Many websites do not provide proper access to information for unauthenticated users. Instead, the data is provided on some client area that is accessible only after the user goes through login flow, possibly by signing up for a paid plan beforehand. How can such websites be scraped with Python?
There are two additional things we have to do when scraping data behind login:
- Set up
requests.Sessionobject with proper cookies by reproducing the login flow programmatically. - Using the session from previous step to scrape data behind login.
Depending on the specifics of the site being scraped, we may also need to set up Authorization header with API access token.
To exemplify scraping behind login, we will develop a simple company information scraper for Apollo.io - a SaaS tool for sales intelligence and outreach automation. This site is heavily reliant on API calls made by client-side JS code, but the approach demonstrated here is applicable for pure HTML sites as well.
Reproducing login flow
The following assumes that we have a free account at Apollo.io.
Let us explore login flow of the site. We need to go to login page of the site and switch on Chrome DevTools. Make
sure to clear request history in Network tab. Then perform the login with credentials you have. You will find that
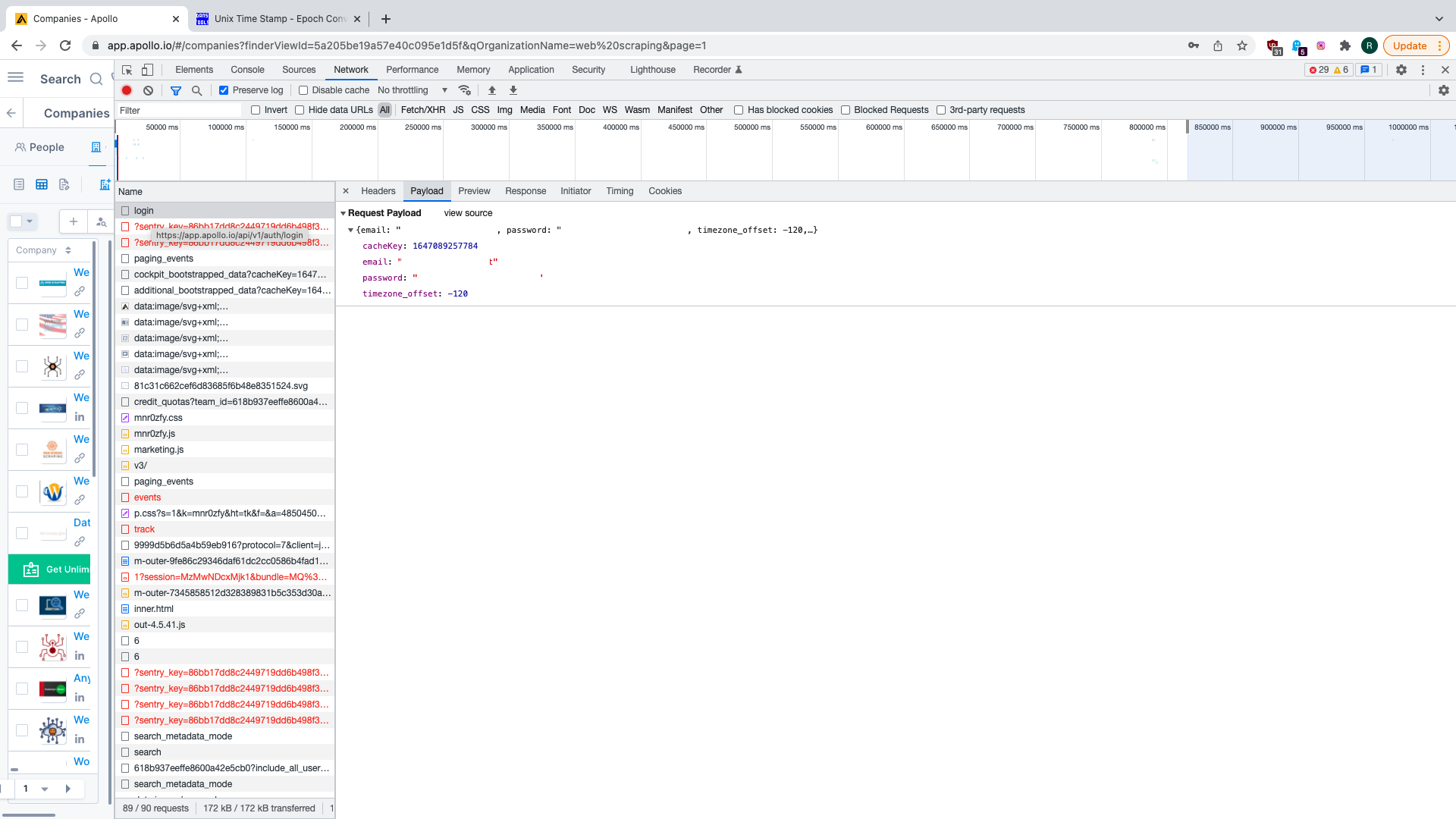
HTTP POST request is being sent to https://app.apollo.io/api/v1/auth/login with JSON payload containing the following
key-value pairs:
emailandpassword- email and password for your account.timezone_offset- timezone offset in minutes; does not seem to matter much.cacheKey- UNIX time of request.
You will also find that the request has some cookies from before. It also has x-csrf-token header. At first glance it
may seem that these things make it more complicated to reproduce the login step, but a quick experiment with curl snippet
copied from Chrome DevTools shows that we can safely remove them and still have a working request. However, it is important
that request looks like it came from actual browser and thus we should keep rest of the headers.
{kind=link}
Let us write a function that creates a session object based on what we have discovered:
import requests
def create_session(username, password):
session = requests.Session()
session.headers = {
'authority': 'app.apollo.io',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="98", "Google Chrome";v="98"',
'sec-ch-ua-mobile': '?0',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36',
'sec-ch-ua-platform': '"macOS"',
'accept': '*/*',
'origin': 'https://app.apollo.io',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://app.apollo.io/',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
json_data = {
'email': username,
'password': password,
'timezone_offset': 0,
'cacheKey': int(time.time()),
}
response = session.post('https://app.apollo.io/api/v1/auth/login', json=json_data)
print(response.url)
return session
The session object keeps track of headers and cookies between requests and enables us to set up the initial state once and not to worry about it later. Later in the code we will be making further API requests through this object.
Using the session with cookies
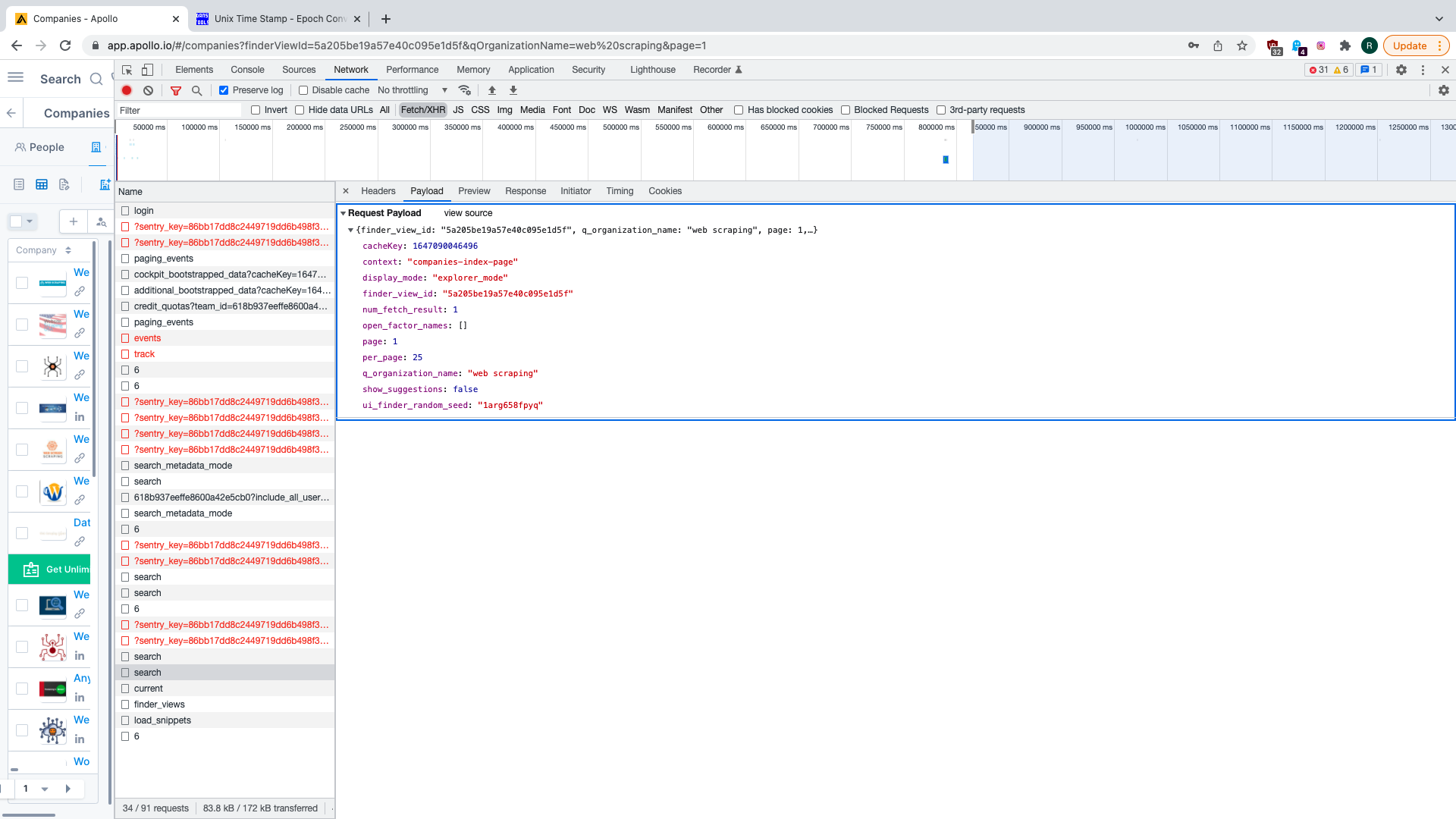
Let us explore further. In the client area, choose Companies tab and search for something. You will find that further API
requests are made. We find that some of them are made to /api/v1/mixed_companies/search with JSON payload containing
our search query at key q_organization_name. We also have page key-value pair for page number (starting from 1) and
something called display_mode - this has to be set to explorer_mode to let us retrieve all data search API gives us,
not just metadata.
{kind=link}
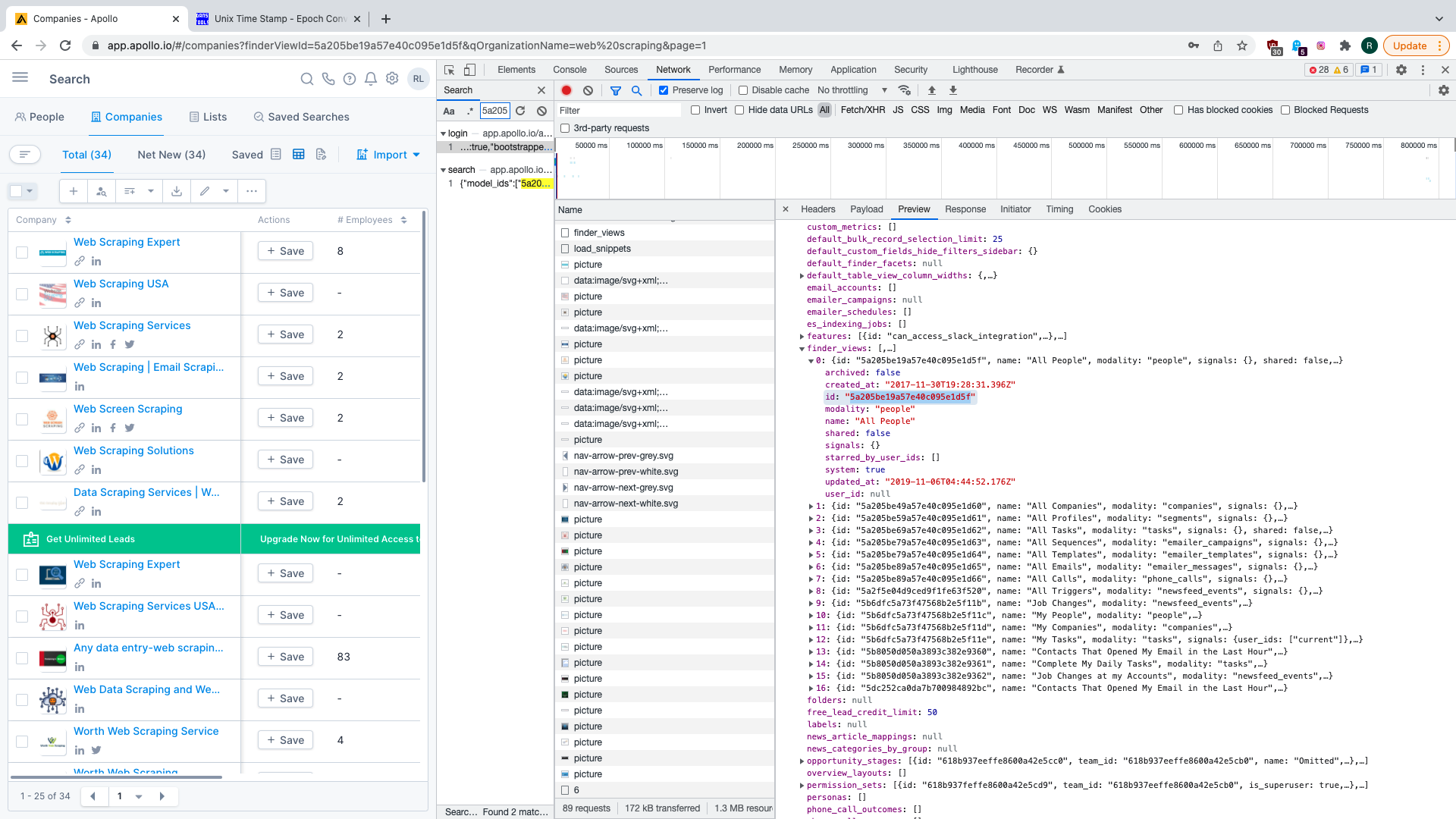
There is also something called finder_view_id which we can also find at various points earlier in the flow. The easiest
and earliest way to get this value is to dig it out of API response that we get at the login step.
{kind=link}
Thus we modify create_session() to do so and return it as a tuple with session object:
json_dict = response.json()
view_id = (
json_dict.get("bootstrapped_data", dict()).get("finder_views")[0].get("id")
)
return session, view_id
No we are ready to reproduce company search API calls, but we need to ask the user for search query and output file path. The complete script that logs in and performs Apollo.io private API scraping for company data (name, phone number, some URLs) is as follows:
#!/usr/bin/python3
import csv
from pprint import pprint
import time
import string
import random
import requests
def create_session(username, password):
session = requests.Session()
session.headers = {
"authority": "app.apollo.io",
"sec-ch-ua": '" Not A;Brand";v="99", "Chromium";v="98", "Google Chrome";v="98"',
"sec-ch-ua-mobile": "?0",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36",
"sec-ch-ua-platform": '"macOS"',
"accept": "*/*",
"origin": "https://app.apollo.io",
"sec-fetch-site": "same-origin",
"sec-fetch-mode": "cors",
"sec-fetch-dest": "empty",
"referer": "https://app.apollo.io/",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
}
json_data = {
"email": username,
"password": password,
"timezone_offset": 0,
"cacheKey": int(time.time()),
}
pprint(json_data)
response = session.post("https://app.apollo.io/api/v1/auth/login", json=json_data)
print(response.url)
json_dict = response.json()
view_id = (
json_dict.get("bootstrapped_data", dict()).get("finder_views")[0].get("id")
)
return session, view_id
def scrape_company_data(session, view_id, query, output_csv_path):
page = 1
json_data = {
"finder_view_id": view_id,
"q_organization_name": query,
"page": page,
"display_mode": "explorer_mode",
"per_page": 25,
"open_factor_names": [],
"num_fetch_result": 1,
"context": "companies-index-page",
"show_suggestions": False,
# Based on:
# https://stackoverflow.com/questions/2257441/random-string-generation-with-upper-case-letters-and-digits
"ui_finder_random_seed": "".join(
random.choice(string.ascii_lowercase + string.digits) for _ in range(6)
),
"cacheKey": int(time.time()),
}
out_f = open(output_csv_path, "w", encoding="utf-8")
csv_writer = csv.DictWriter(
out_f,
fieldnames=["name", "linkedin_url", "website_url", "primary_domain", "phone"],
lineterminator="\n",
)
csv_writer.writeheader()
while True:
resp = session.post(
"https://app.apollo.io/api/v1/mixed_companies/search", json=json_data
)
print(resp.url)
json_dict = resp.json()
for org_dict in json_dict.get("organizations", []):
name = org_dict.get("name")
linkedin_url = org_dict.get("linkedin_url")
website_url = org_dict.get("website_url")
primary_domain = org_dict.get("primary_domain")
phone = org_dict.get("phone")
row = {
"name": name,
"linkedin_url": linkedin_url,
"website_url": website_url,
"primary_domain": primary_domain,
"phone": phone,
}
pprint(row)
csv_writer.writerow(row)
pagination_dict = json_dict.get("pagination")
total_pages = pagination_dict.get("total_pages")
if total_pages == page:
break
page += 1
json_data["page"] = page
out_f.close()
def main():
username = input("Username: ")
password = input("Password: ")
query = input("Search query: ")
output_csv_path = input("Output CSV path: ")
session, view_id = create_session(username, password)
print(session.cookies)
scrape_company_data(session, view_id, query, output_csv_path)
if __name__ == "__main__":
main()