MS Playwright is a framework for web testing and automation. Playwright supports programmatic control of Chromium and Firefox browser and also integrates WebKit engine. Headless mode is supported and enabled by default, thus making it possible to run your automations in environments that have no GUI support (lightweight virtual private servers, Docker containers and so on). Playwright is written in JavaScript, but has official bindings for Python, C#, TypeScript and Java. Think of Playwright as more modern equivalent of things like Selenium and Puppetteer that solve some of the problems associated with these technologies (e.g. crashes in your code due to race conditions). Since Python is commonly used for gray hat automation, we will experiment with Python version of Playwright API with the need to evade automation countermeasures in mind.
Let us install Playwright first in Python development enviromnent. This is fairly simple:
- Run
pip3 install playwrightto install Playwright Python module with CLI tool. - Run
playwright installto install instances of browsers that Playwright manages for you. - Run
playwright install-depsto install other dependencies that Playwright needs to run. Depending on your enviroment this might not be needed.
With these 3 steps I was able to get Playwright working on $5 Digital Ocean server within minutes.
Now let us do our first experiment. Let’s modify some sample code to try loading two sites with all 3 browsers Playwright supports:
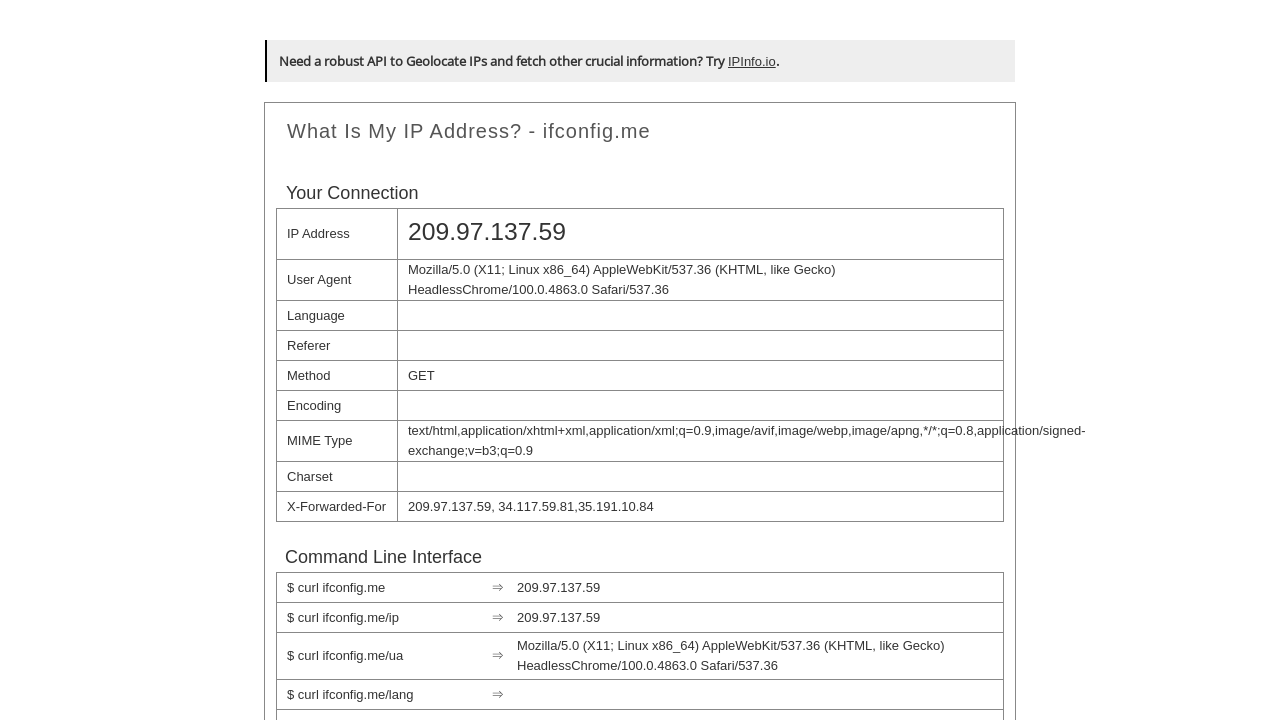
- ifconfig.me - gives us page with source IP address and headers within HTTP request.
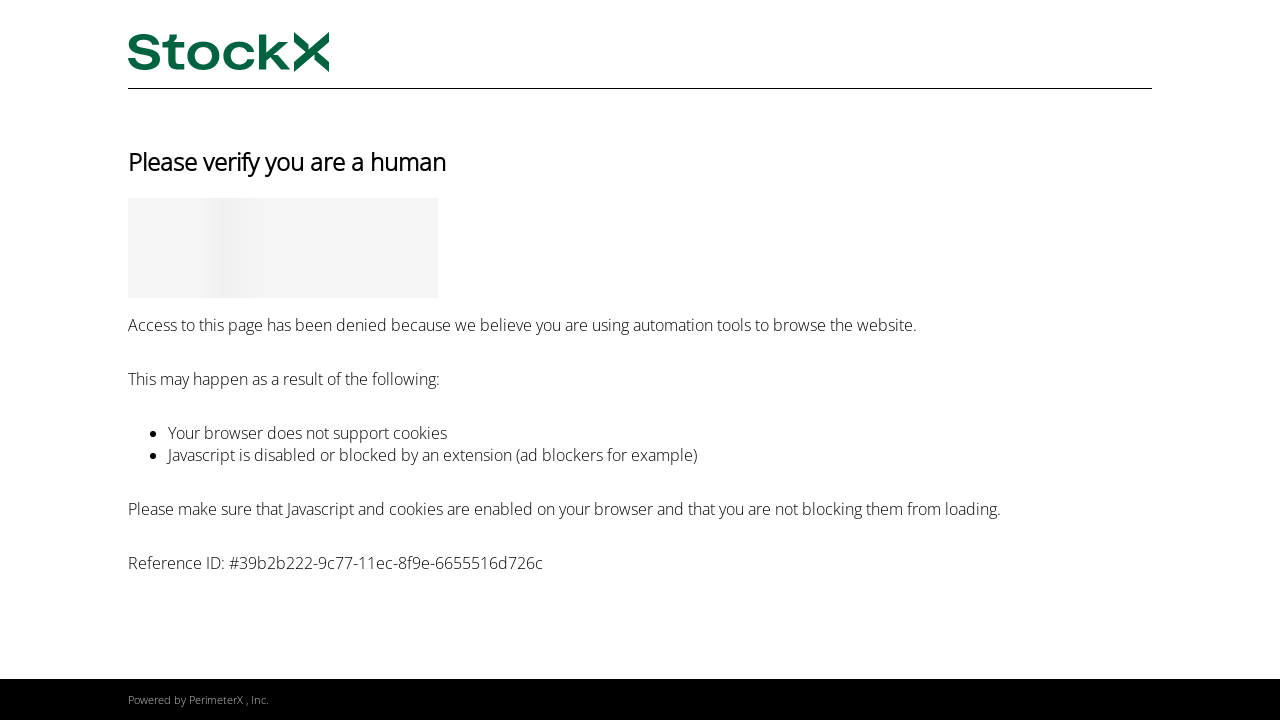
- StockX - prominent sneaker marketplace that is protected by PerimeterX and Cloudflare anti-botting technologies.
#!/usr/bin/python3
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
for url in ["https://www.stockx.com", "https://ifconfig.me"]:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = browser_type.launch()
page = browser.new_page()
page.goto(url)
print(page.title())
domain = url.split("//")[-1]
page.screenshot(path=f'example-{domain}-{browser_type.name}.png')
browser.close()
example-ifconfig.me-chromium.png
{kind=link}
example-www.stockx.com-chromium.png
{kind=link}
We see that string Headless is included into User-Agent header and that an attempt to load StockX page instantly
fails due to be being detected by PerimeterX.
However, we can set user_agent argument
when calling new_page() method and pass a string with User-Agent value from a proper browser, which prevents getting
blocked on the very first page by PerimeterX.
We can also set proxy argument to dictionary with proxy address and credentials. Unfortunately, it does not support putting proxy
credentials and address in the same way as requests module does. Instead, we would need to create a dictionary with following
key-value pairs:
server- server URL.username- proxy username.password- proxy password.
Playwright also has a code generator feature that we can try by launching playwright codegen. Running this command
launches a Playwright-managed browser (Chromium by default) with an Inspector window next to it. When user actions are performed
in the browser window, code that reproduces these actions is automatically generated in inspector window. For instance, going
through the happy path of Instagram login flow generates the following code that you can use as starting point for your automation
script:
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.instagram.com/
page.goto("https://www.instagram.com/")
# Click text=Only allow essential cookies
page.locator("text=Only allow essential cookies").click()
# Click [aria-label="Phone\ number\,\ username\,\ or\ email"]
page.locator("[aria-label=\"Phone\\ number\\,\\ username\\,\\ or\\ email\"]").click()
# Fill [aria-label="Phone\ number\,\ username\,\ or\ email"]
page.locator("[aria-label=\"Phone\\ number\\,\\ username\\,\\ or\\ email\"]").fill("[REDACTED]")
# Click [aria-label="Password"]
page.locator("[aria-label=\"Password\"]").click()
# Fill [aria-label="Password"]
page.locator("[aria-label=\"Password\"]").fill("[REDACTED]")
# Click button:has-text("Log In") >> nth=0
# with page.expect_navigation(url="https://www.instagram.com/"):
with page.expect_navigation():
page.locator("button:has-text(\"Log In\")").first.click()
# Click text=Not Now
page.locator("text=Not Now").click()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
We see that the code is fairly linear and does not have explicit waiting steps or any kind of exception handling. This is because
of Playwright locators - every time you call a locator() method Playwright makes sure that any waiting for element you are
interacting with is done automatically. String argument that is being passed into this method is called a selector and can be a
CSS selector, XPath query, React selector, or Vue selector.
A word of warning: it is generally advised to refrain from running automations against Instagram accounts that are considered valueable, as they can get suspended or banned due to triggering automation countermeasures at IG. For experimentation, you can get some disposable accounts from Accfarm.
When doing social media automation, it might be desirable to save cookies and reuse them to avoid performing login flow excessively.
Calling cookies on browser context object (context in the above code) gives us list of dictionaries with cookie data that we
can serialize into JSON and save:
cookies = context.cookies()
import json
c_f = open("cookies.json", "w")
json.dump(cookies, c_f)
c_f.close()
To reuse user session next time, we would call add_cookies() on browser context object with cookies that we have saved:
#!/usr/bin/python3
import json
import time
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
c_f = open("cookies.json", "r")
cookies = json.load(c_f)
c_f.close()
context.add_cookies(cookies)
# Open new page
page = context.new_page()
# Go to https://www.instagram.com/
page.goto("https://www.instagram.com/")
time.sleep(10)
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
Previously, we have used Python API to make page screenshots. However, Playwright CLI tool provides a quicker way to save screenshot:
$ playwright screenshot https://ifconfig.me ifconfig.png
Likewise, page content can be quickly saved into PDF document:
$ playwright pdf https://ifconfig.me ifconfig.pdf
We have barely scratched the surface of what Playwright can do, but what we have seen so far is promising. Playwright supports less browsers than Selenium does, but looks like a far superior choice when it comes to stability and developer experience. Some developers working in web scraping and gray hat automation say that it also has an additional benefit of making it easier to evade automation countermeasures, as there are less tell-tale signs in JS environment that betray browser being controlled programmatically. Our quick experiments with StockX and Instagram seem to support that.
You may also want to try Playwright_stealth - a Python module for additional blocking evasion features.