str = json_str.replace('<!--', '').replace('-->', '')
json_dict = json.loads(json_str)
search_query_state = json_dict.get('queryState')
search_query_state_json_str = json.dumps(search_query_state)
api_url = self.generate_api_url_from_search_query_state(search_query_state_json_str)
yield scrapy.Request(api_url, callback=self.parse_property_list_json)
def parse_property_list_json(self, response):
json_str = response.text
json_dict = json.loads(json_str)
search_results = json_dict.get('cat2', dict()).get('searchResults', dict()).get('listResults', [])
for result in search_results:
zpid = result.get('zpid')
query_id = '4c19ac196fd0f1e7e30ca7e7f9af85d5'
operation_name = 'ForSaleDoubleScrollFullRenderQuery'
url_params = {
'zpid': zpid,
'contactFormRenderParameter': '',
'queryId': query_id,
'operationName': operation_name,
}
json_payload = {
'clientVersion' : "home-details/6.0.11.5970.master.8d248cb",
'operationName' : operation_name,
'queryId' : query_id,
'variables' : {
'contactFormRenderParameter' : {
'isDoubleScroll' : True,
'platform' : 'desktop',
'zpid' : zpid,
},
'zpid' : zpid
}
}
api_url = 'https://www.zillow.com/graphql/?' + urlencode(url_params)
yield JsonRequest(url=api_url, data=json_payload, callback=self.parse_property_page_json)
next_url = json_dict.get('cat2', dict()).get('searchList', dict()).get('pagination', dict()).get('nextUrl')
if next_url is not None:
o = urlparse(response.url)
old_params = parse_qs(o.query)
old_search_query_state_json_str = old_params['searchQueryState'][0]
search_query_state = json.loads(old_search_query_state_json_str)
if search_query_state.get('pagination') is None:
search_query_state['pagination'] = {'currentPage': 2}
else:
search_query_state['pagination']['currentPage'] += 1
search_query_state_json_str = json.dumps(search_query_state)
api_url = self.generate_api_url_from_search_query_state(search_query_state_json_str)
yield scrapy.request(api_url, callback=self.parse_property_list_json)
def parse_property_page_json(self, response):
json_dict = json.loads(response.text)
data_dict = json_dict.get('data', dict())
property_dict = data_dict.get('property')
if property_dict is None:
return
item = Property()
item['url'] = property_dict.get('hdpUrl')
if item.get('url') is not None:
item['url'] = urljoin(response.url, item['url'])
item['address'] = property_dict.get('streetAddress')
item['city'] = property_dict.get('address', dict()).get('city')
item['state'] = property_dict.get('address', dict()).get('state')
item['zipcode'] = property_dict.get('address', dict()).get('zipcode')
item['price'] = property_dict.get('price')
item['zestimate'] = property_dict.get('zestimate')
item['n_bedrooms'] = property_dict.get('bedrooms')
item['n_bathrooms'] = property_dict.get('bathrooms')
item['area'] = property_dict.get('livingArea')
item['latitude'] = property_dict.get('latitude')
item['longitude'] = property_dict.get('longitude')
contact_data_dict = property_dict.get('contactFormRenderData', dict()).get('data', dict())
agent_module = contact_data_dict.get('agent_module')
if agent_module is not None:
phone_dict = agent_module.get('phone')
if phone_dict is not None:
item['phone'] = "({}) {}-{}".format(phone_dict.get('areacode'), phone_dict.get('prefix'), phone_dict.get('number'))
huge_photos = property_dict.get('hugePhotos')
if huge_photos is not None:
item['image_urls'] = list(map(lambda img: img.get('url'), huge_photos))
yield item