Elasticsearch is open source server software that acts both as database and search engine, based on Apache Lucene library. It can be used to build distributed clusters for indexing and searching Enterprise-level amounts of data. Some sites that present large, searchable, mostly-textual datasets to the end user are based on elasticsearch as their backend data store and have frontend code talking directly to the API of elasticsearch. If the frontend can talk directly to elasticsearch, so can we as web scraper developers with all the benefits the flexible data search engine can bring. A specific example is the website of Carnegie Museum of Art. To see how the trick works, we will be scraping this site today.
If we go to collection.carnegieart.org with web browser we see a list of of various objects being presented with search icon on the upper right corner of the page. Loading this page relies on elasticsearch API, as can be seen in Network tab of Chrome DevTools.
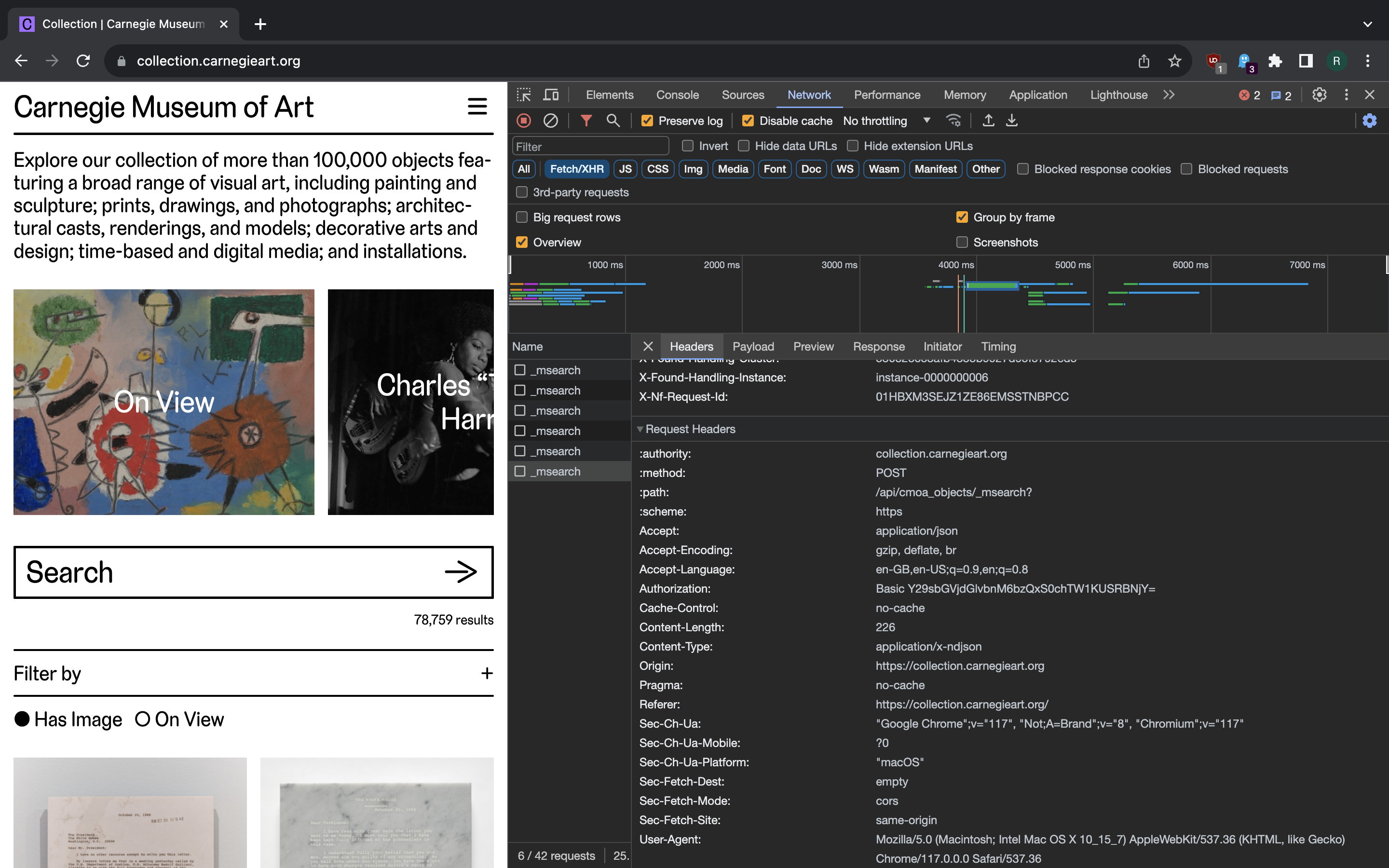
For instance, the following request (represented by curl snippet) fetches the first page worth of data:
curl 'https://collection.carnegieart.org/api/cmoa_objects/_msearch?' \
-H 'authority: collection.carnegieart.org' \
-H 'accept: application/json' \
-H 'accept-language: en-GB,en-US;q=0.9,en;q=0.8' \
-H 'authorization: Basic Y29sbGVjdGlvbnM6bzQxS0chTW1KUSRBNjY=' \
-H 'cache-control: no-cache' \
-H 'content-type: application/x-ndjson' \
-H 'origin: https://collection.carnegieart.org' \
-H 'pragma: no-cache' \
-H 'referer: https://collection.carnegieart.org/' \
-H 'sec-ch-ua: "Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: same-origin' \
-H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36' \
--data-raw $'{"preference":"results"}\n{"query":{"bool":{"must":[{"bool":{"must":[{"bool":{"must":[{"term":{"images.permitted":true}},{"exists":{"field":"images.filename"}}]}}]}}]}},"size":24,"sort":[{"acquisition_date":{"order":"desc"}}]}\n' \
--compressed
{kind=link}
{kind=link}
Some things are notable here. A content-type header is application/x-ndjson
which means Newline-Delimited JSON is provided in the POST request payload.
That entails not a single JSON array or object, but a sequence of JSON objects -
one per line. That’s because the Multi search API
is used to populate the pages. Each line (even the last one) must have a newline
at the end. The first line is a search header and provides basic parameters.
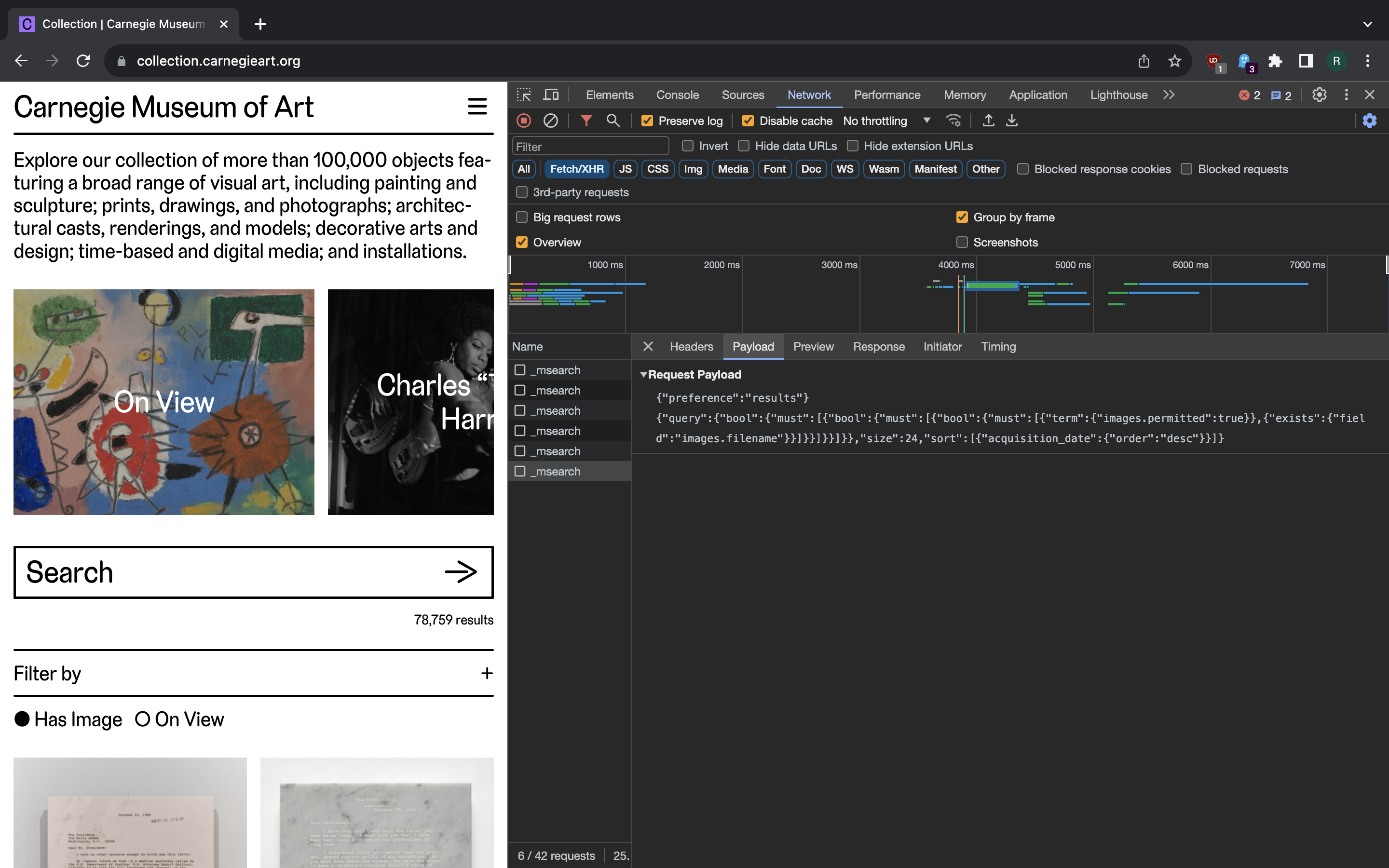
The second line provides a configuration for search query (pretty-printed for
readability):
{
"query": {
"bool": {
"must": [
{
"bool": {
"must": [
{
"bool": {
"must": [
{
"term": {
"images.permitted": true
}
},
{
"exists": {
"field": "images.filename"
}
}
]
}
}
]
}
}
]
}
},
"size": 24,
"sort": [
{
"acquisition_date": {
"order": "desc"
}
}
]
}
At query key we have some nested predicate that basically requires object
images to be available (“Has Images” checkbox is on by default). At size
we have a page size and at sort key we have sorting configuration.
If we go to next page we start having another key here - from that enables
pagination by search result offset.
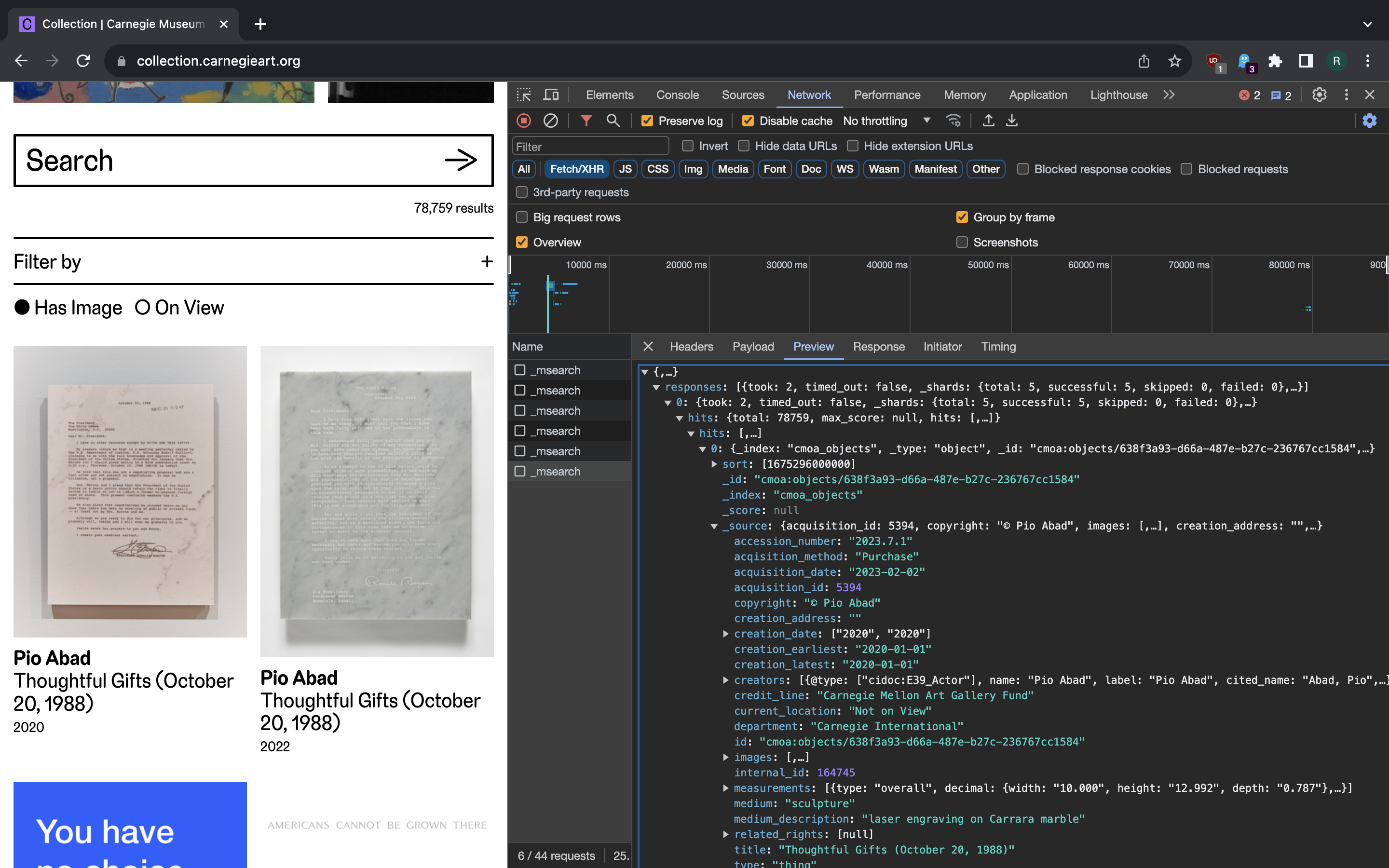
A regular JSON payload is available in the payload of response and has a great deal of information on the museum objects. So the good news is that we don’t need to parse any kind of HTML here and can fully rely on pre-structured data that we can access through elasticsearch API. The entire dataset of Carnegie Museum of Art object catalog can be gathered solely by doing API scraping.
{kind=link}
There is also the authorization header here with Base64-encoded API
credentials. This does not add any security as we can trivally decode the
encoded part of the header and recover the credentials that frontend code
uses:
$ echo "Y29sbGVjdGlvbnM6bzQxS0chTW1KUSRBNjY=" | base64 -d
collections:o41KG!MmJQ$A66
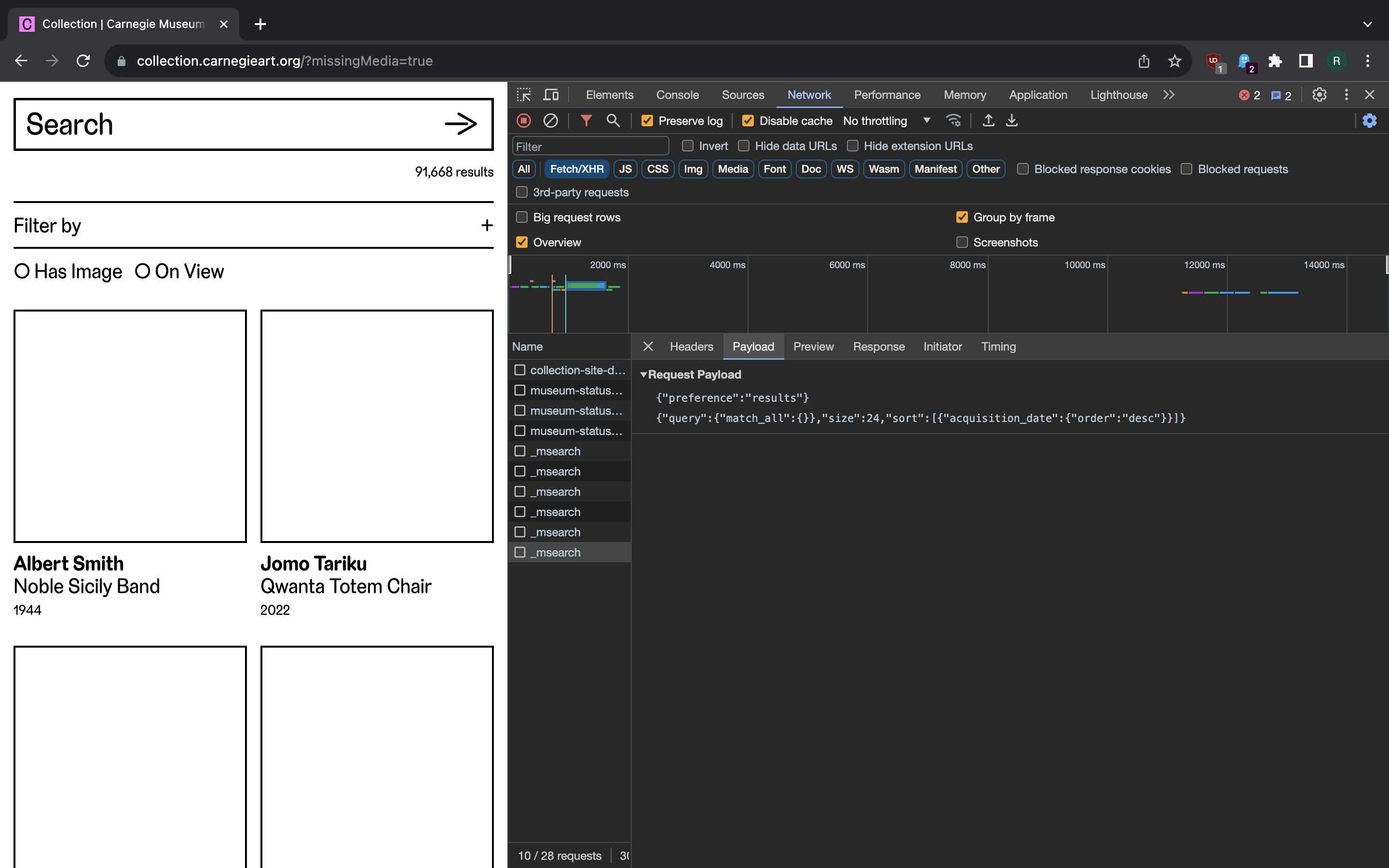
Now, if we uncheck the “Has Image” checkbox the second line in the request payload becomes even simpler:
{
"query": {
"match_all": {}
},
"size": 24,
"sort": [
{
"acquisition_date": {
"order": "desc"
}
}
]
}
{kind=link}
Now the query covers all the data (over 90 000 records!). But there’s a little
problem - the elasticsearch Multi Search API that is used here is not meant to
provide all the search results. For that purpose we will be using the
Scroll API
that is designed to provide a paginated access to search results after the
first (regular, not multiple) Search API request is performed. But first let us
prepare a requests.Session object with the proper headers:
# elasticsearch API credentials:
USERNAME = "collections"
PASSWORD = "o41KG!MmJQ$A66"
def create_session():
session = requests.Session()
session.headers = {
"authority": "collection.carnegieart.org",
"accept": "application/json",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
"cache-control": "no-cache",
"content-type": "application/json",
"origin": "https://collection.carnegieart.org",
"pragma": "no-cache",
"referer": "https://collection.carnegieart.org/",
"sec-ch-ua": '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"macOS"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
}
session.auth = (USERNAME, PASSWORD)
return session
session = create_session()
You may notice that the content type we say we’re using is application/json -
a regular JSON format, not the multiline variant. That’s because we will be
using slightly different APIs than what the site frontend relies on.
When launching the first search request for the first page, we provide a scroll
URL parameter with some duration that we want the search results to be retained
for between requests:
def scrape(session):
json_payload = {
"query": {"match_all": dict()},
"size": 24,
"from": 0,
"sort": [{"acquisition_date": {"order": "desc"}}],
}
params = {"scroll": "1m"}
resp0 = session.post(
"https://collection.carnegieart.org/api/cmoa_objects/_search",
json=json_payload,
params=params,
)
print(resp0.url)
yield from gen_rows_from_response_payload(resp0.json())
Here 1m stands for 1 minute. This value is known as Scroll Window.
This gives us the first page of the dataset AND a _scroll_id field in the
JSON response that we can use with Scroll API to get further data:
scroll_id = resp0.json().get("_scroll_id")
while scroll_id is not None:
resp = session.get(
"https://collection.carnegieart.org/api/_search/scroll/" + scroll_id,
params=params,
)
print(resp.url)
yield from gen_rows_from_response_payload(resp.json())
hits = resp.json().get("hits", dict()).get("hits", [])
if len(hits) == 0:
break
scroll_id = resp.json().get("_scroll_id")
The generator function gen_rows_from_response_payload() we use here helps with
converting some of the stuff in API response to data rows we can write into
CSV file.
The entire scraper script is as follows:
#!/usr/bin/python3
import csv
import json
from urllib.parse import quote
import requests
# elasticsearch API credentials:
USERNAME = "collections"
PASSWORD = "o41KG!MmJQ$A66"
def create_session():
session = requests.Session()
session.headers = {
"authority": "collection.carnegieart.org",
"accept": "application/json",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
"cache-control": "no-cache",
"content-type": "application/json",
"origin": "https://collection.carnegieart.org",
"pragma": "no-cache",
"referer": "https://collection.carnegieart.org/",
"sec-ch-ua": '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"macOS"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
}
session.auth = (USERNAME, PASSWORD)
return session
def gen_rows_from_response_payload(resp_json):
hits = resp_json.get("hits", dict()).get("hits", [])
for hit_dict in hits:
source_dict = hit_dict.get("_source", dict())
row = dict()
row["title"] = source_dict.get("title")
row["department"] = source_dict.get("department")
row["category"] = source_dict.get("type")
row["current_location"] = source_dict.get("current_location")
row["materials"] = source_dict.get("medium")
row["technique"] = source_dict.get("medium_description")
row["from_location"] = source_dict.get("creation_address")
row["date_description"] = source_dict.get("creation_date")[0]
try:
row["year_start"] = int(source_dict.get("creation_date")[0])
row["year_end"] = int(source_dict.get("creation_date")[-1])
except:
pass
makers = source_dict.get("creators", [])
if makers is not None and len(makers) > 0:
maker_names = list(map(lambda m: m.get("label"), makers))
maker_birth_years = list(map(lambda m: str(m.get("birth", "")), makers))
maker_death_years = list(map(lambda m: str(m.get("death", "")), makers))
maker_genders = list(map(lambda m: str(m.get("gender")), makers))
row["maker_full_name"] = "|".join(maker_names)
row["maker_birth_year"] = "|".join(maker_birth_years).replace("None", "")
row["maker_death_year"] = "|".join(maker_death_years).replace("None", "")
row["maker_gender"] = "|".join(maker_genders).replace("None", "")
try:
row["acquired_year"] = source_dict.get("acquisition_date", "").split("-")[
0
]
except:
pass
row["acquired_from"] = source_dict.get("acquisition_method")
row["accession_number"] = source_dict.get("accession_number")
row["credit_line"] = source_dict.get("credit_line")
row["url"] = "https://collection.carnegieart.org/objects/" + source_dict.get(
"id", ""
).replace("cmoa:objects/", "")
yield row
def scrape(session):
json_payload = {
"query": {"match_all": dict()},
"size": 24,
"from": 0,
"sort": [{"acquisition_date": {"order": "desc"}}],
}
params = {"scroll": "1m"}
resp0 = session.post(
"https://collection.carnegieart.org/api/cmoa_objects/_search",
json=json_payload,
params=params,
)
print(resp0.url)
yield from gen_rows_from_response_payload(resp0.json())
scroll_id = resp0.json().get("_scroll_id")
while scroll_id is not None:
resp = session.get(
"https://collection.carnegieart.org/api/_search/scroll/" + scroll_id,
params=params,
)
print(resp.url)
yield from gen_rows_from_response_payload(resp.json())
hits = resp.json().get("hits", dict()).get("hits", [])
if len(hits) == 0:
break
scroll_id = resp.json().get("_scroll_id")
def main():
session = create_session()
out_f = open("carnegie.csv", "w", encoding="utf-8")
csv_writer = None
for row in scrape(session):
print(row)
if csv_writer is None:
csv_writer = csv.DictWriter(
out_f, fieldnames=list(row.keys()), lineterminator="\n"
)
csv_writer.writeheader()
csv_writer.writerow(row)
if __name__ == "__main__":
main()
You may want to run this through automatically rotating DC proxy pool as there seems to be a little IP-based rate-limiting being done on the server.
Since we have access to the API of elasticsearch database, we can use it to develop unofficial/adversarial integrations by either doing the API calls directly as in above example of by using one of the elasticsearch client libraries. There are two official options for Python:
- elasticsearch-py for bridging the gap between ES API constructs and Python dictionaries.
- elasticsearch-dsl-py for a higher order API that provides a more convenient way to work with database while not straying too far from the JSON-based API.