Not every website wants to let the data to be scraped and not every app wants to allow automation of user activity. If you work in scraping and automation at any capacity you certainly have dealt with sites that work just fine when accessed through normal browser throwing captchas or error pages at your bot. There are multiple security mechanisms that can cause this to happen. Today we will do a broad review of automation countermeasures that can be implemented at various levels.
IP level
The following techniques work at Internet Protocol level by allowing or blocking traffic based on source IP address it is coming from.
Geofencing
Geofencing (or geo-restricting/geo-blocking) is blocking/allowing requests based on source geographic location (typically a country). This relies on GeoIP data provided by vendors such as MaxMind or IP2Location to perform lookups.
{kind=link}
As web scraper developer you can trivially bypass this using proxies.
Rate limiting
Web sites may impose upper bounds on on how many requests are allowed per some timeframe from a single IP and start blocking incoming traffic if traffic intensity exceeds that threshold. This is typically implemented with a leaky bucket algorithm. Suppose the site allows 60 requests per minute from a single IP (i.e. one per seconds). It keeps a counter of how many requests it received, decreasing it by one every second. If the counter exceeds the threshold value (60) the site refuses further requests until it is below the threshold again. This limits how aggressive we can be when scraping, but typically can be defeated by spreading the traffic around a set of IP addresses by routing it through proxy pool.
Filtering by AS/ISP
This can be seen as a variation of geofencing, but blocking can also be performed based on source ISP or Autonomous System by performing Autonomous System Lookups. For example, sites or antibot vendors may explicitly disallow traffic that comes from data centers or major cloud vendors (AWS, Digital Ocean, Azure and so on).
Filtering by IP reputation
Proxies can be used to bypass the above ways to block traffic, but blocking can also be performed based on IP address reputation data from threat intelligence vendors like IPQualityScore. So if your proxy provider is a sketchy one that is built on foundation of botnet it’s proxies may be listed in some blacklist, which makes the trust score bad. One must take care to use a reputable proxy provider.
HTTPS level
The following techniques work at HTTP and TLS protocol levels.
HTTP headers and cookies
The very simplest way to know that traffic is automated is to check User-Agent
header in HTTP request. For example, curl puts something like curl/8.0.1 in
there and some headless browsers actually let the server to know they are
running in headless mode (unless configured otherwise). But that’s trivial
to defeat by just reproducing the header value programmatically.
One baby step further is to not only check the User-Agent header,
but also other request headers to make sure like the ones in the browser in
aggregate. This is also easy to defeat by reproducing all the headers in a
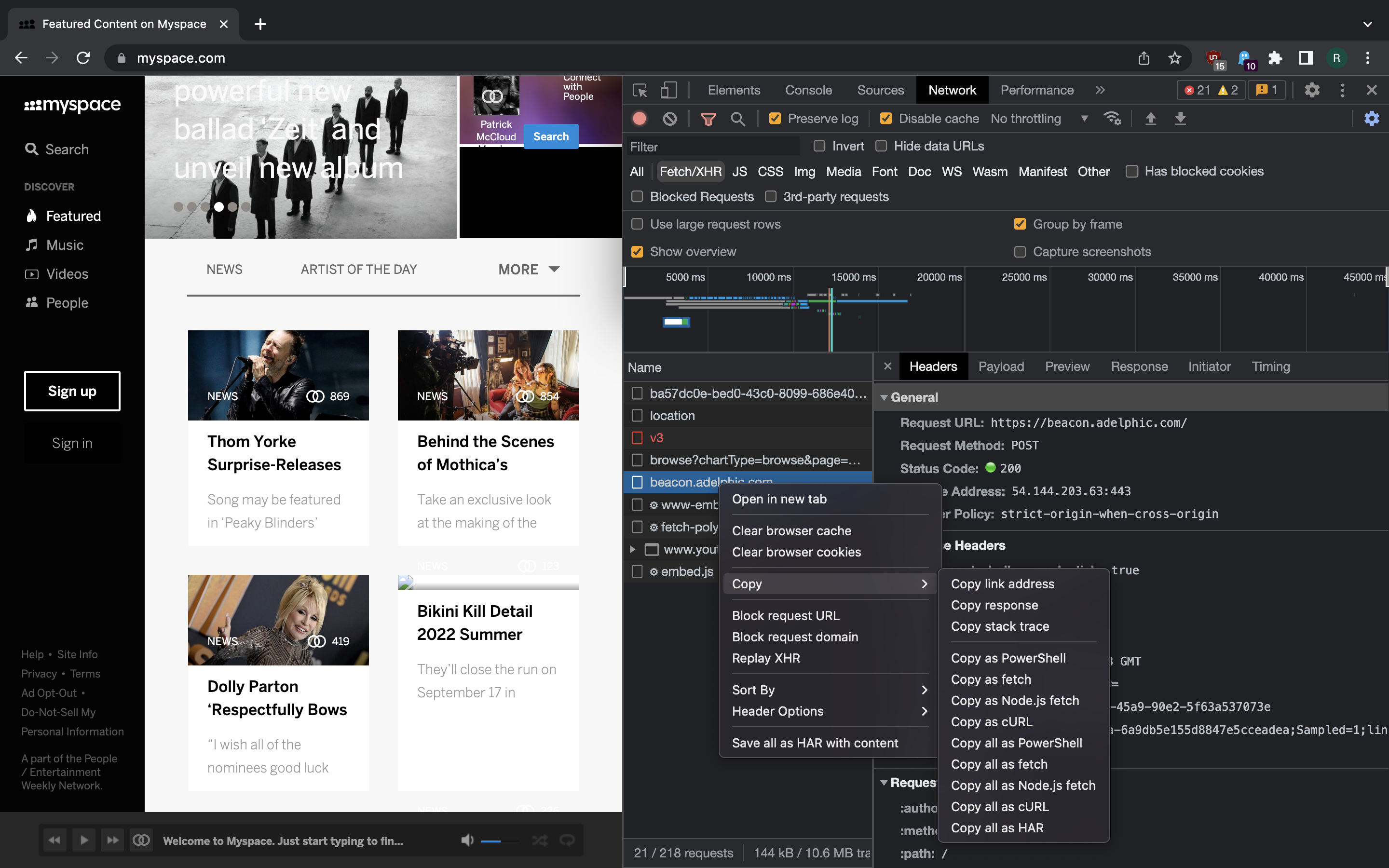
request. In fact, Chrome DevTools Network tab has a handy feature of letting you
conveniently copy a request as a curl command or JavaScript (or even PowerShell!)
snippet.
{kind=link}
Cookies also matter when it comes to dealing with sites that are hostile to
automation, as cookieless requests might get rejected. Depending on exact
specifics of the site, getting the cookies might be as easy as just loading
the front page with requests.Session or it might involve more elaborate
trickery if antibot vendor or captcha service is issuing them based on browser
assesment and user activity (more on that later).
HTTP/2 fingerprinting
We covered the simple stuff, now lets get to something more complicated - HTTP/2 fingerprinting. HTTP/2 is quite complex binary protocol that leaves quite a bit of wiggle room to implementor. The way it is implemented in curl is different than implementation in Google Chrome (altough both are RFC-compliant). Traffic generated by each implementation can reliably betray what kind of implementation it is to the server, CDN or WAF. I have covered this in greated detail in another post earlier.
TLS fingerprinting
HTTP/2 is pretty much never used in plaintext form. After all, you cannot let the dirty people from NSA to just watch the unencrypted traffic without any problems. However, TLS protocol is also very complex. It involves a great deal of technical details in the client traffic (protocol version, list of extensions, proposed cryptographic protocols, etc.) that betray what kind of client software it comes from. In fact, a single ClientHello message can be used to quite reliably predict the OS and browser that generated it. There’s also post earlier in this blog to cover this topic in greater detail.
Application level
The following techniques deal with probing the client-side environment (typically a web browser) to detect and/or prevent automation.
JS environment checking
Modern web browsers are extremely complex software systems. They’re not just user-facing applications to load some pages from remote servers anymore. As of 2023, Chrome or Firefox contains an entire programmable environment for client side software development that is primarily done in JS or variants thereof (that end up being transpiled into JS anyway). Naturally this means that there’s quite a bit of stuff in the JavaScript environment that sites can check for tell-tale signs of browser being controlled programmatically by automation software like like Selenium, Playwright or Puppetteer.
Some examples:
navigator.webdriver=truegenerally betrays browser automation.- Presence of
document.$cdc_asdjflasutopfhvcZLmcfl_object betrays Selenium. - On Chromium-based browsers,
window.chromeobject not being available means the browser is running in headless mode.
Browser and device fingerprinting
Other than aforementioned tell-tale signs of automation, client side JS code can gather a great deal of information on the system it is running on: installed fonts, screen resolution, supported browser features, hardware components and so on. Each of them is a trait of hardware-software setup the code is running on. Furthermore, exact rendering of graphics (through HTML canvas or WebGL API) is dependent on hardware/software setup, i.e. Chrome on macOS/Apple Silicon will not render the exact same image as Firefox on Linux/x86 - some pixels will be slightly, but consistently off, which is another piece of information that can be kept track of. A collection of these traits is referred to as fingerprint.
Fingerprinting is part of anti-automation toolkit. For example, social media apps are able to detect when login session is launched from a new devide vs. the same device being used for new user session. Furthermore, it can be quite telling when a cluster of accounts share the same fingerprint (in the case of e.g. device farm or fully virtualised botting operation).
Javascript challenges
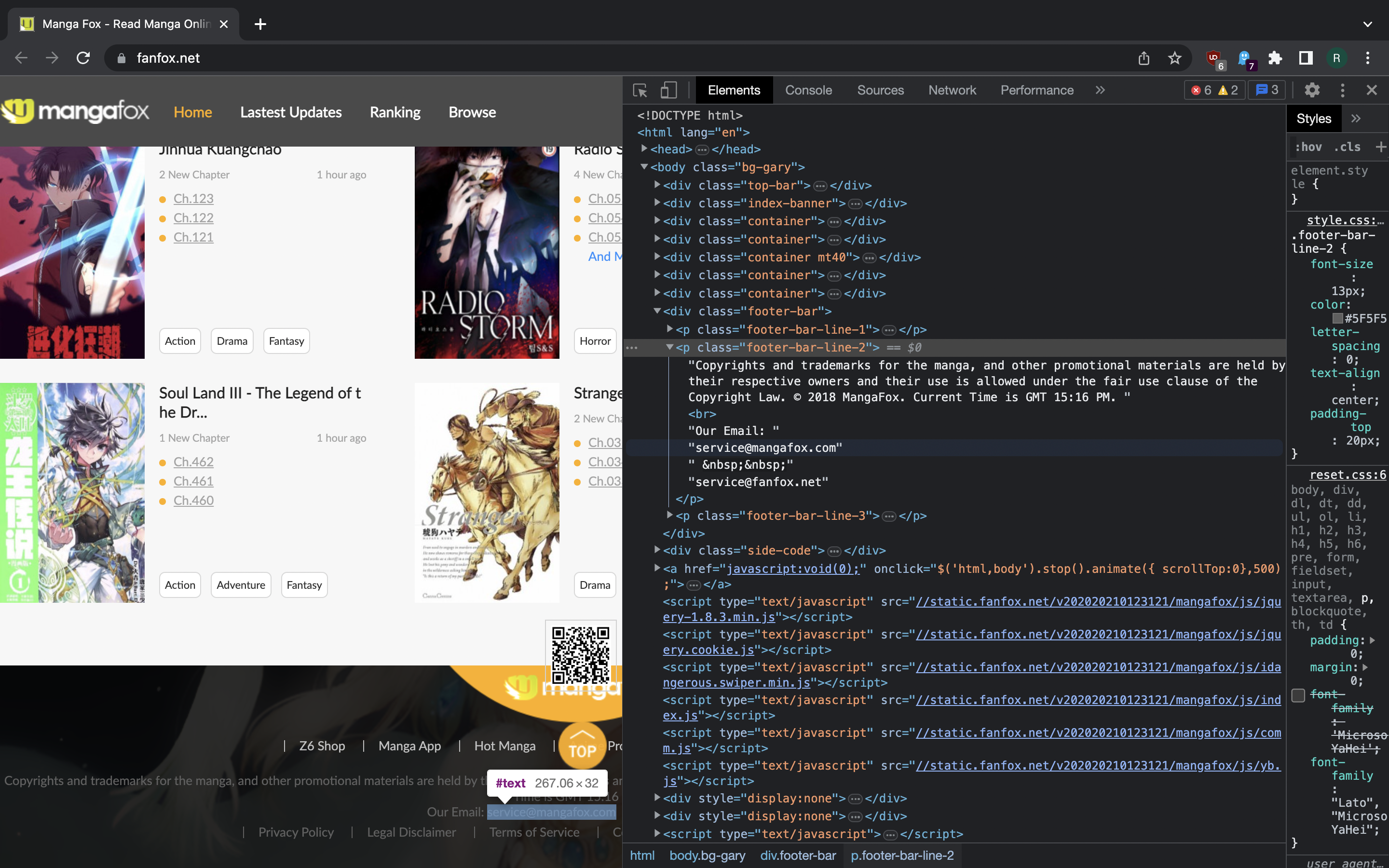
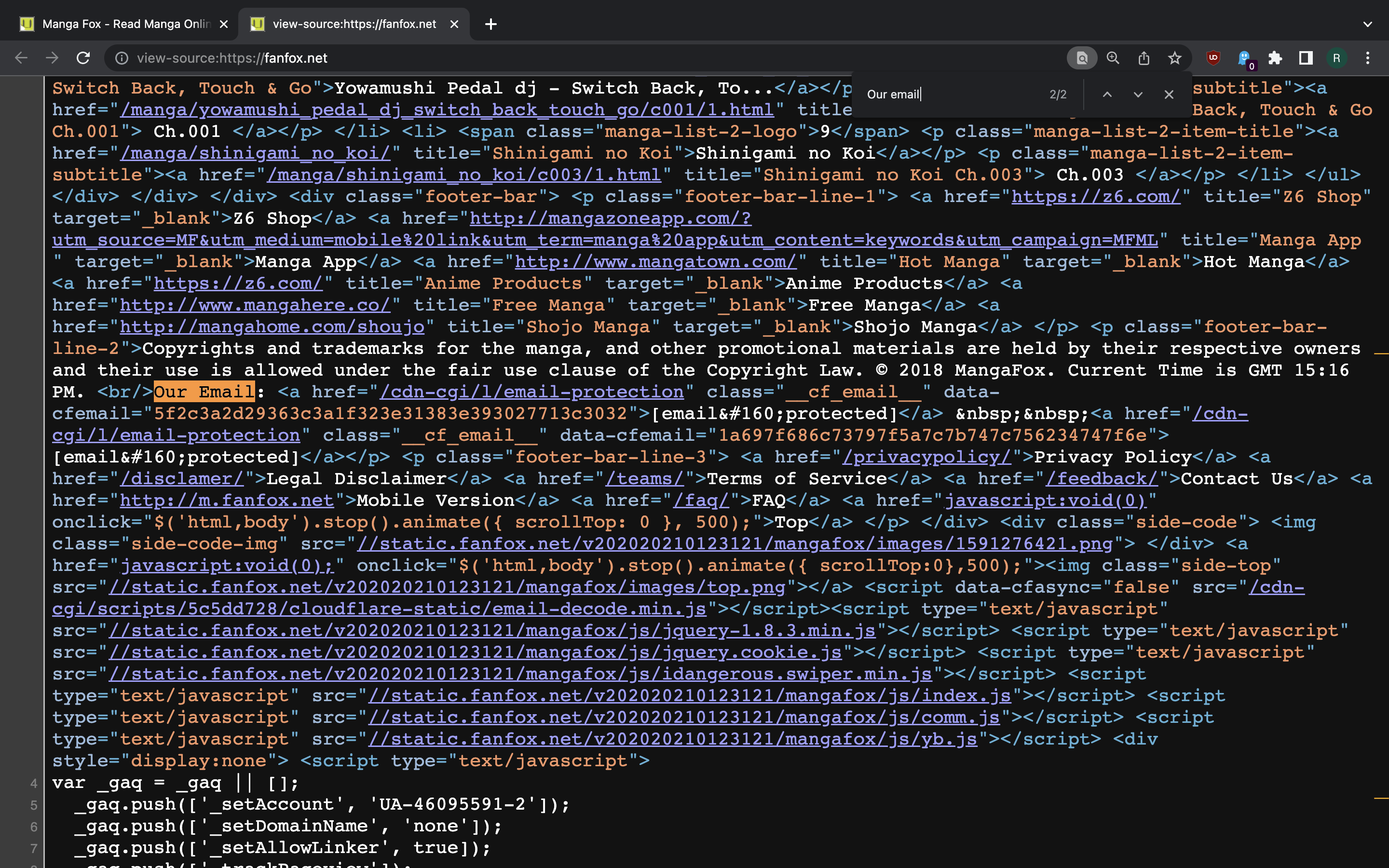
To make requests-based bots harder to implement, site may want to check if client is capable of running Javascript before giving the data. For example, Cloudflare has an Email Address Obfuscation feature that relies on client-side JS code running in the browser to convert the email address from encoded form in the HTML document your browser gets from CDN to the normal form. Notice the difference between what you see in Elements tab of Chrome DevTools and in the original page source for the page of site using this feature.
{kind=link}
{kind=link}
For this particular example of data obfuscation, there’s a Stack Overflow answer providing a small Python snippet to decode it back. However, if you are doing requests-based scraping and rely on regular expressions to extract email addresses this sort of stuff can already cause at least some difficulty.
Furthermore, JS challenges can be more elaborate than this. Depending on how Cloudflare’s antibot features are configured browser may be required to run some JS code with cryptographic proof of work stuff, provide the result of the computation to CF and only then get the cookie that allows it to properly access anything on the site.
User level
The following techniques involve behavioural tracking of user activity, checking that the user is actually human and leveraging user identitities (accounts) to fight automation.
CAPTCHA
A captcha is often (but not always) an incovenient silly puzzle that you have to solve to prove you’re not a robot by picking the segments containing certain object or something like that. That’s a visible captcha. Some captchas (e.g. reCaptcha v3) are invisible - they work in background tracking user activity (mouse movement, etc.) to assess if it looks human or robotic. The puzzle UI is displayed only when there is a suspicion that user is a bot.
The underlying idea for this is that certain tasks are difficult to do programmatically, but easy to do for a person.
Account-level throttling
A simple way to hinder automation is to rate-limit user activity per account. This is commonly done by social media platforms. If user activity exceeds the rate limits the site/app can simply reject the requests or even ban the account.
Account banning
No suprise here - ban hammer is part of anti-automation arsenal as well. Misbehaving accounts can be banned. This is of particular importance to social media automation - an account ban can mean a setback or even outright failure of social media growth hacking efforts.
Making account creation difficult
Banning and throttling user accounts would not help much if it’s possible to create a lot of them quickly. Thus making account creation difficult to automate (by requiring phone verification, integrating third party antibot solutions, making request flows hard to reproduce) is one more thing that sites/apps can do to fight automation.
Realistically, it is near impossible to completely prevent botting if there’s an a sufficient incentive for people to engage in automation. However, the economic feasibility of automation can be weakened by putting barriers that make it more expensive such as phone or ID verification for new accounts and rate-limiting/restricting/banning existing accounts for sketchy, anomalous activity.
Mouse activity monitoring
Client-side JS code can monitor mouse movements and submit them to some neural network running on the backend to assess if they look human or not. This is performed not only by some captcha solutions, but also antibot vendors as well. For example, Akamai Bot Manager phones back a sample of user’s mouse movement as part of clearance cookie issuance flow.