DALL-E 2 is a cutting edge AI system for creating and manipulating images based on natural language instructions. Although it is not 100% available to the general public yet, it is possible to apply for access by filling a form at OpenAI site. This will place you in a waitlist. I was able to get access after some 20 days. It’s unclear on what basis they choose or prioritise people for access, but my guess is that having spent a few dollars on GPT-3 had helped.
There’s been a lot of hype about DALL-E recently. Some people are posting images that seem almost too good to be true. On the other hand, people are also posting almost carricature level stuff. This post will be a showcase of me playing with DALL-E web interface to see for myself what it can and cannot do.
Let us start with abstract, subjective concepts. Can DALL-E do the work of an artist and make the non-visual visual?
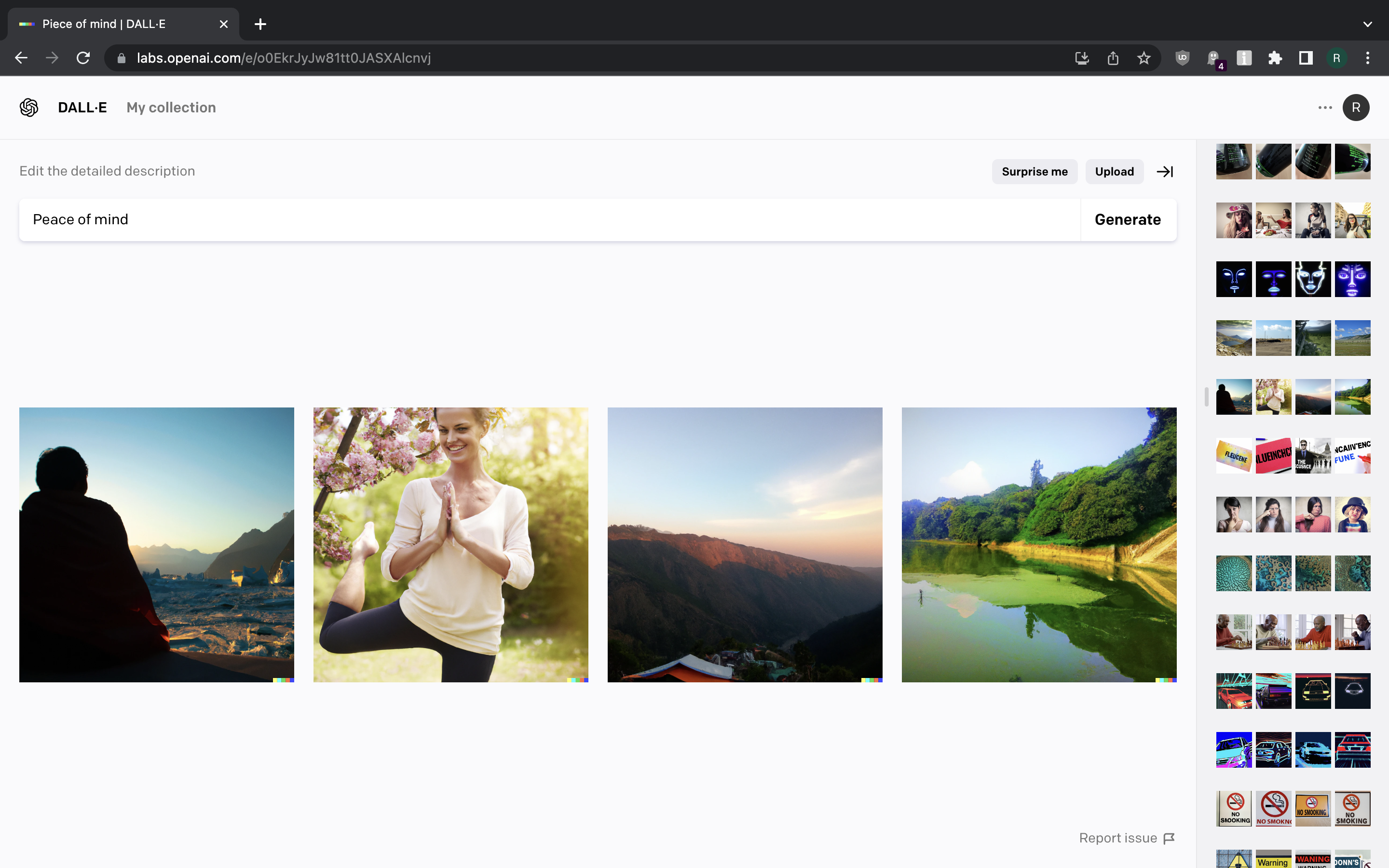
According to DALL-E, “Peace of mind” looks like a lady doing a yoga pose and some nature landscapes.
{kind=link}
That’s passable, I guess, but it looks like stock images. The pictures generated are realistic and look like photographs, but they are also fairly bland.
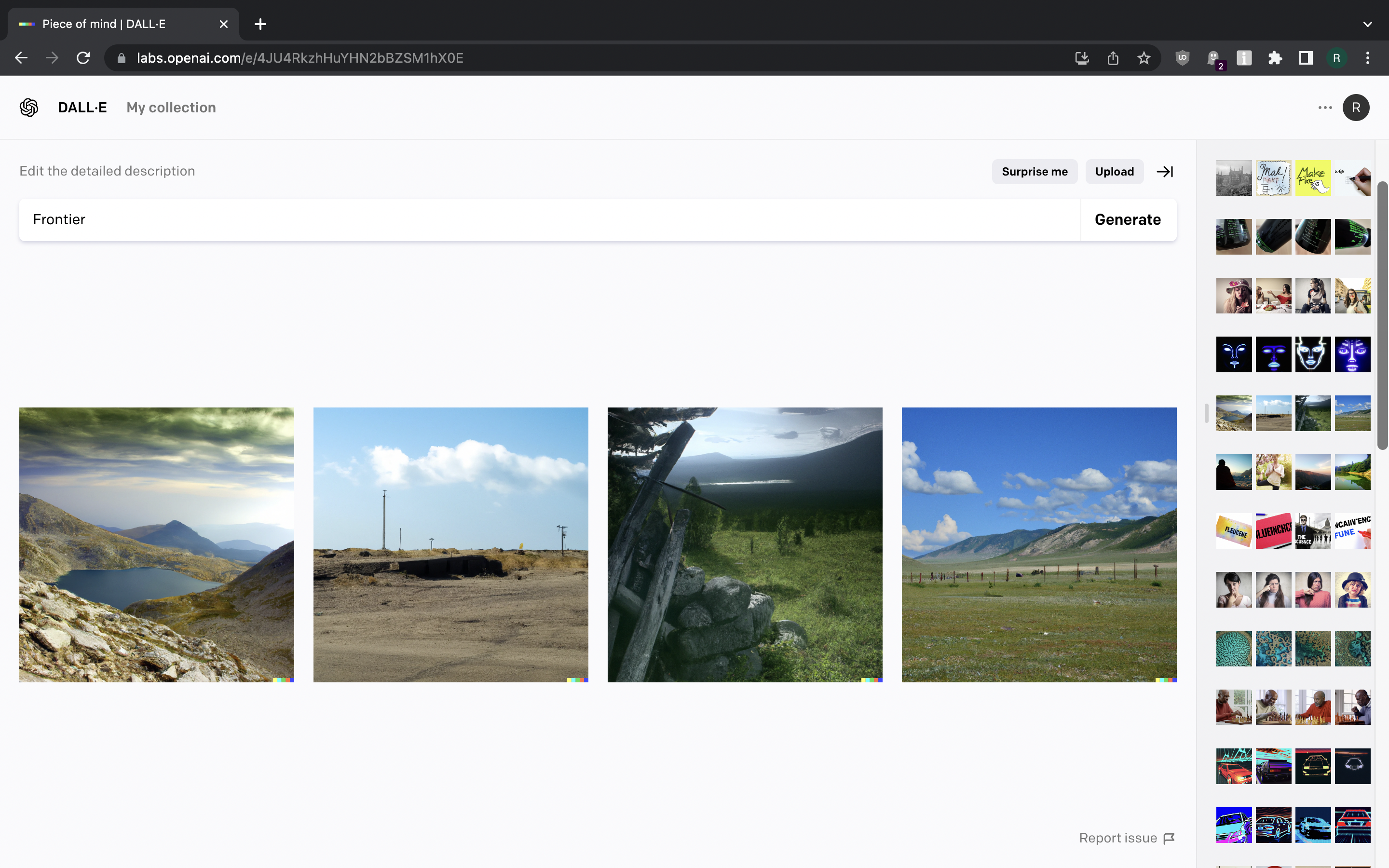
What does a frontier look like? DALL-E generates some derelict natural landscapes when asked to visualise it.
{kind=link}
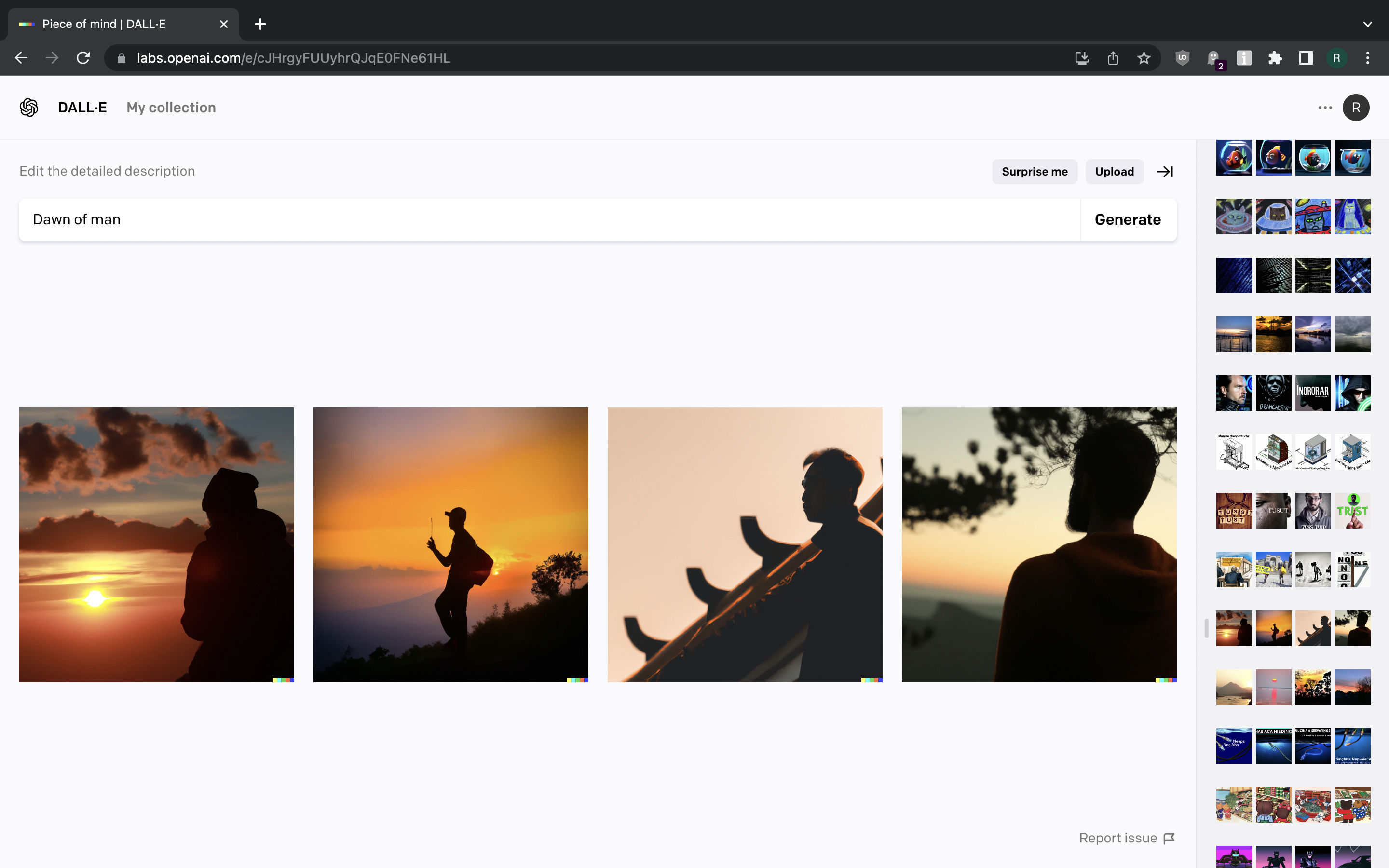
What about “Dawn of man”? When given this prompt, DALL-E generates a picture of man, illuminated by a light of dawn. Not very creative, and not what I had in mind.
{kind=link}
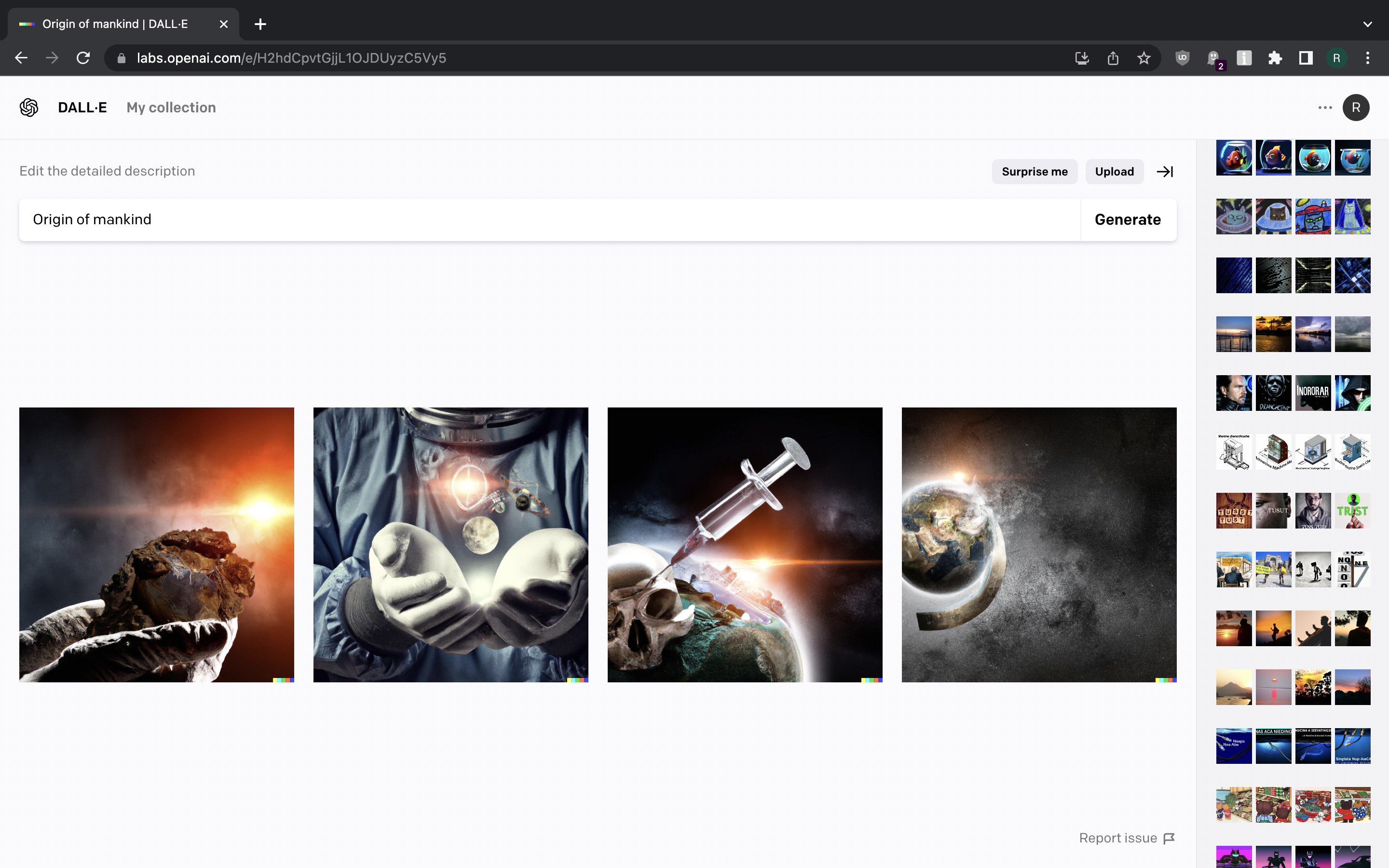
Perhaps we can rephrase it? What about “Origin of mankind”?
{kind=link}
Not it got abstract and science-fictiony by generating something that is quasi-spiritual and maybe references the ancient astronaut idea… Weird stuff here.
Asking to show us what “paradigm shift” looks like gives us some weird human figures, accompanied by distorted text.
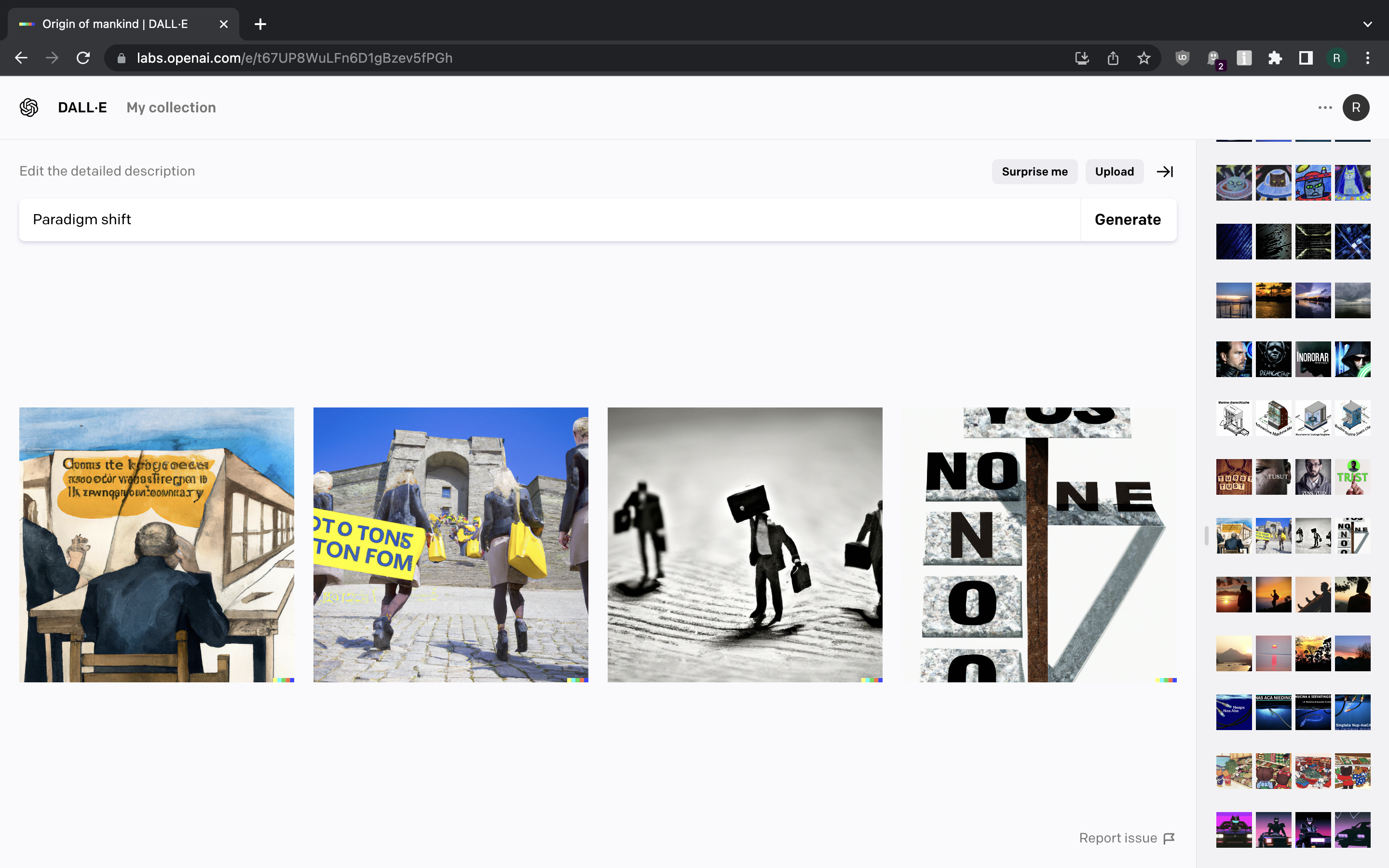{kind=link}
When asked to show us “computational complexity” it generates some distorted version of corporate stock images with people looking at screens.
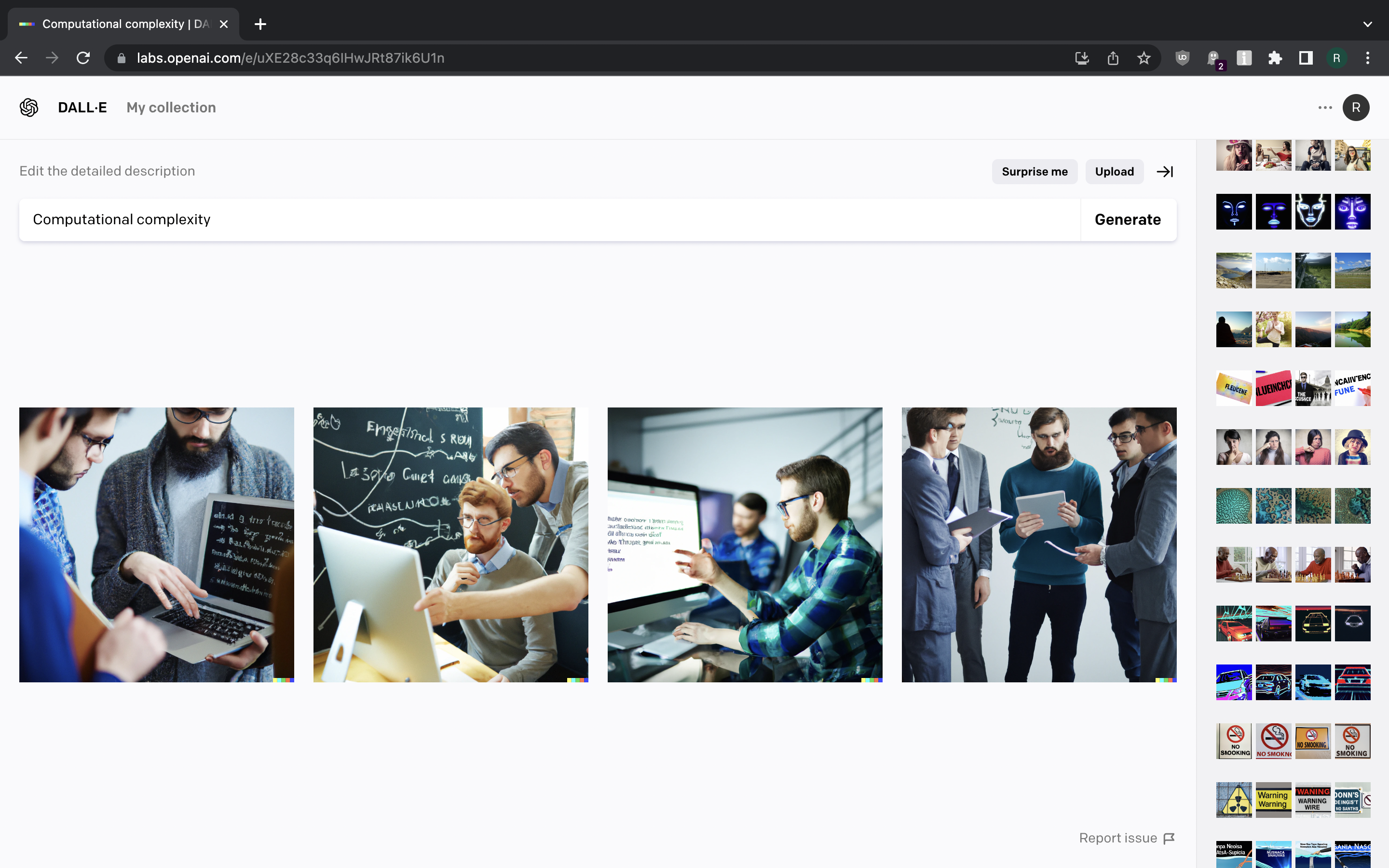{kind=link}
Faces are kinda messed up and text in the images is completely destroyed. It seems these are the things DALL-E currently has trouble generating properly.
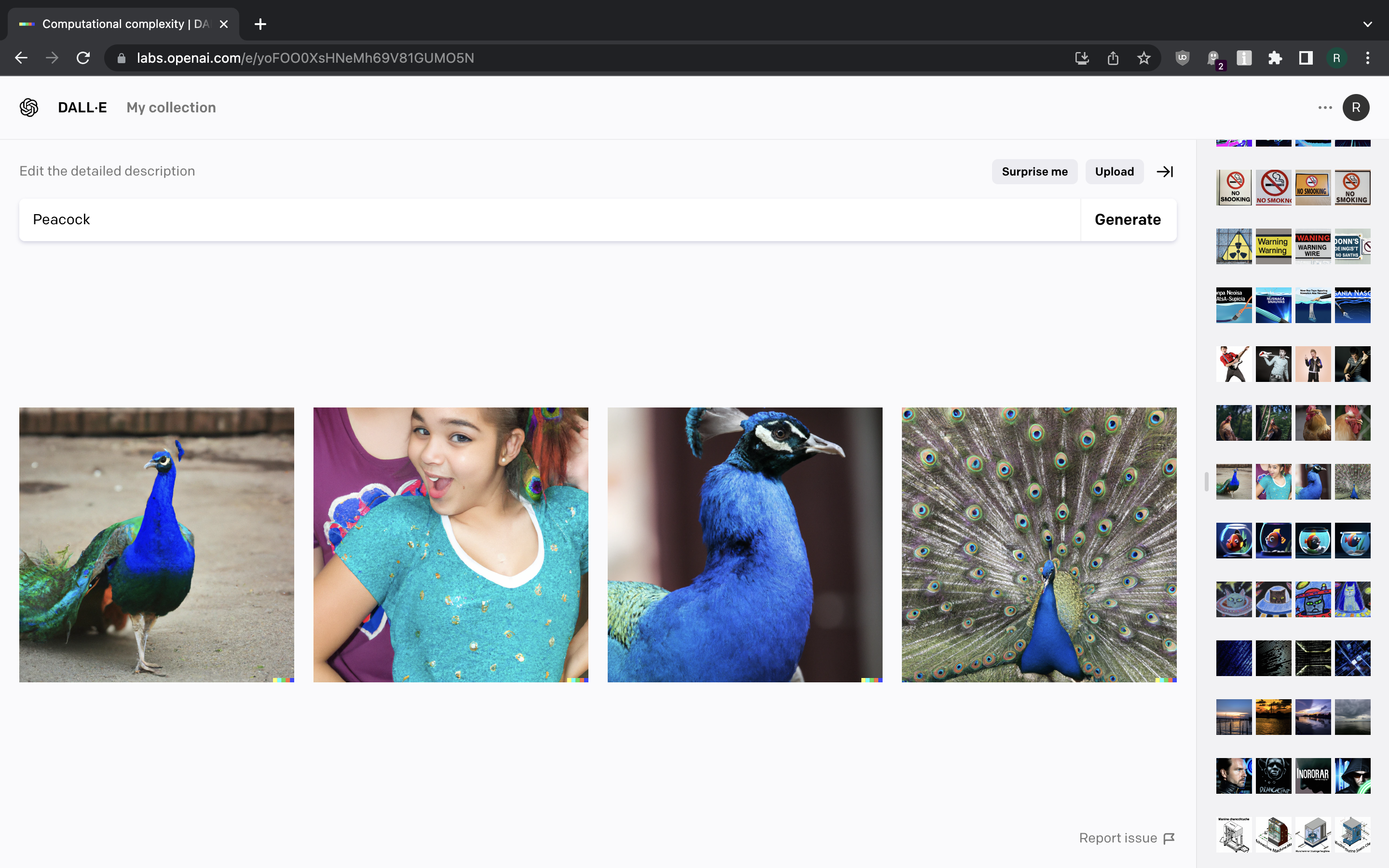
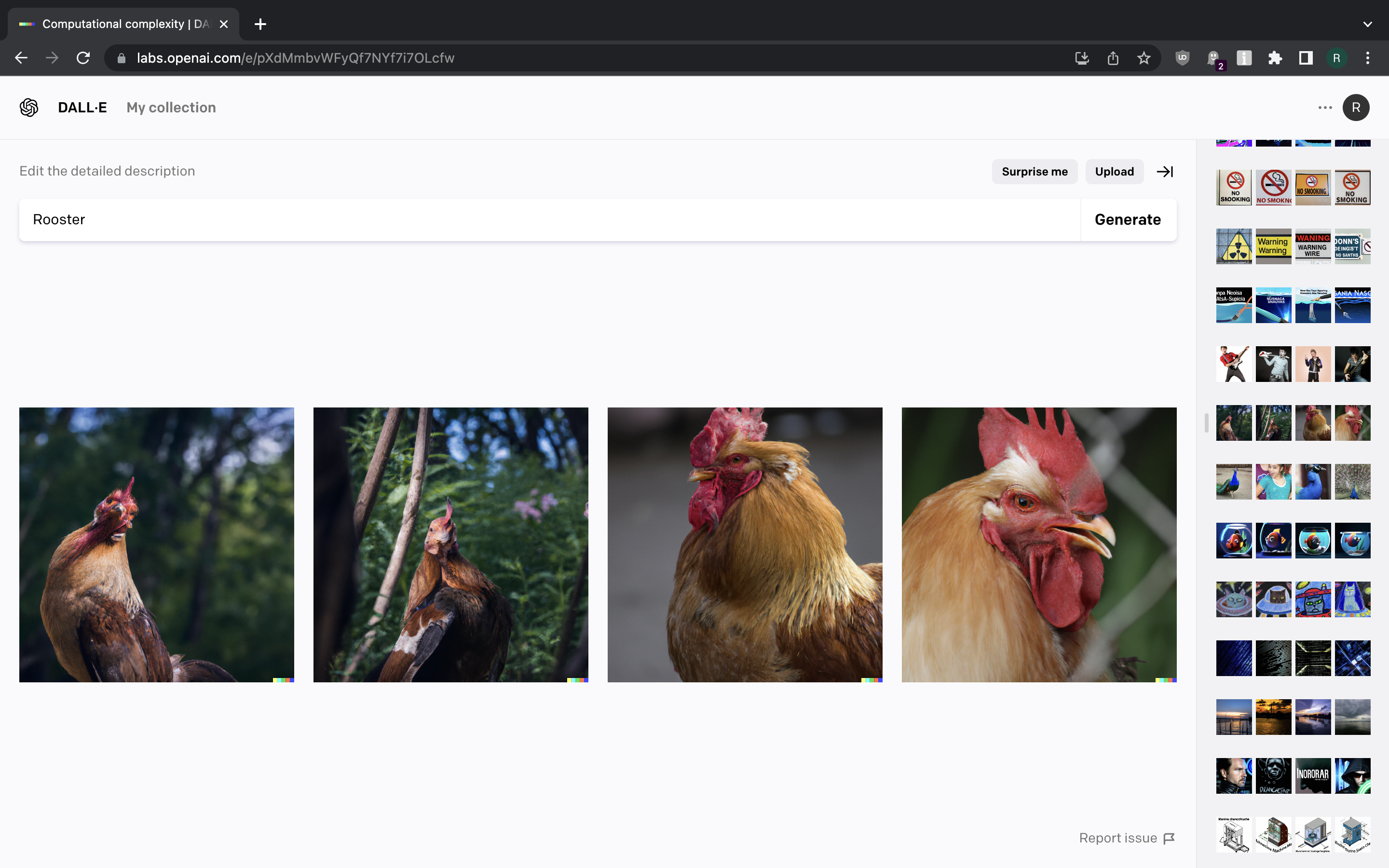
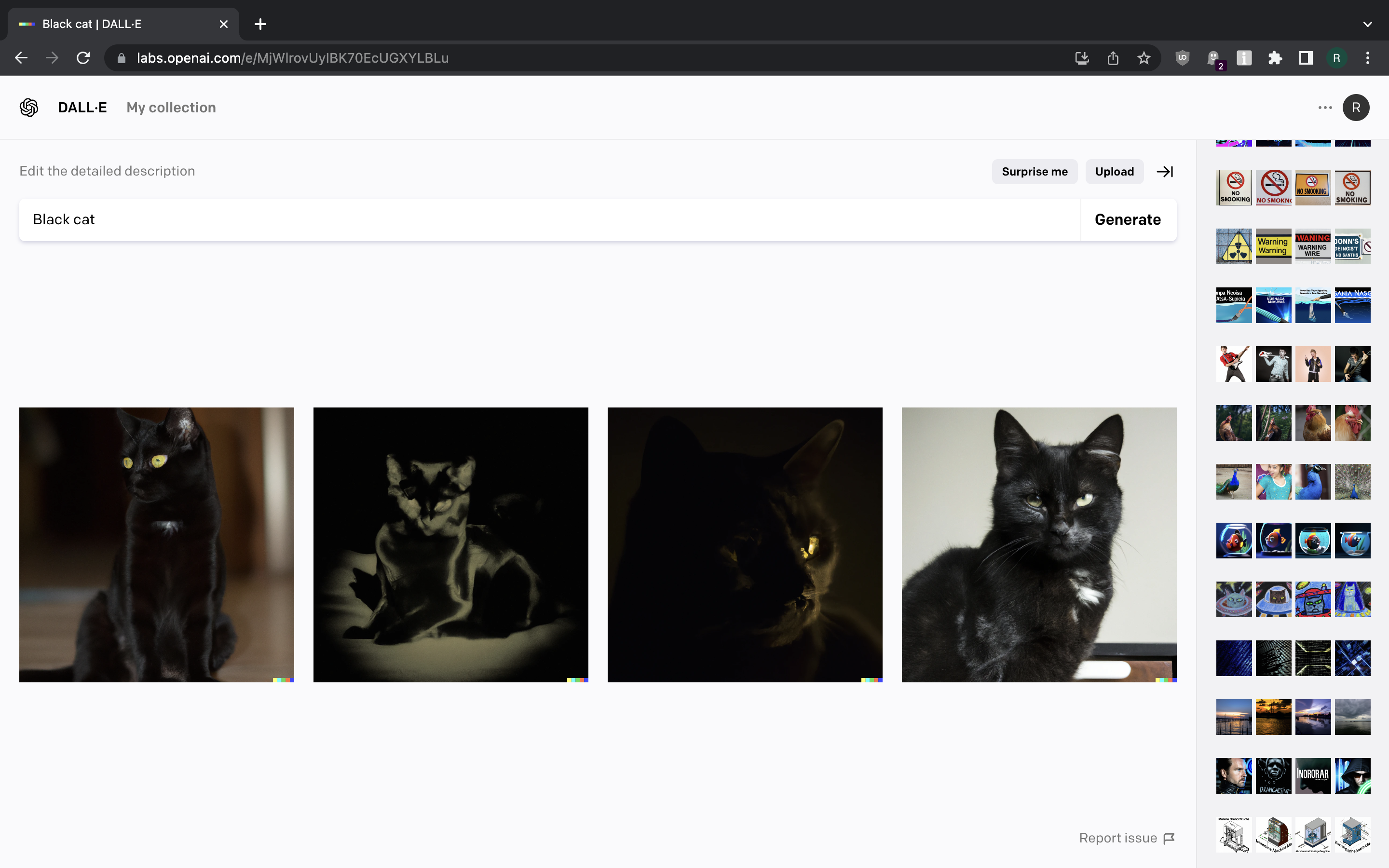
Enough with the abstract stuff for now. Let us generate images of some birds and animals.
Screenshot 7 Screenshot 8 Screenshot 9 Screenshot 10
{kind=link}
{kind=link}
{kind=link}
{kind=link}
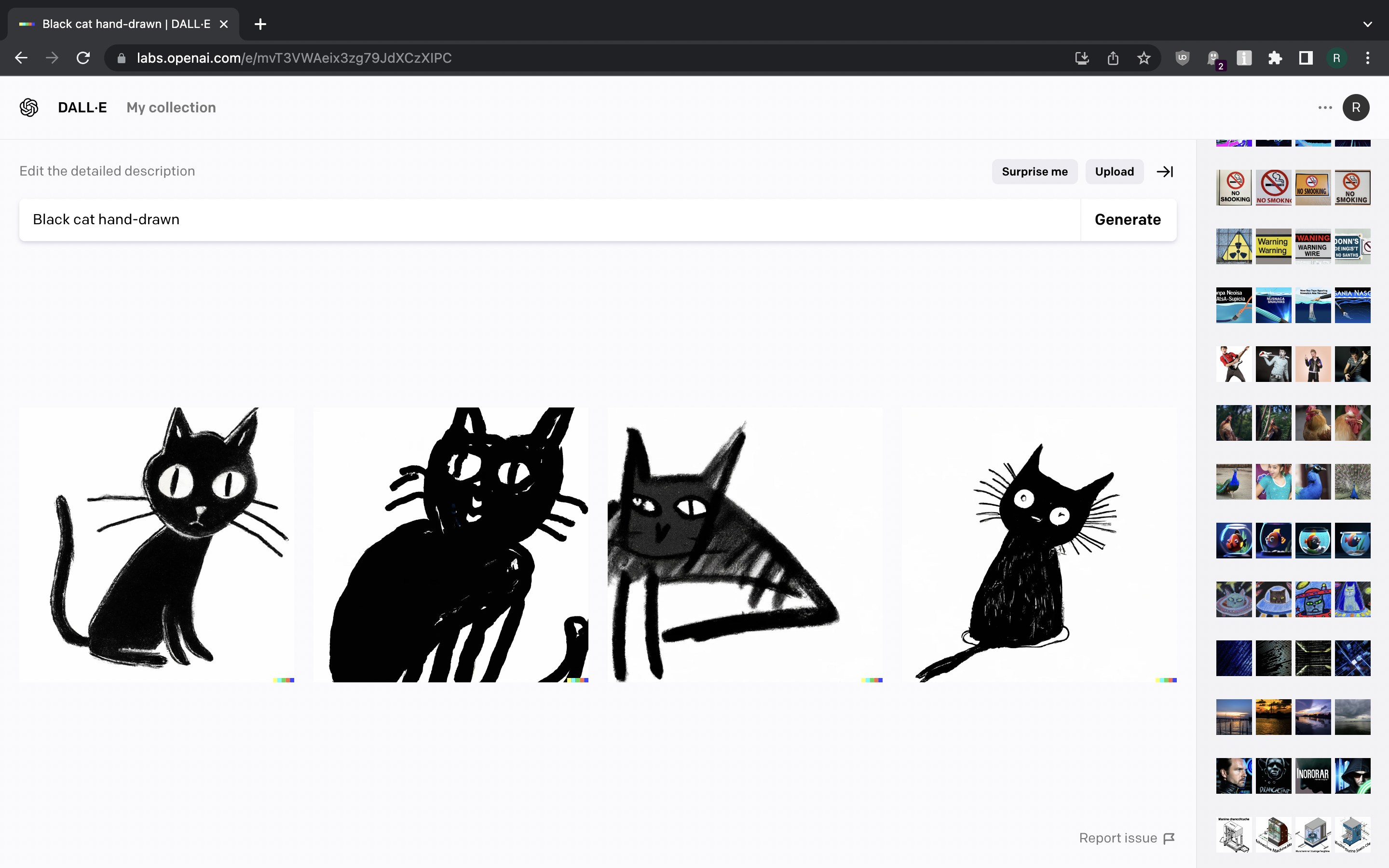
Pretty much all good here. We’re getting what we asked for, even if we want it hand-drawn. The only exception was a single picture of girl wearing peacock feathers when we asked for a picture of peacock.
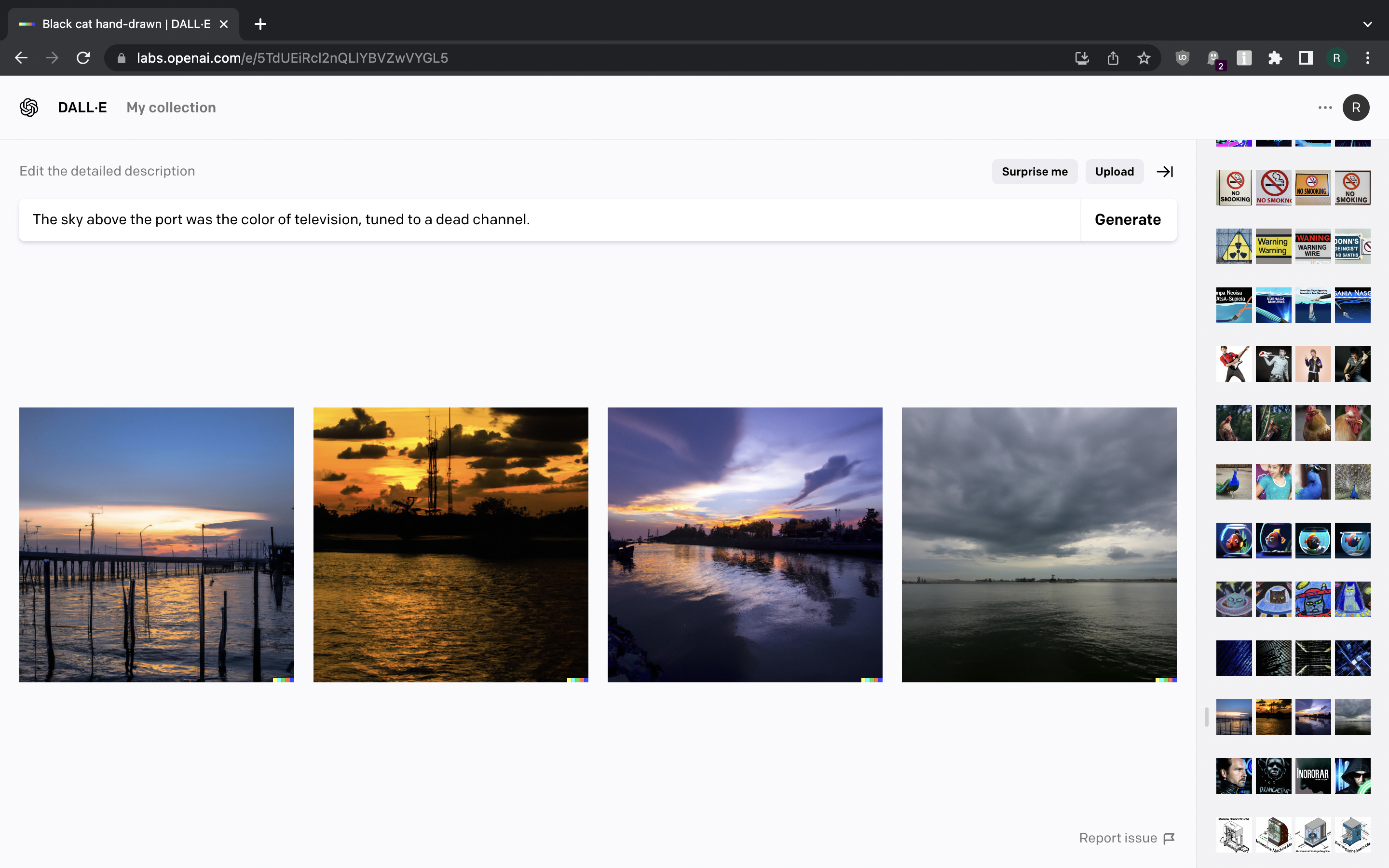
Let us to visualise some sci-fi quotes. “The sky above the port was the color of television, tuned to a dead channel” gives us a cloudy sky over water, with something like harbour being visible.
{kind=link}
Not too bad, I guess. After all, cloudy sky is what William Gibson had in mind when he wrote that back in the 80s.
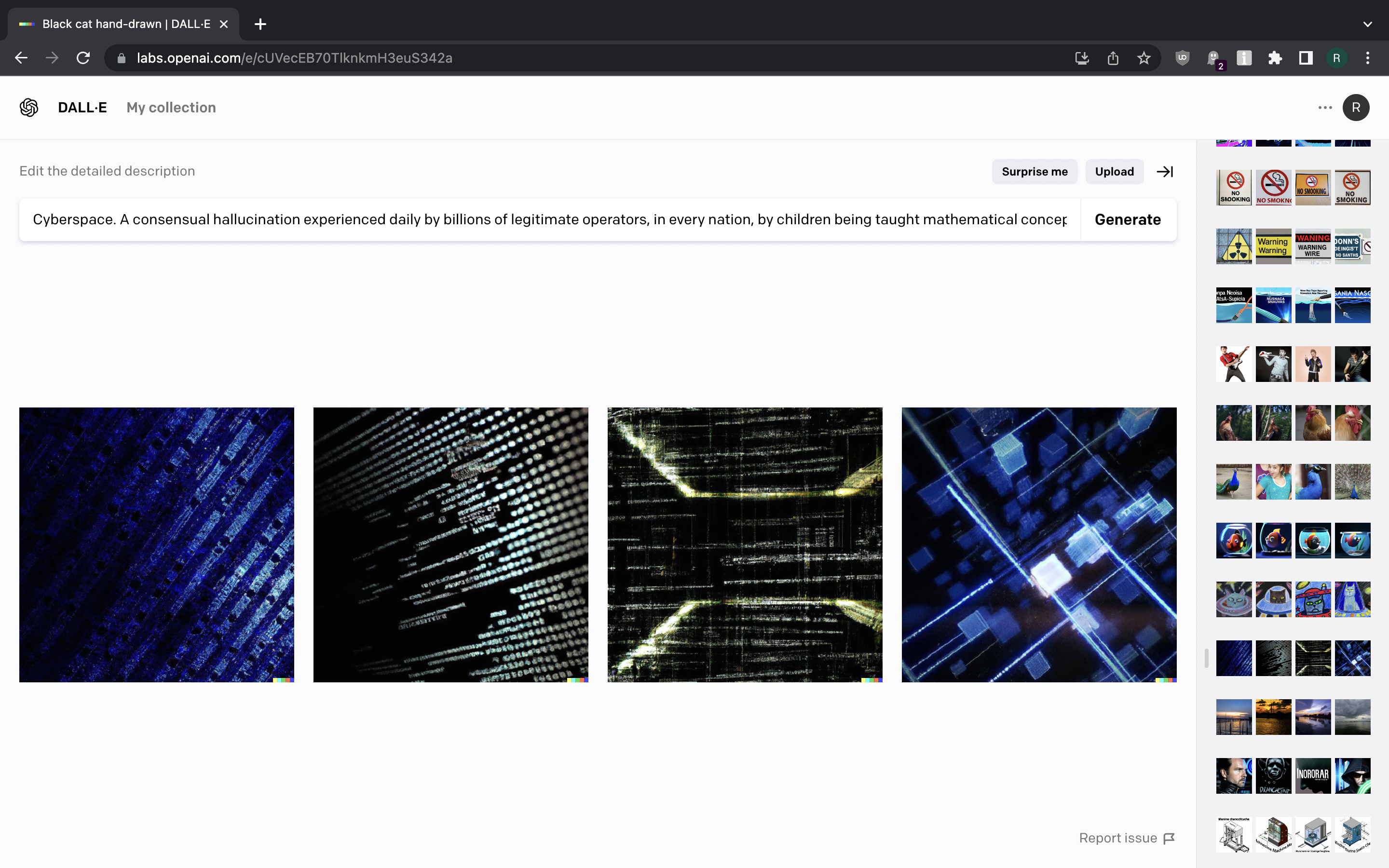
What about something more elaborate? “Cyberspace. A consensual hallucination experienced daily by billions of legitimate operators, in every nation, by children being taught mathematical concepts… A graphic representation of data abstracted from banks of every computer in the human system. Unthinkable complexity. Lines of light ranged in the nonspace of the mind, clusters and constellations of data. Like city lights, receding…” gives us the following:
{kind=link}
Well, it generated something digital-looking, but this is not something I would be happy with if was paying for graphical designer to make a wall art based on that quote.
We tried two quotes from William Gibson, now let’s try something from Neal Stephenson. What about “We are all susceptible to the pull of viral ideas. Like mass hysteria. Or a tune that gets into your head that you keep humming all day until you spread it to someone else. Jokes. Urban legends. Crackpot religions. Marxism. No matter how smart we get, there is always this deep irrational part that makes us potential hosts for self-replicating information.”?
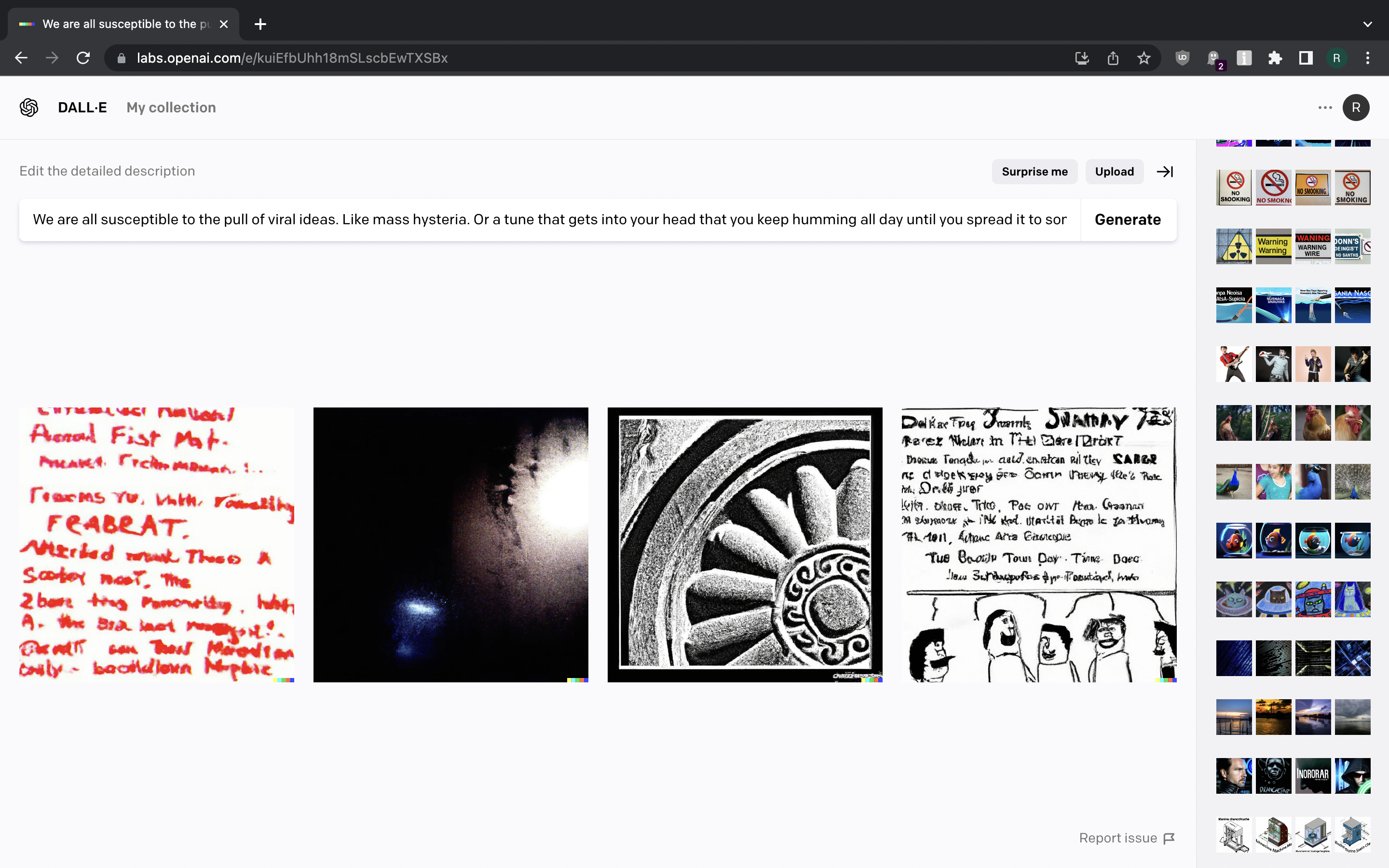{kind=link}
Well, that’s even worse. We got one image with distorted red text, one abstract image with some lights in the distance, one image of stone artwork and one comic strip with messed up text. No good.
Perhaps we need something bit more visual. Let us try “Hiro watches the large, radioactive, spear-throwing killer drug lord ride his motorcycle into Chinatown. Which is the same as riding it into China, as far as chasing him down is concerned”…
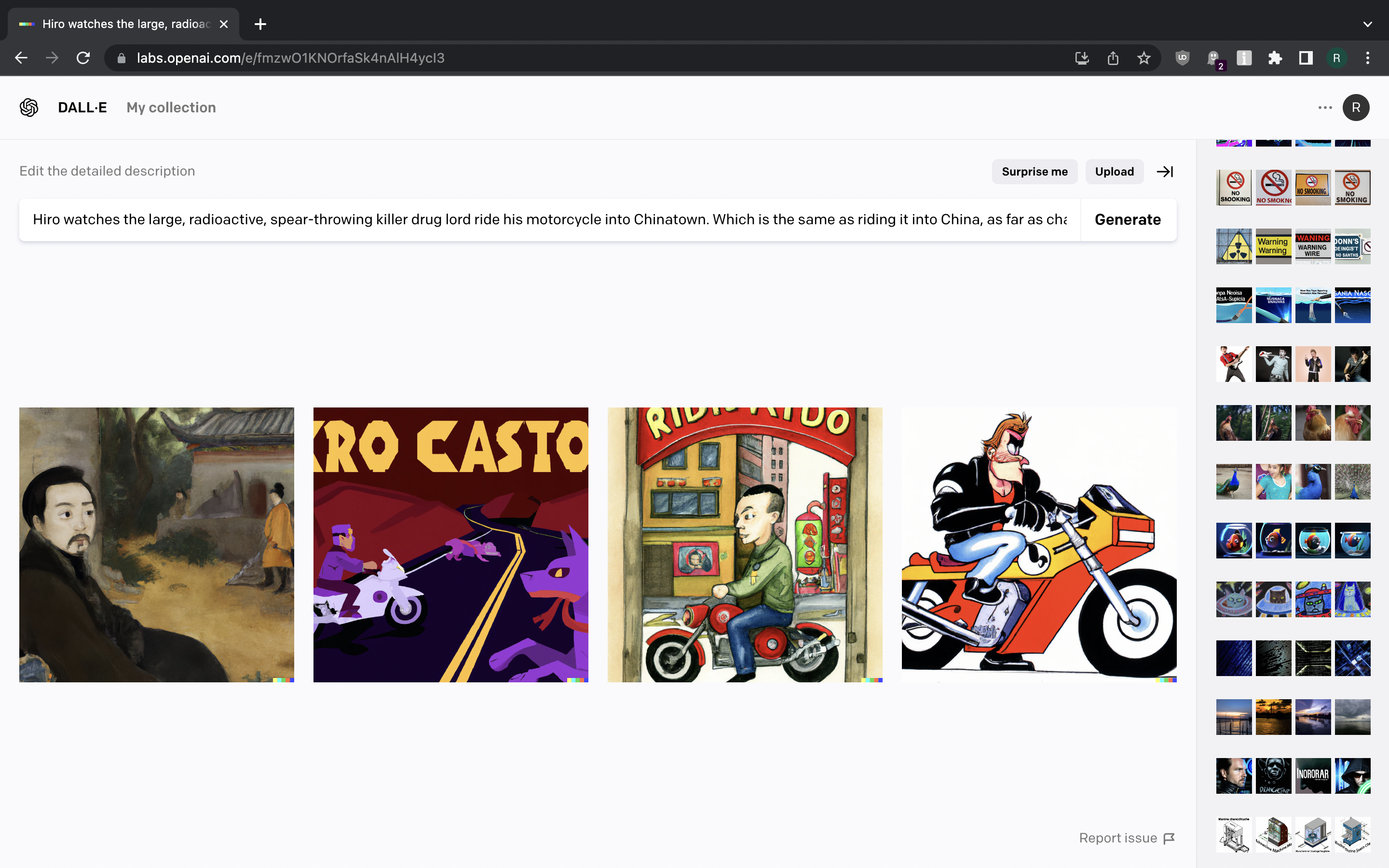{kind=link}
Ugh. Anyway… I think we’re done here.
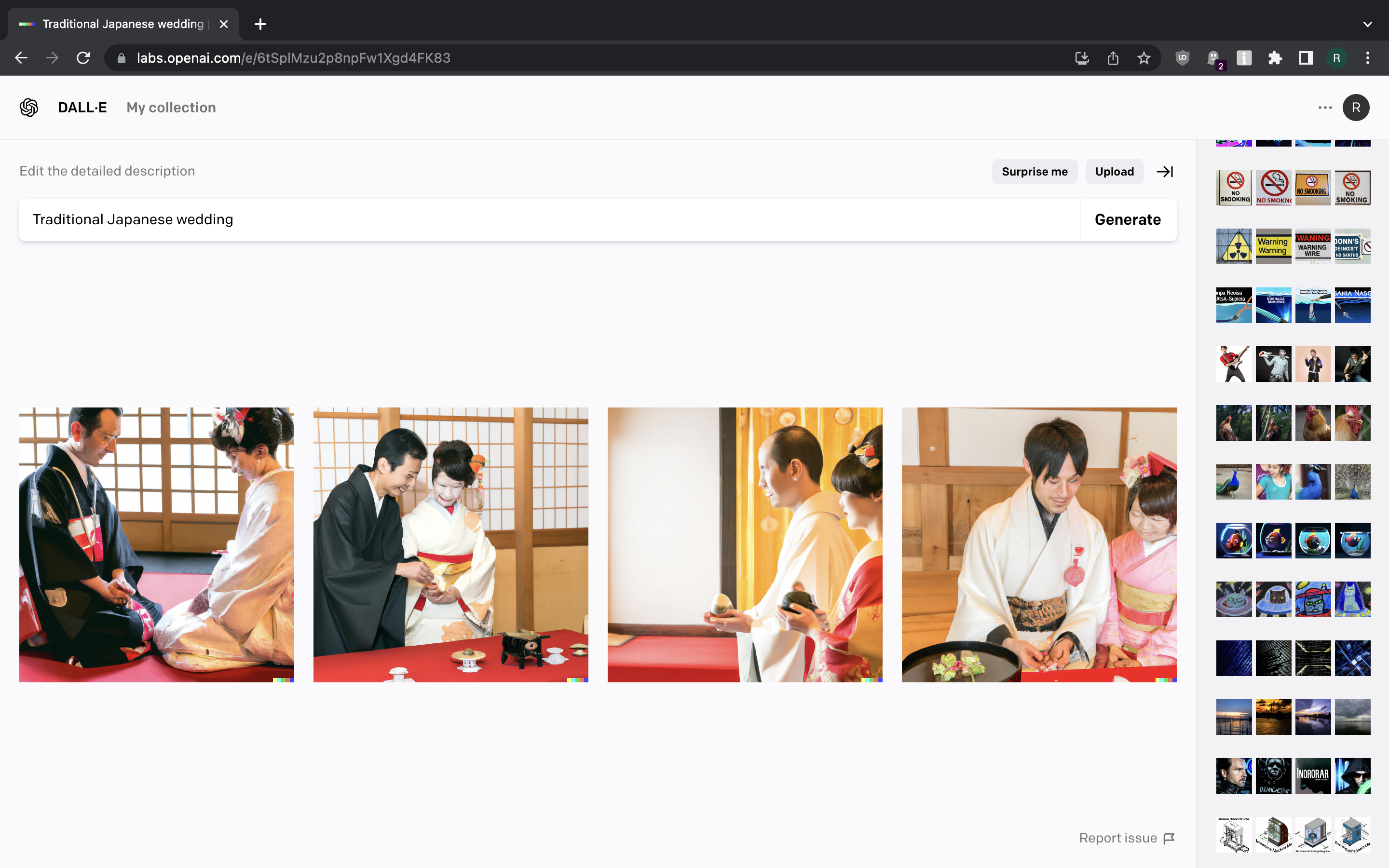
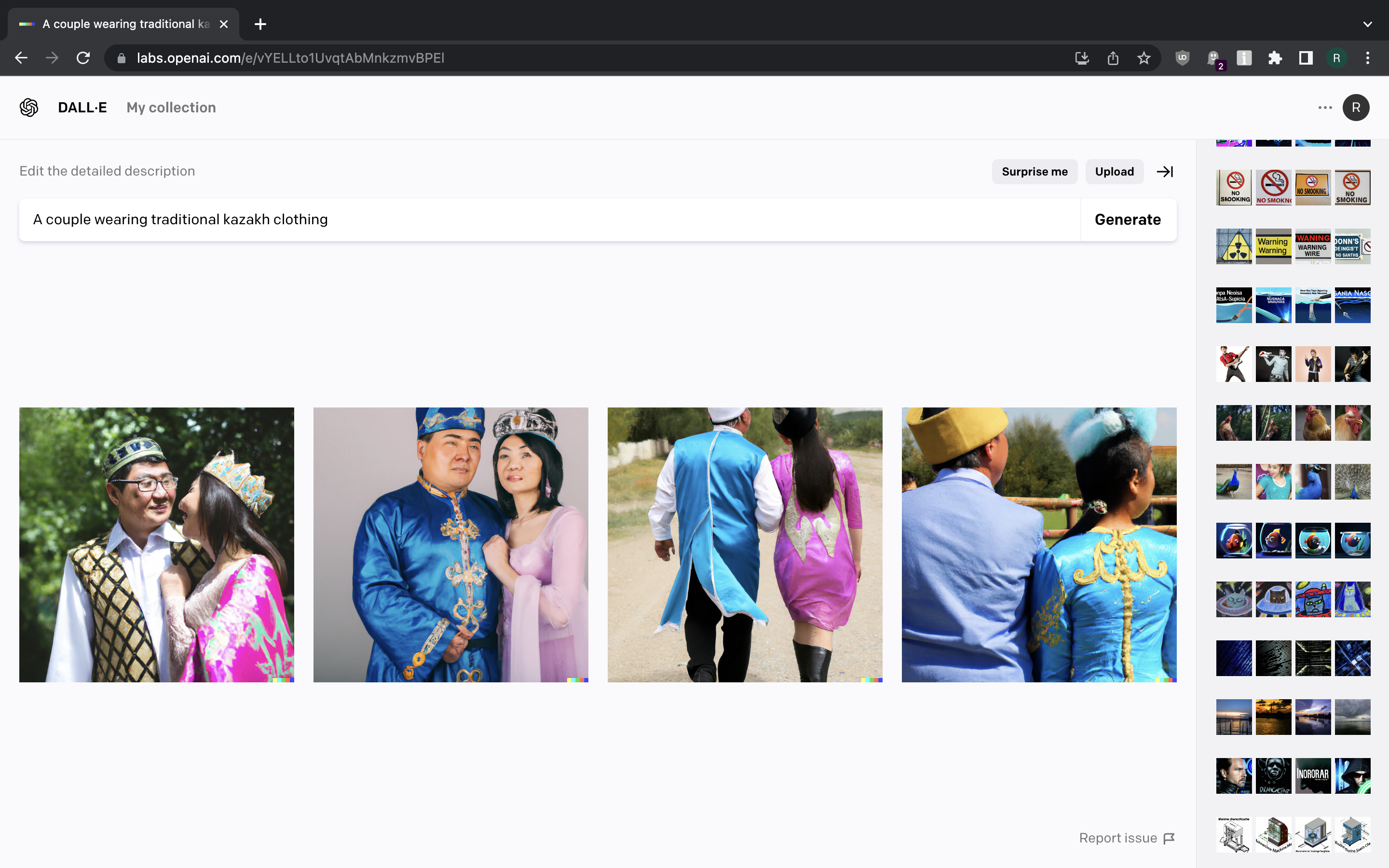
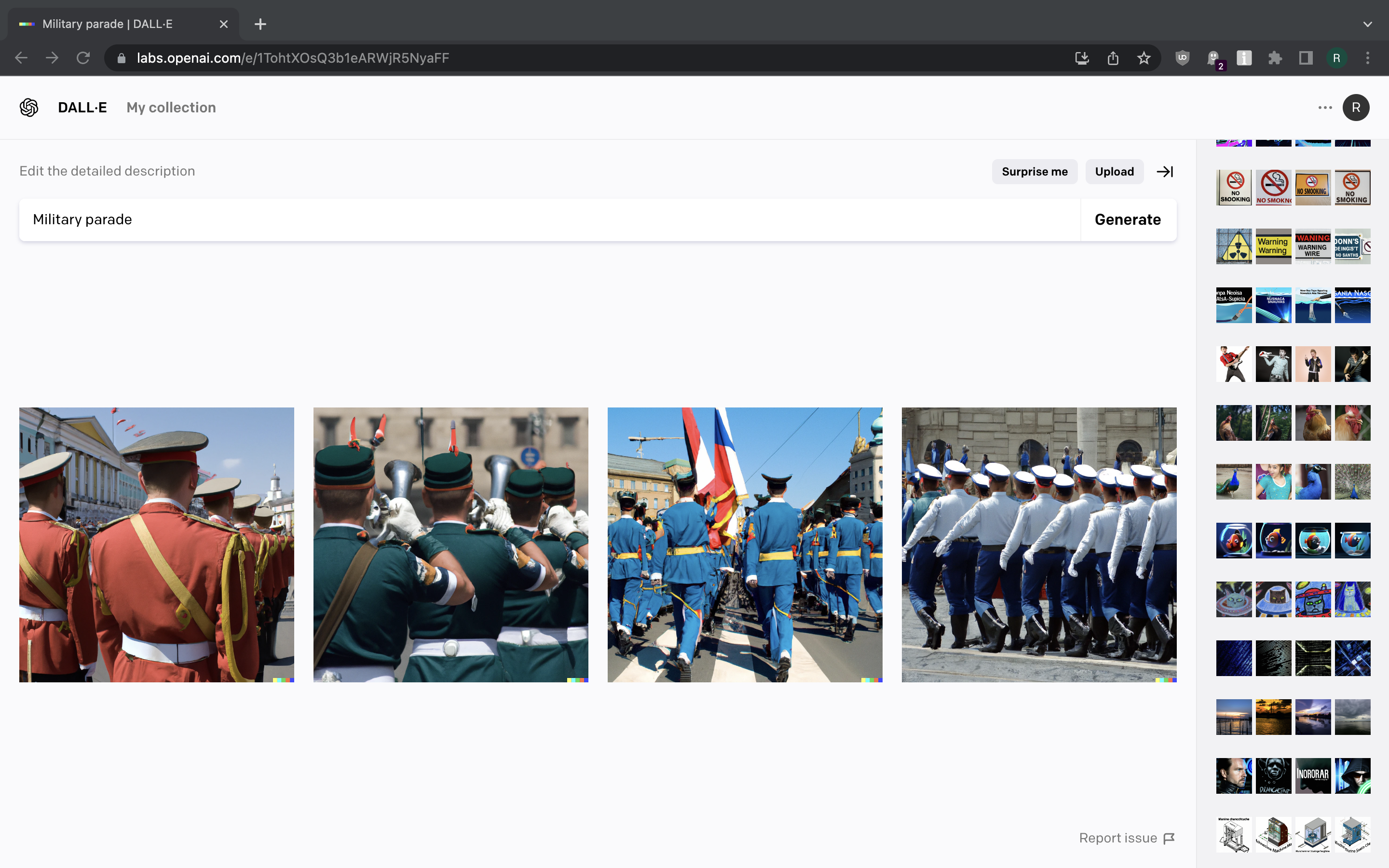
Let us try generating images that are related to various cultures, traditional activities and dress codes.
Screenshot 15 Screenshot 16 Screenshot 17
{kind=link}
{kind=link}
{kind=link}
We can also spot some distorted faces here, but generally we’re getting what we asked for.
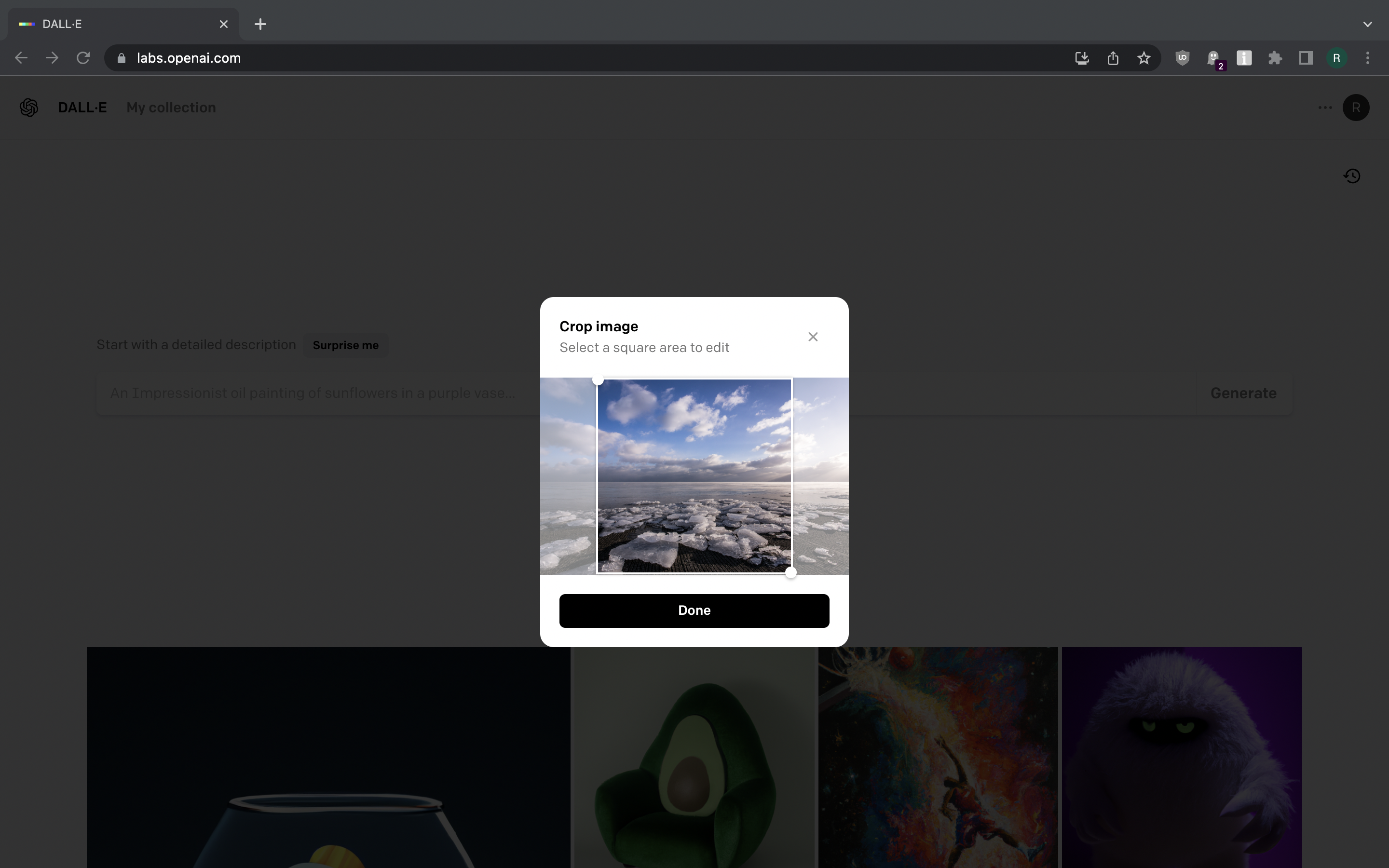
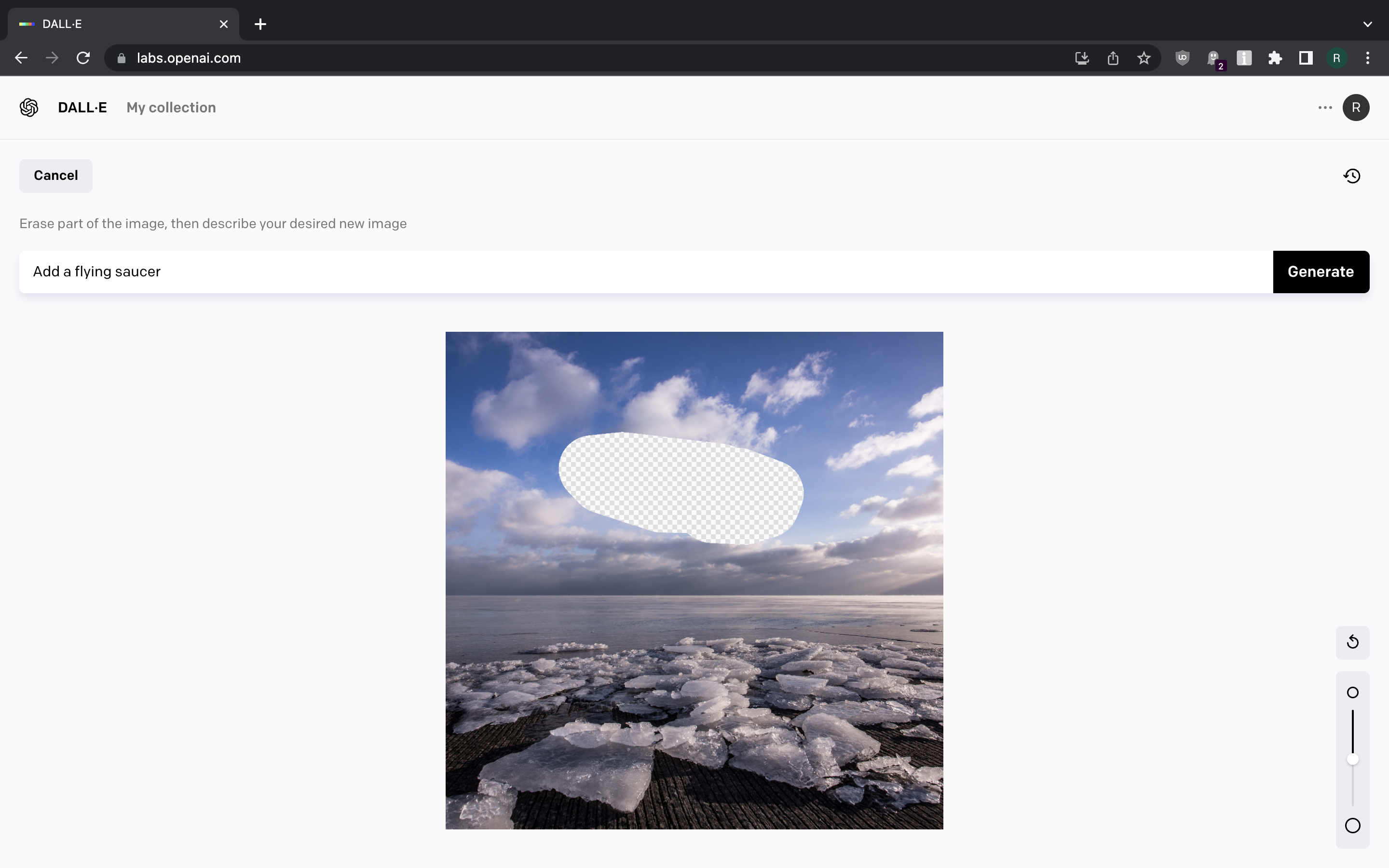
DALL-E can also be used to modify existing images. Let us try that. We can upload a random picture from Flickr, crop it to square, mark the part we want to modify and write a prompt on how we want to modify it.
Screenshot 18 Screenshot 19 Screenshot 20 Screenshot 21
{kind=link}
{kind=link}
{kind=link}
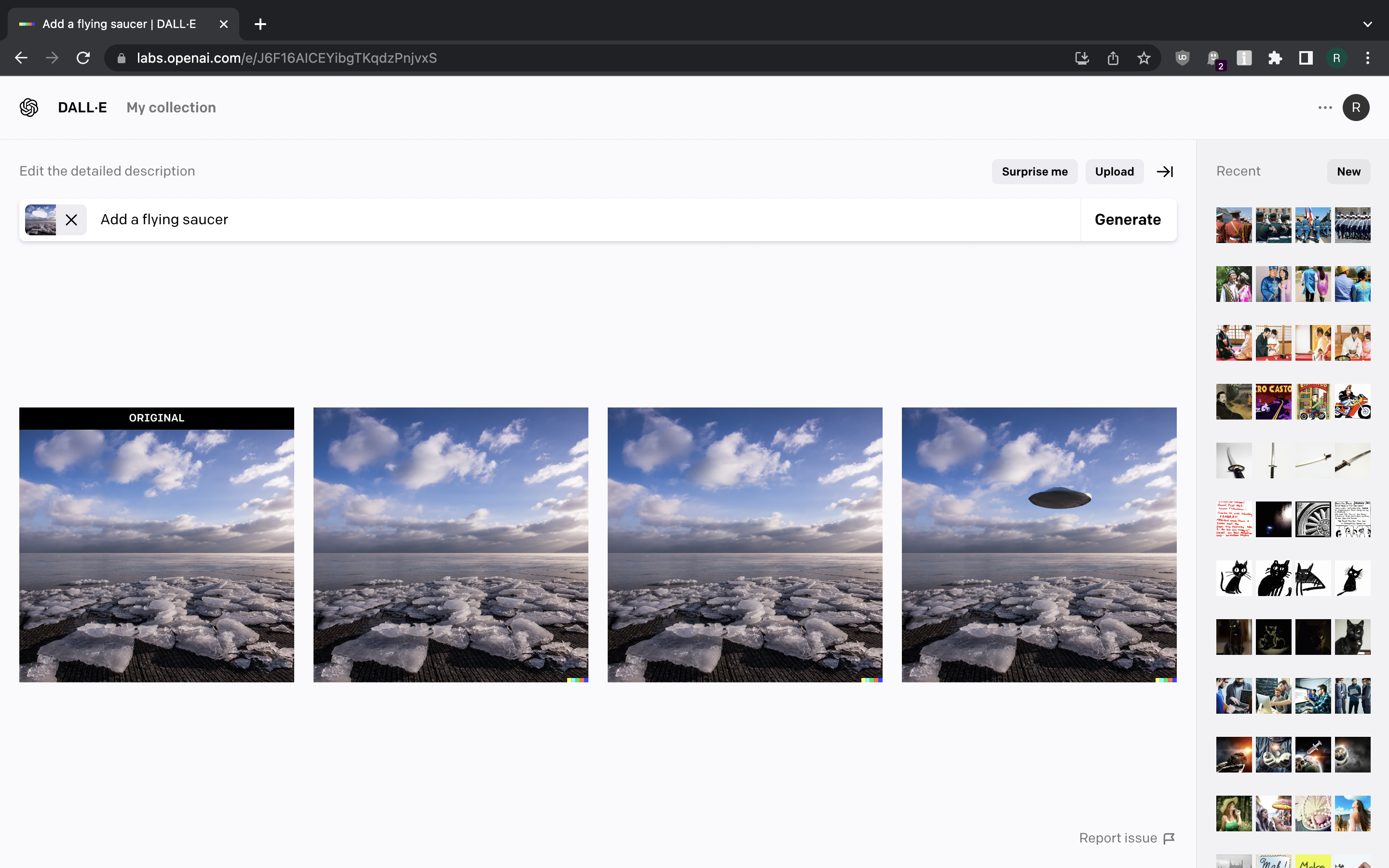{kind=link}
Not too bad, huh?
Lastly, we can use the uploaded image as “inspiration” to get DALL-E generate more images like the one that was uploaded.
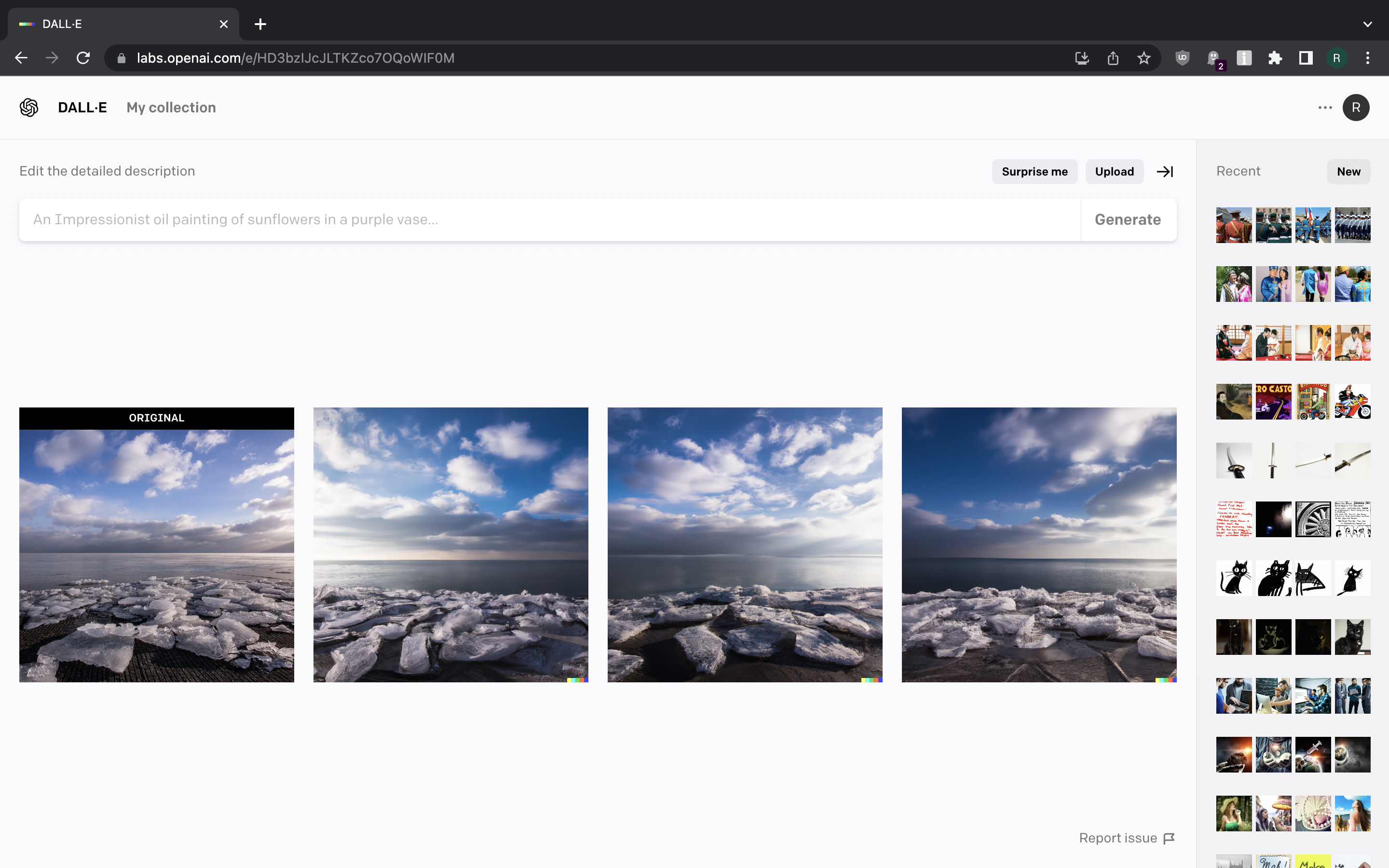{kind=link}
Overall this is impressive stuff. However, it is unlikely to completely replace entire trade of graphic design due to its limited ability to visualise complex ideas and no ability to ask follow-up question to clarify what we meant, or how we want something to be depicted.