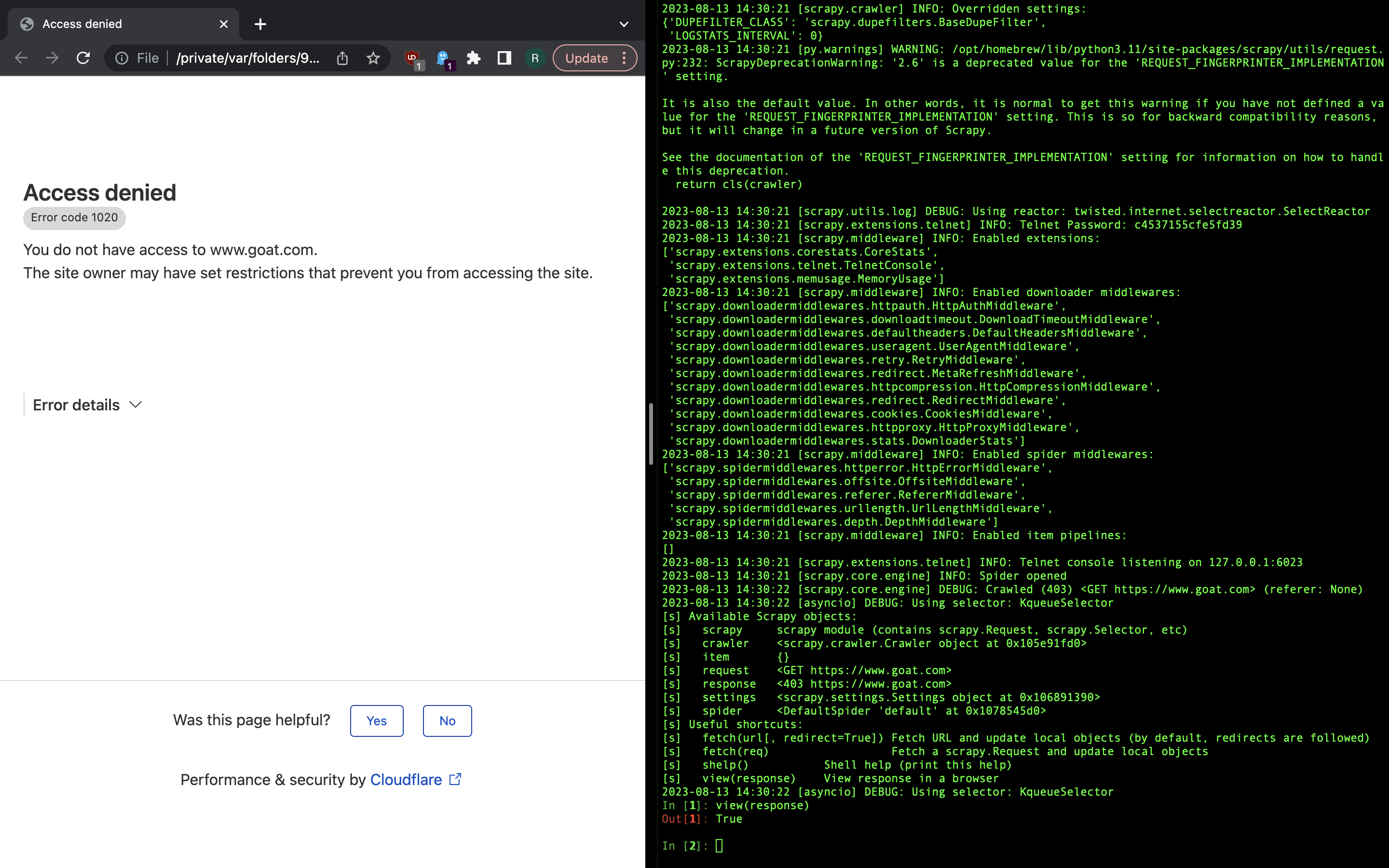
GOAT is an online platform for retail sale and reselling of certain consumer products - primarily sneakers, apparel and electronics. It is estimated to have about 50 million active users that include some one million sellers. When there’s a major userbase, there’s a potential to extract monetary benefit by scraping the data and/or running some automations. But 1661 Inc., a company that is developing GOAT don’t want us to do that. GOAT is one of the websites that proactively fight automated traffic. For example, merely trying load the front page in Scrapy shell gives us a Cloudflare error.
{kind=link}
So we have to proceed differently. One trick from grayhat automation arsenal is to MITM mobile app traffic to work out the exact API calls being done against the backend system, then replay them programmatically. Our example will be a simple API scraping to extract data.
We will be using mitmproxy to intercept GOAT API traffic. The setup in question is described in earlier post, except that a newer iOS version is used on the iPhone.
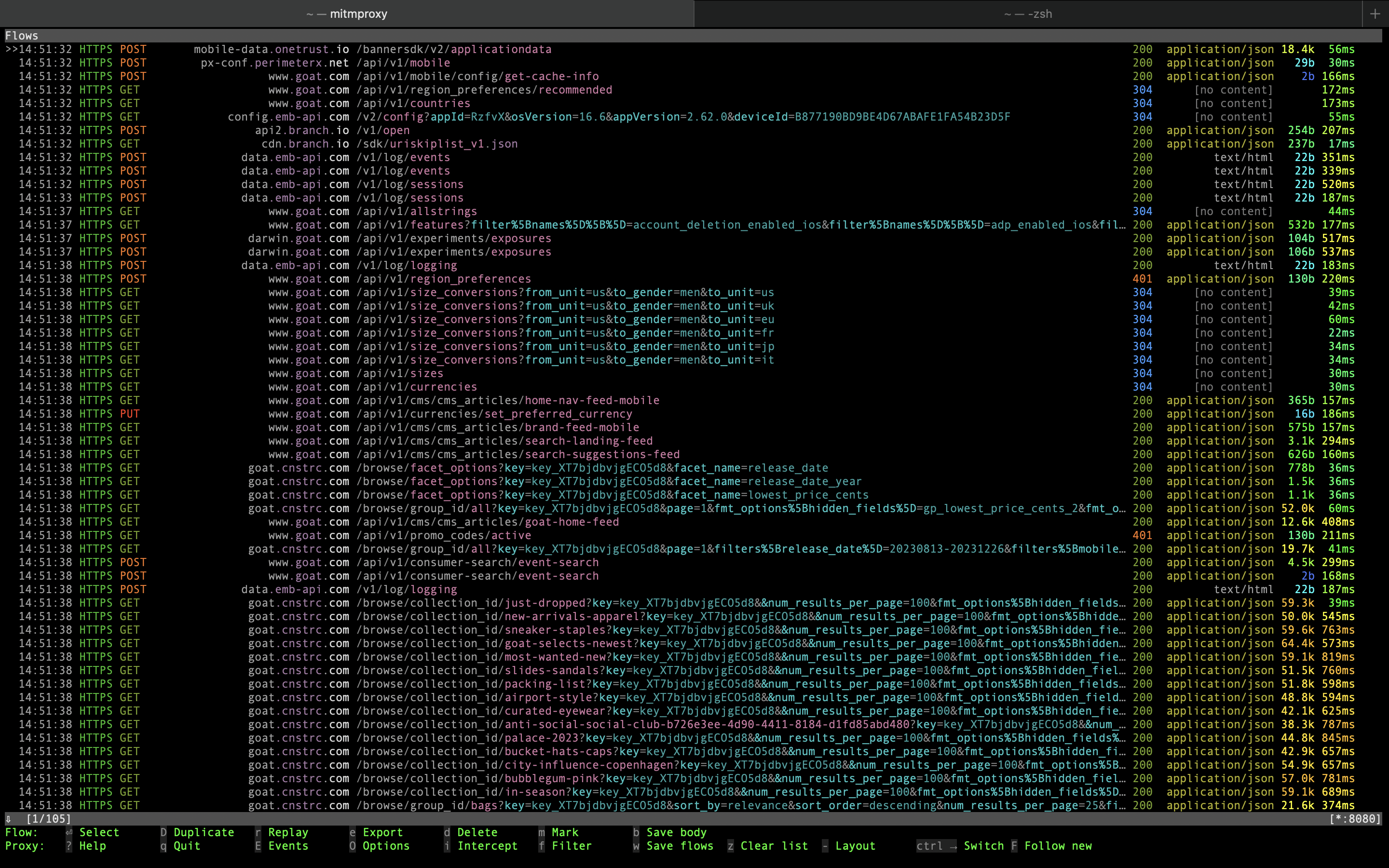
When we run the app and press “Start browsing” button we see quite a bit of traffic in mitmproxy TUI.
{kind=link}
Some things to notice here:
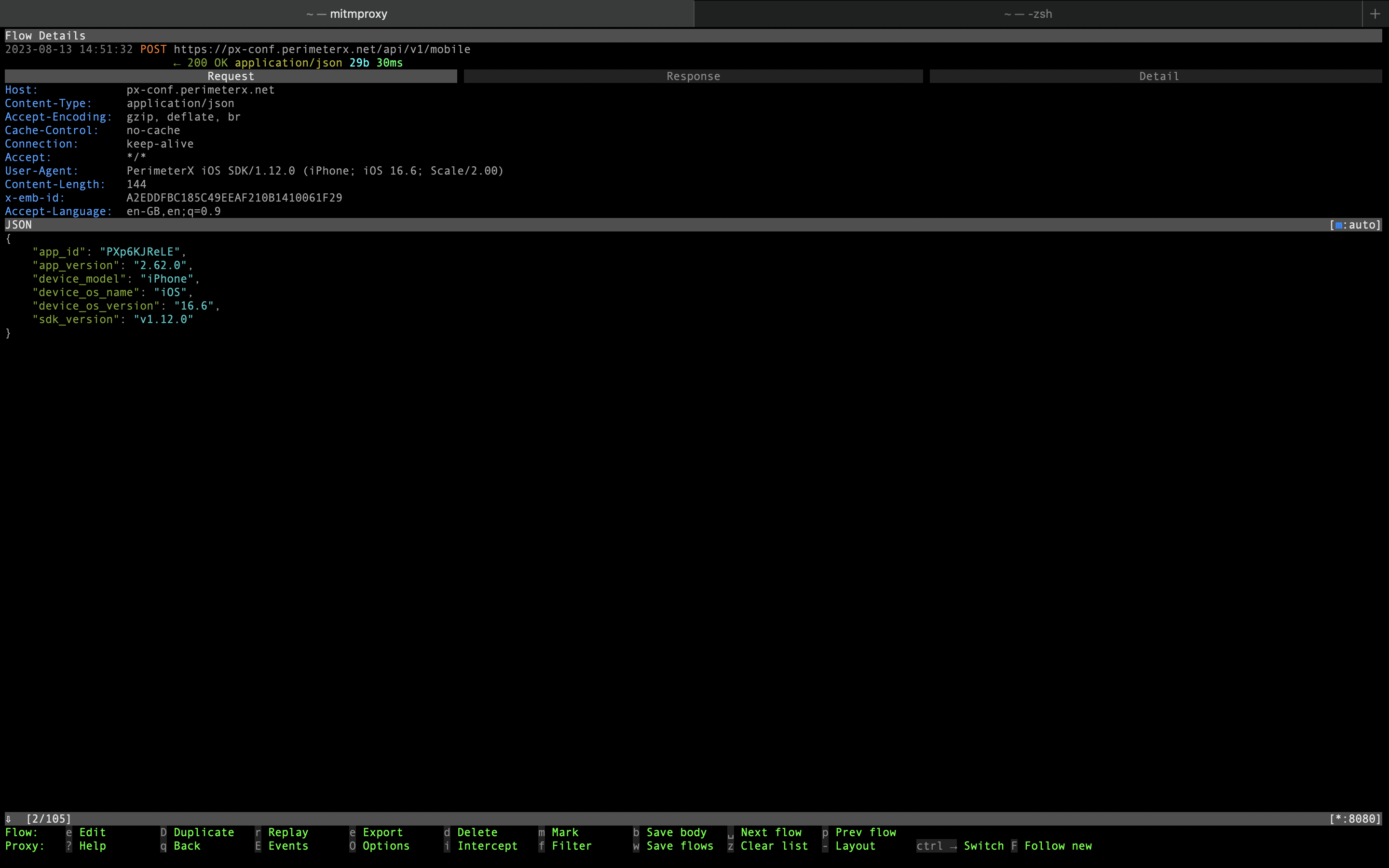
- Early in the app lifecycle it sends a request to PerimeterX API. This means that PerimeterX is also used to fight automation.
{kind=link}
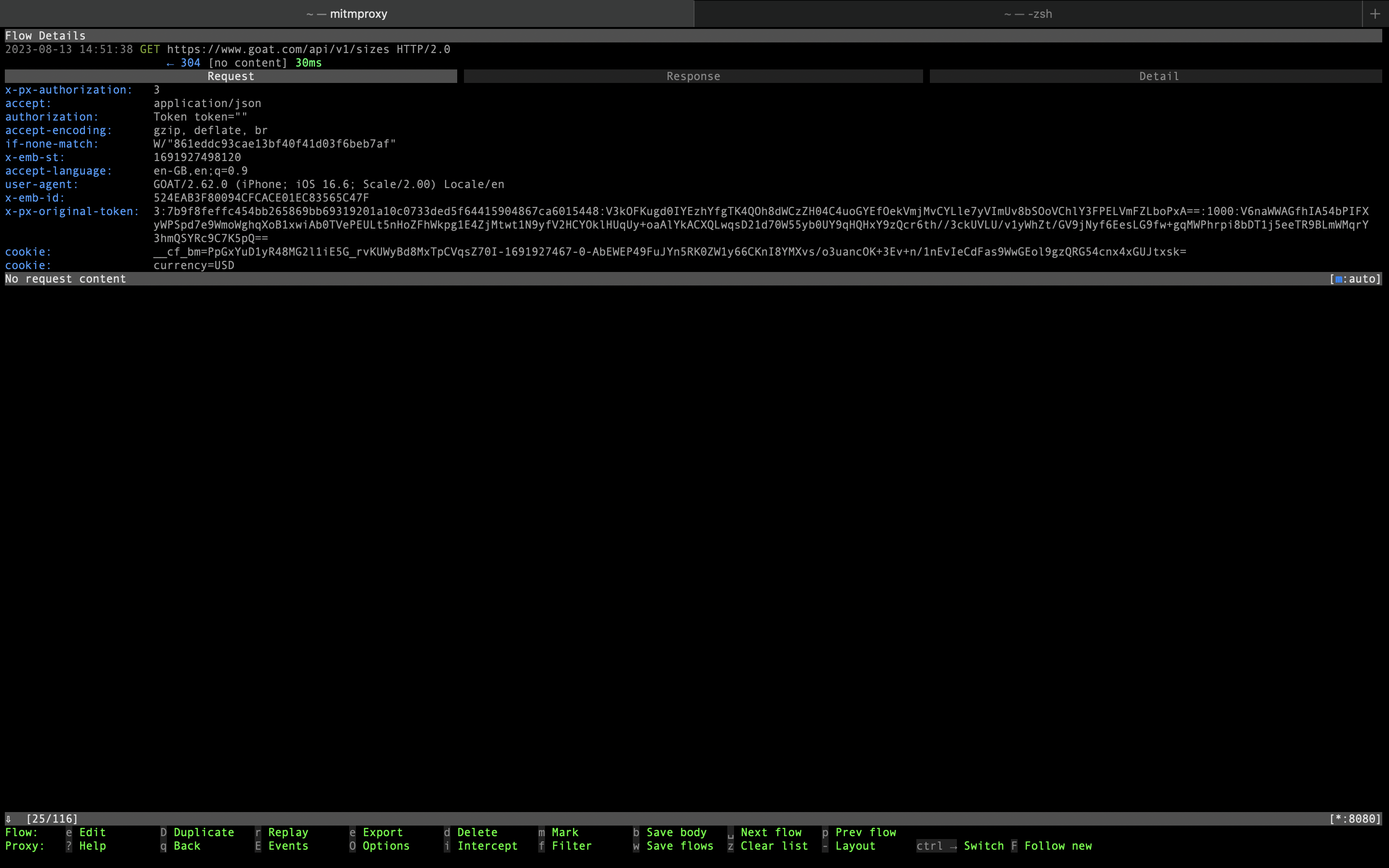
- Some requests have
x-px-authorizationandx-px-original-tokenheaders that are related to PerimeterX. Furthermore,__cf_bmcookie is present on some requests. - There’s
authorizationheader with empty value. We expect this value to be set when app is being used after logging in.
{kind=link}
- Some requests go to goat.cnstrc.com domain and are not covered by PX/CF.
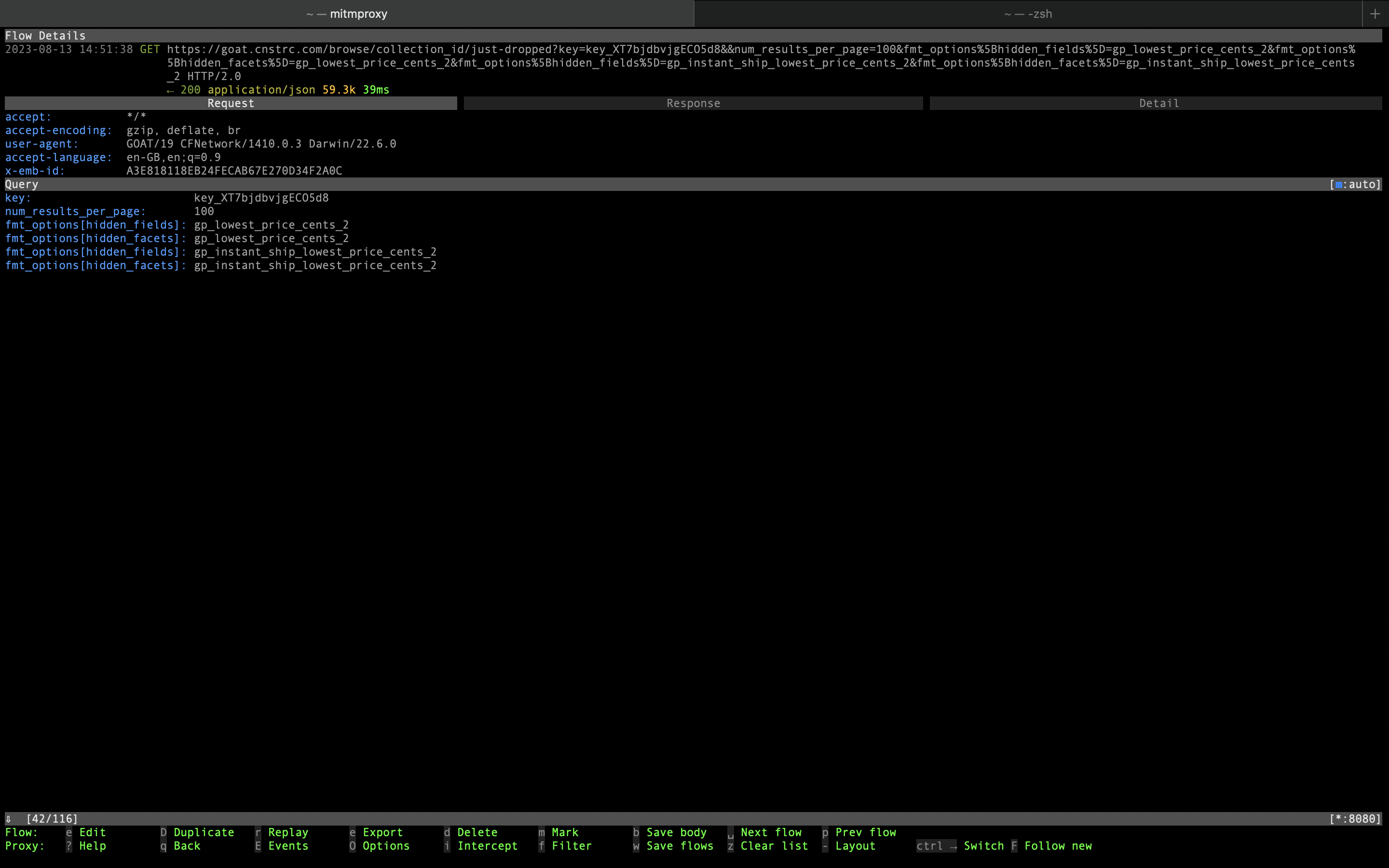{kind=link}
Let us start with the simple stuff first. Product data scraping is a common
thing that web scraper developers do. So let’s do that, but through the mobile
API. On the mobile GUI we access the Search tab, type in a search query, press
z to clean the flows captured by mitmproxy and then press the search button.
{kind=link}
{kind=link}
We see one request to goat.cnstrc.com and some more requests to images.goat.com.
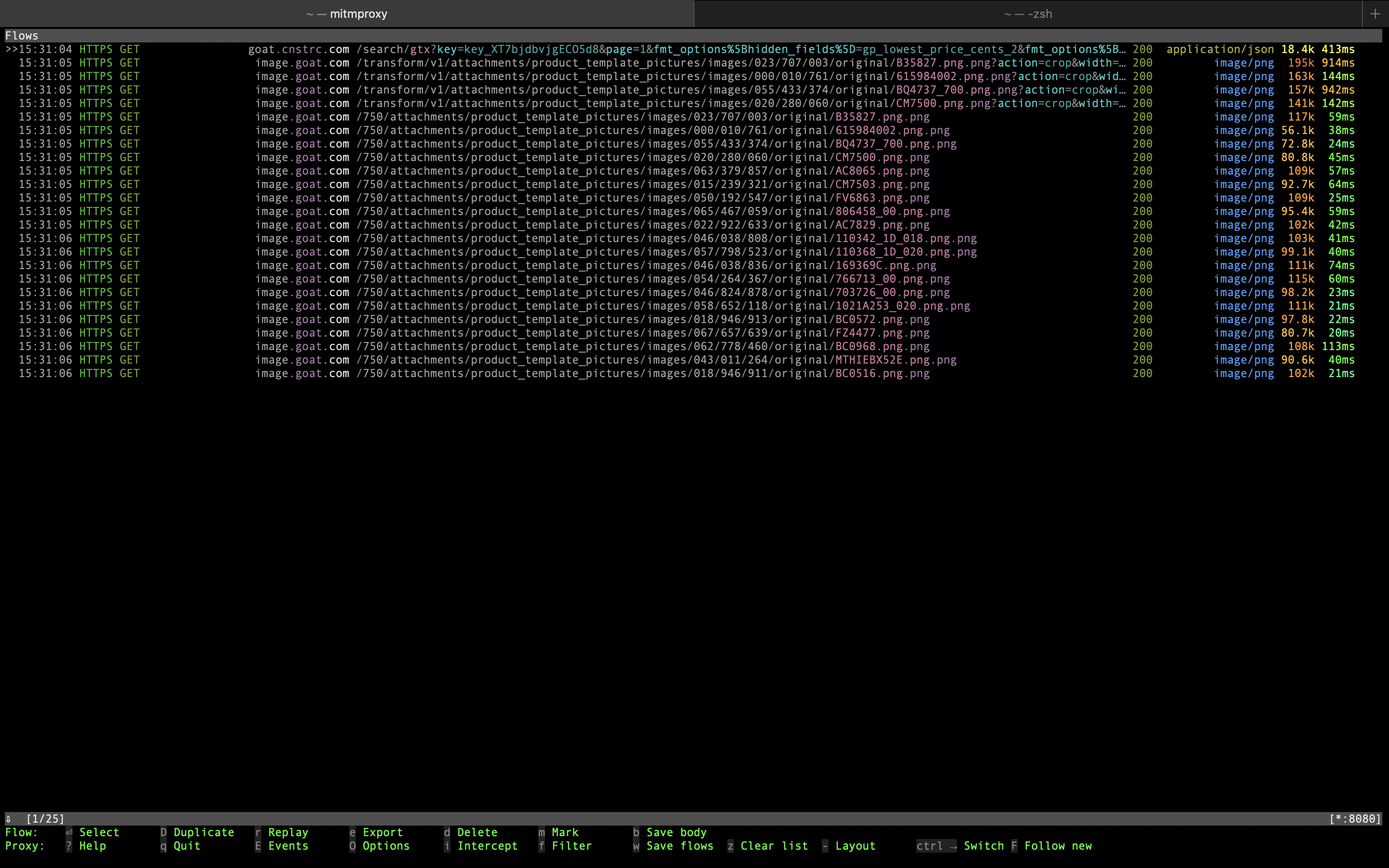{kind=link}
The first one is of primary interest to us, as it seems to return some subset of product data in the JSON payload. Last component of the URL path is the search query that was typed into the app.
We want to export this request as curl command. We position the curson on it
in the flow list view, press e and choose 1) curl from list of options in
the little dialog box. Then we type the file path (e.g. search.curl) into
bottom part of user interface.
curl -H 'accept: */*' --compressed -H 'user-agent: GOAT/19 CFNetwork/1410.0.3 Darwin/22.6.0' -H 'accept-language: en-GB,en;q=0.9' -H 'x-emb-id: 7E2DEE62833C40A0B733085027D1A5BC' 'https://goat.cnstrc.com/search/gtx?key=key_XT7bjdbvjgECO5d8&page=1&fmt_options%5Bhidden_fields%5D=gp_lowest_price_cents_2&fmt_options%5Bhidden_facets%5D=gp_lowest_price_cents_2&fmt_options%5Bhidden_fields%5D=gp_instant_ship_lowest_price_cents_2&fmt_options%5Bhidden_facets%5D=gp_instant_ship_lowest_price_cents_2&features%5Bdisplay_variations%5D=true&feature_variants%5Bdisplay_variations%5D=matched&variations_map=%7B%22dtype%22:%22object%22,%22group_by%22:%5B%7B%22name%22:%22product_condition%22,%22field%22:%22data.product_condition%22%7D,%7B%22name%22:%22box_condition%22,%22field%22:%22data.box_condition%22%7D%5D,%22values%22:%7B%22min_regional_instant_ship_price%22:%7B%22field%22:%22data.gp_instant_ship_lowest_price_cents_2%22,%22aggregation%22:%22min%22%7D,%22min_regional_price%22:%7B%22field%22:%22data.gp_lowest_price_cents_2%22,%22aggregation%22:%22min%22%7D%7D%7D'
By putting this into curlconverter we get the following Python snippet:
import requests
headers = {
'accept': '*/*',
'user-agent': 'GOAT/19 CFNetwork/1410.0.3 Darwin/22.6.0',
'accept-language': 'en-GB,en;q=0.9',
'x-emb-id': '7E2DEE62833C40A0B733085027D1A5BC',
}
response = requests.get(
'https://goat.cnstrc.com/search/gtx?key=key_XT7bjdbvjgECO5d8&page=1&fmt_options%5Bhidden_fields%5D=gp_lowest_price_cents_2&fmt_options%5Bhidden_facets%5D=gp_lowest_price_cents_2&fmt_options%5Bhidden_fields%5D=gp_instant_ship_lowest_price_cents_2&fmt_options%5Bhidden_facets%5D=gp_instant_ship_lowest_price_cents_2&features%5Bdisplay_variations%5D=true&feature_variants%5Bdisplay_variations%5D=matched&variations_map=%7B%22dtype%22:%22object%22,%22group_by%22:%5B%7B%22name%22:%22product_condition%22,%22field%22:%22data.product_condition%22%7D,%7B%22name%22:%22box_condition%22,%22field%22:%22data.box_condition%22%7D%5D,%22values%22:%7B%22min_regional_instant_ship_price%22:%7B%22field%22:%22data.gp_instant_ship_lowest_price_cents_2%22,%22aggregation%22:%22min%22%7D,%22min_regional_price%22:%7B%22field%22:%22data.gp_lowest_price_cents_2%22,%22aggregation%22:%22min%22%7D%7D%7D',
headers=headers,
)
I don’t exactly like that it didn’t decode the URL parameters into Python dict,
but this is a starting point for the script to be written.
We see that there’s a page parameter with values starting from one. This
covers the API pagination aspect.
In case you are wondering about x-emb-id header it is related to
mobile analytics solution
provided by Embrace Mobile, Inc.
The next step is getting some product details via API. When we tap on one of the search results we see a bunch of HTTPS requests, most of them being made to subdomains of goat.com domain.
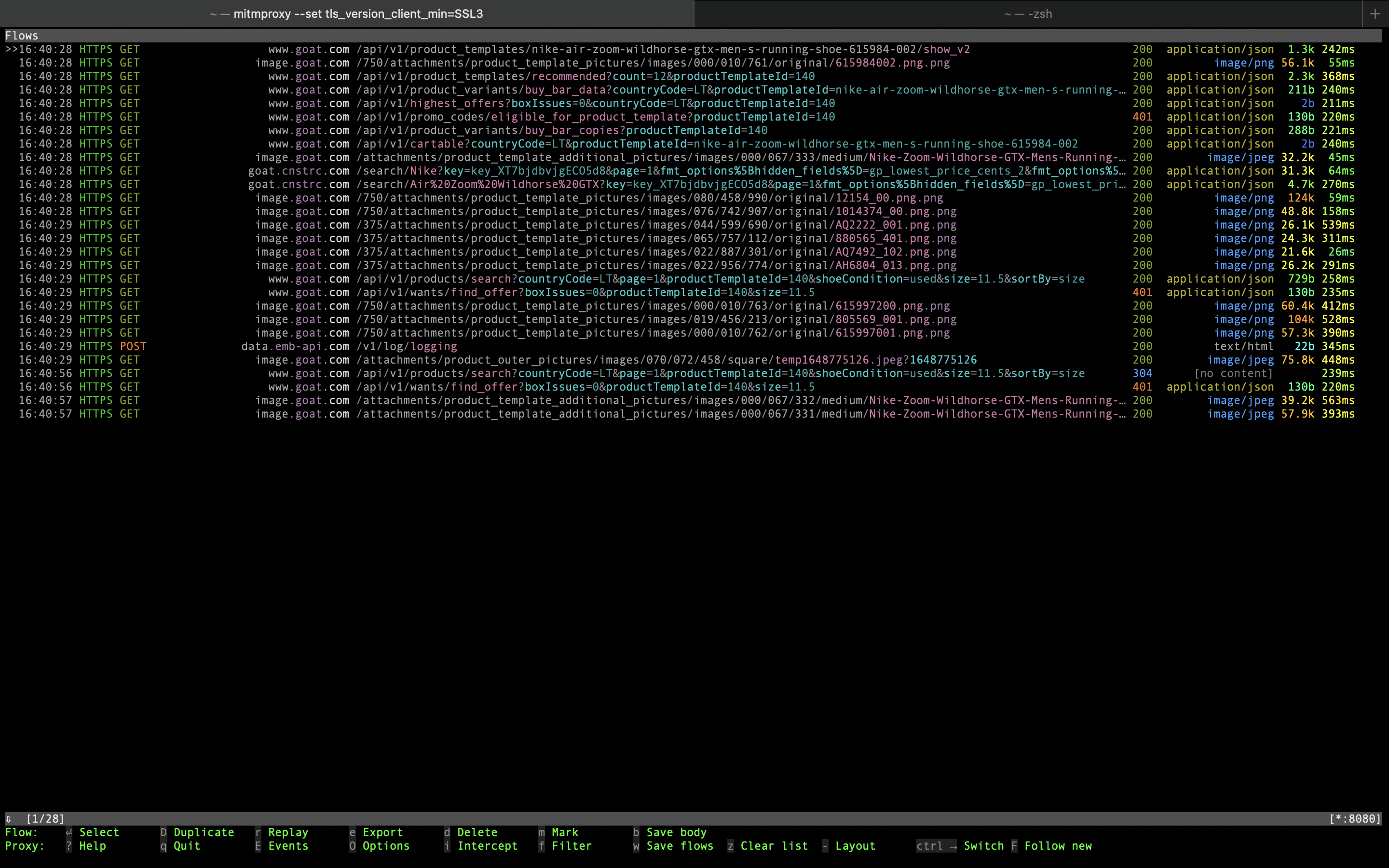{kind=link}
Let us explore what we have here. There’s a request to product template
endpoint /api/v1/product_templates/.../show_v2 that takes product URL slug
(e.g. terrex-swift-r2-mid-gtx-triple-black-cm7500) as part of URL path
and gives the app a numeric product template ID to be used in some of the
further API calls. It also provides some data is common across all product
variants. To scrape it, our code will reproduce this API call with slug value
it got from search API.
Like we did with search API request, we export this one to curl snippet:
curl -H 'x-px-authorization: 3' -H 'accept: application/json' -H 'authorization: Token token=""' --compressed -H 'accept-language: en-GB,en;q=0.9' -H 'x-emb-st: 1691934124434' -H 'user-agent: GOAT/2.62.0 (iPhone; iOS 16.6; Scale/2.00) Locale/en' -H 'x-emb-id: A131256965044D838D97E9AEC3CC32DE' -H 'x-px-original-token: 3:7b9f8feffc454bb265869bb69319201a10c0733ded5f64415904867ca6015448:V3kOFKugd0IYEzhYfgTK4QOh8dWCzZH04C4uoGYEfOekVmjMvCYLle7yVImUv8bSOoVChlY3FPELVmFZLboPxA==:1000:V6naWWAGfhIA54bPIFXyWPSpd7e9WmoWghqXoB1xwiAb0TVePEULt5nHoZFhWkpg1E4ZjMtwt1N9yfV2HCYOklHUqUy+oaAlYkACXQLwqsD21d70W55yb0UY9qHQHxY9zQcr6th//3ckUVLU/v1yWhZt/GV9jNyf6EesLG9fw+gqMWPhrpi8bDT1j5eeTR9BLmWMqrY3hmQSYRc9C7K5pQ==' -H 'cookie: __cf_bm=SHyG5WOKr777DofsXNbK3U29rw2zT0.FAfklx3N4xlA-1691934028-0-AUJcAbBlN7VoM9Sv8KU4ADRc7kRMROE5dN8u/rsVpl+cxdtwaLQTX/D/tIGlWKDEjaZfMbkE+PaMCzCrlGheIbI=' -H 'cookie: currency=EUR' https://www.goat.com/api/v1/product_templates/terrex-swift-r2-mid-gtx-triple-black-cm7500/show_v2
We also convert this snippet to Python:
import requests
cookies = {
'__cf_bm': 'SHyG5WOKr777DofsXNbK3U29rw2zT0.FAfklx3N4xlA-1691934028-0-AUJcAbBlN7VoM9Sv8KU4ADRc7kRMROE5dN8u/rsVpl+cxdtwaLQTX/D/tIGlWKDEjaZfMbkE+PaMCzCrlGheIbI=',
'currency': 'EUR',
}
headers = {
'x-px-authorization': '3',
'accept': 'application/json',
'authorization': 'Token token=""',
'accept-language': 'en-GB,en;q=0.9',
'x-emb-st': '1691934124434',
'user-agent': 'GOAT/2.62.0 (iPhone; iOS 16.6; Scale/2.00) Locale/en',
'x-emb-id': 'A131256965044D838D97E9AEC3CC32DE',
'x-px-original-token': '3:7b9f8feffc454bb265869bb69319201a10c0733ded5f64415904867ca6015448:V3kOFKugd0IYEzhYfgTK4QOh8dWCzZH04C4uoGYEfOekVmjMvCYLle7yVImUv8bSOoVChlY3FPELVmFZLboPxA==:1000:V6naWWAGfhIA54bPIFXyWPSpd7e9WmoWghqXoB1xwiAb0TVePEULt5nHoZFhWkpg1E4ZjMtwt1N9yfV2HCYOklHUqUy+oaAlYkACXQLwqsD21d70W55yb0UY9qHQHxY9zQcr6th//3ckUVLU/v1yWhZt/GV9jNyf6EesLG9fw+gqMWPhrpi8bDT1j5eeTR9BLmWMqrY3hmQSYRc9C7K5pQ==',
# 'cookie': '__cf_bm=SHyG5WOKr777DofsXNbK3U29rw2zT0.FAfklx3N4xlA-1691934028-0-AUJcAbBlN7VoM9Sv8KU4ADRc7kRMROE5dN8u/rsVpl+cxdtwaLQTX/D/tIGlWKDEjaZfMbkE+PaMCzCrlGheIbI=; currency=EUR',
}
response = requests.get(
'https://www.goat.com/api/v1/product_templates/terrex-swift-r2-mid-gtx-triple-black-cm7500/show_v2',
cookies=cookies,
headers=headers,
)
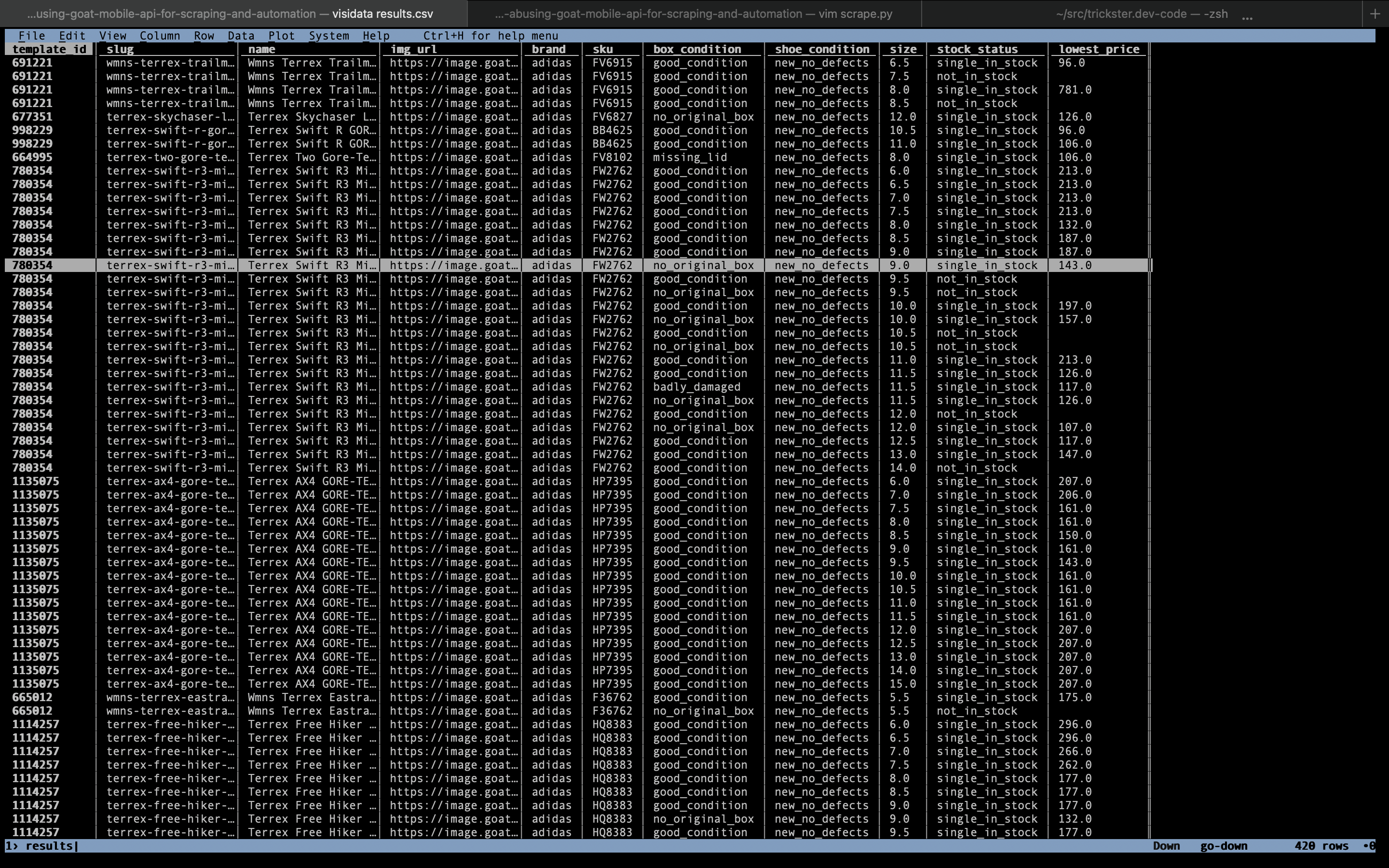
For the sake of example, we will save product name, main image URL and SKU from the API response here.
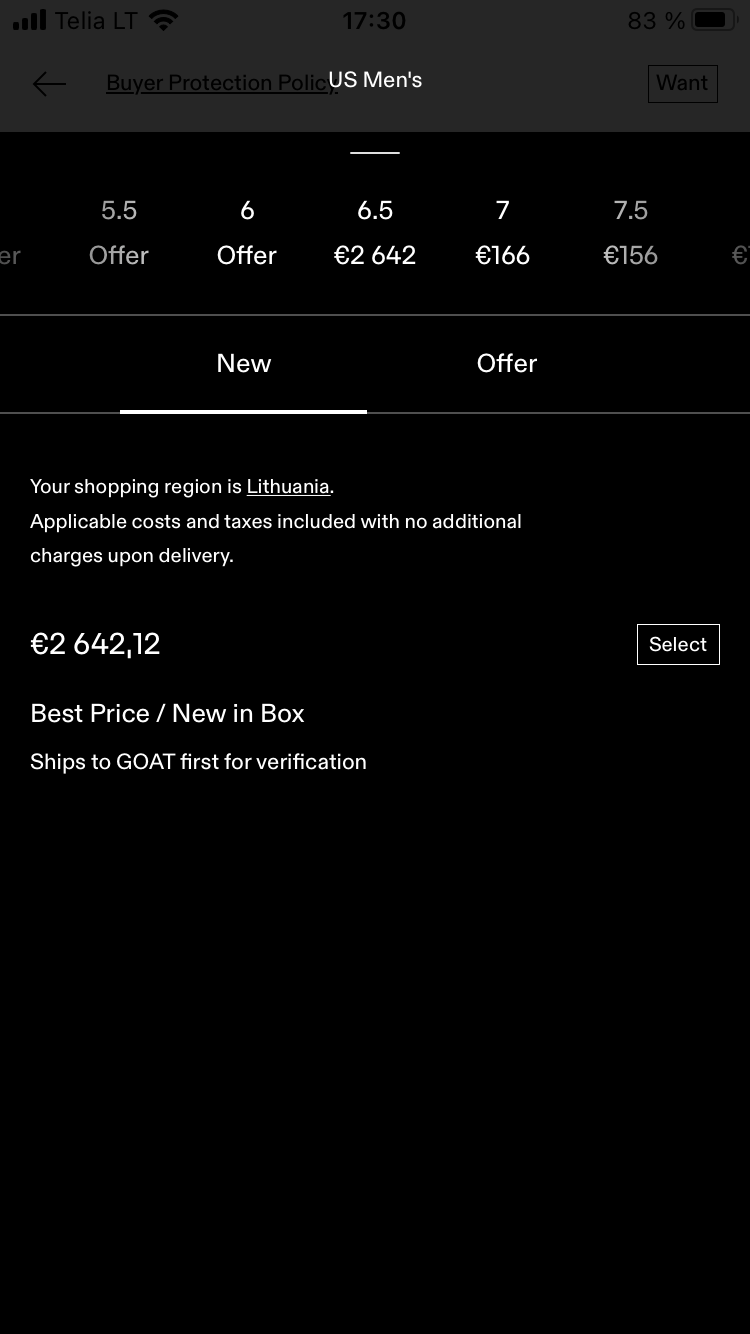
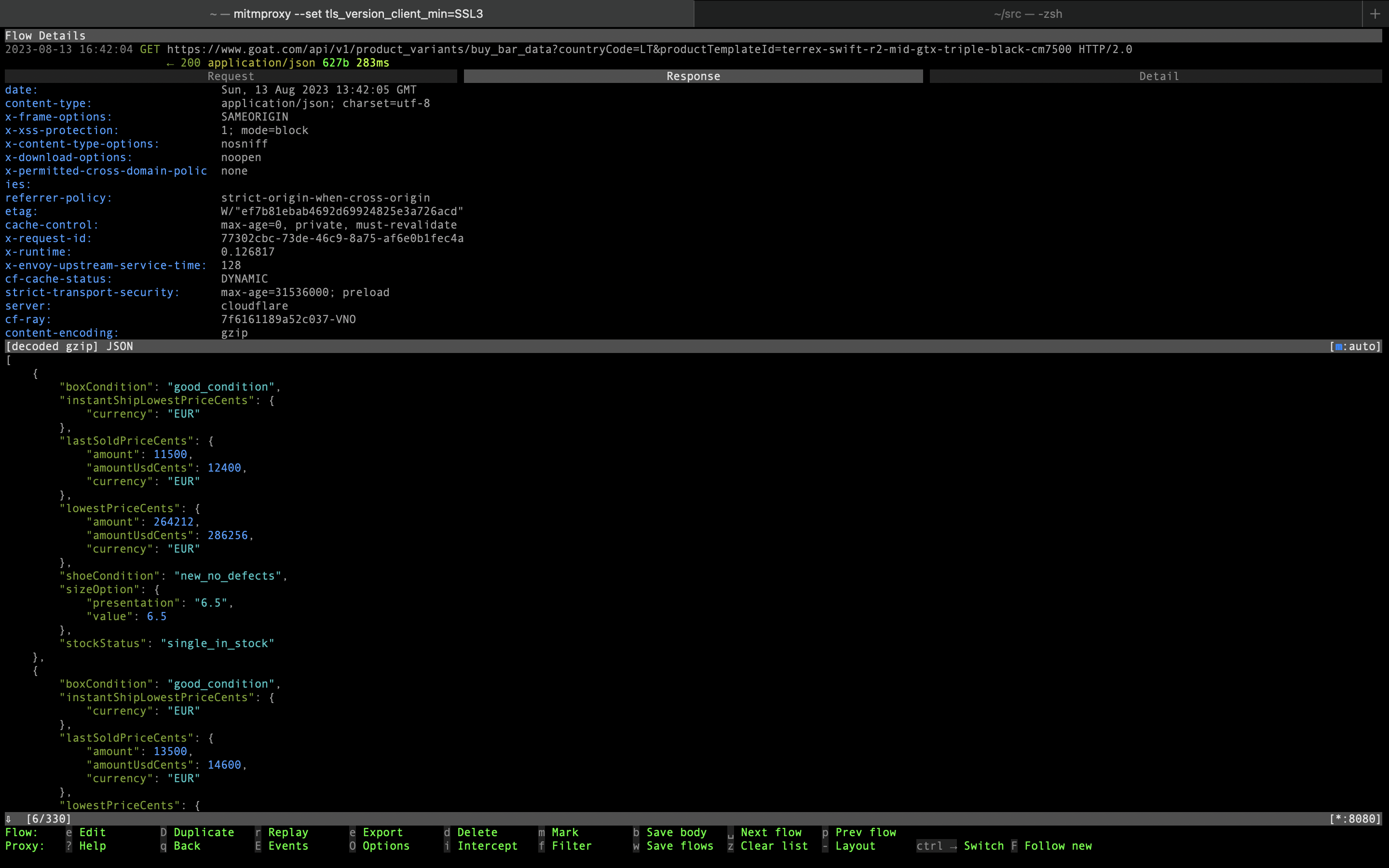
We also want to save some price data and availability data. The part of UI that
shows prices and last sale amounts is populated by the /api/v2/product_variants/buy_bar_data
endpoint. We extract the curl snippet from mitmproxy again:
curl -H 'x-px-authorization: 3' -H 'accept: application/json' -H 'authorization: Token token=""' --compressed -H 'accept-language: en-GB,en;q=0.9' -H 'x-emb-st: 1691934124855' -H 'user-agent: GOAT/2.62.0 (iPhone; iOS 16.6; Scale/2.00) Locale/en' -H 'x-emb-id: 9E8BF79CF66F4912A122C3C38F872E0E' -H 'x-px-original-token: 3:7b9f8feffc454bb265869bb69319201a10c0733ded5f64415904867ca6015448:V3kOFKugd0IYEzhYfgTK4QOh8dWCzZH04C4uoGYEfOekVmjMvCYLle7yVImUv8bSOoVChlY3FPELVmFZLboPxA==:1000:V6naWWAGfhIA54bPIFXyWPSpd7e9WmoWghqXoB1xwiAb0TVePEULt5nHoZFhWkpg1E4ZjMtwt1N9yfV2HCYOklHUqUy+oaAlYkACXQLwqsD21d70W55yb0UY9qHQHxY9zQcr6th//3ckUVLU/v1yWhZt/GV9jNyf6EesLG9fw+gqMWPhrpi8bDT1j5eeTR9BLmWMqrY3hmQSYRc9C7K5pQ==' -H 'cookie: __cf_bm=SHyG5WOKr777DofsXNbK3U29rw2zT0.FAfklx3N4xlA-1691934028-0-AUJcAbBlN7VoM9Sv8KU4ADRc7kRMROE5dN8u/rsVpl+cxdtwaLQTX/D/tIGlWKDEjaZfMbkE+PaMCzCrlGheIbI=' -H 'cookie: currency=EUR' 'https://www.goat.com/api/v1/product_variants/buy_bar_data?countryCode=US&productTemplateId=terrex-swift-r2-mid-gtx-triple-black-cm7500'
{kind=link}
{kind=link}
The corresponding Python snippet is:
import requests
cookies = {
'__cf_bm': 'SHyG5WOKr777DofsXNbK3U29rw2zT0.FAfklx3N4xlA-1691934028-0-AUJcAbBlN7VoM9Sv8KU4ADRc7kRMROE5dN8u/rsVpl+cxdtwaLQTX/D/tIGlWKDEjaZfMbkE+PaMCzCrlGheIbI=',
'currency': 'EUR',
}
headers = {
'x-px-authorization': '3',
'accept': 'application/json',
'authorization': 'Token token=""',
'accept-language': 'en-GB,en;q=0.9',
'x-emb-st': '1691934124855',
'user-agent': 'GOAT/2.62.0 (iPhone; iOS 16.6; Scale/2.00) Locale/en',
'x-emb-id': '9E8BF79CF66F4912A122C3C38F872E0E',
'x-px-original-token': '3:7b9f8feffc454bb265869bb69319201a10c0733ded5f64415904867ca6015448:V3kOFKugd0IYEzhYfgTK4QOh8dWCzZH04C4uoGYEfOekVmjMvCYLle7yVImUv8bSOoVChlY3FPELVmFZLboPxA==:1000:V6naWWAGfhIA54bPIFXyWPSpd7e9WmoWghqXoB1xwiAb0TVePEULt5nHoZFhWkpg1E4ZjMtwt1N9yfV2HCYOklHUqUy+oaAlYkACXQLwqsD21d70W55yb0UY9qHQHxY9zQcr6th//3ckUVLU/v1yWhZt/GV9jNyf6EesLG9fw+gqMWPhrpi8bDT1j5eeTR9BLmWMqrY3hmQSYRc9C7K5pQ==',
# 'cookie': '__cf_bm=SHyG5WOKr777DofsXNbK3U29rw2zT0.FAfklx3N4xlA-1691934028-0-AUJcAbBlN7VoM9Sv8KU4ADRc7kRMROE5dN8u/rsVpl+cxdtwaLQTX/D/tIGlWKDEjaZfMbkE+PaMCzCrlGheIbI=; currency=EUR',
}
params = {
'countryCode': 'LT',
'productTemplateId': 'terrex-swift-r2-mid-gtx-triple-black-cm7500',
}
response = requests.get(
'https://www.goat.com/api/v1/product_variants/buy_bar_data',
params=params,
cookies=cookies,
headers=headers,
)
Quick experiment shows that removing __cf_bm cookie does not cause the requests
to be blocked. However a default currency is set via another cookie, which we
probably want to keep.
Since PerimeterX blocks requests based on source autonomous systems and IP reputation we need to route the requests through a proxy pool. I find that ISP proxies from Bright Data are good enough for this.
One last thing to note is that some APIs are meant to be used after login and thus don’t provide any data at this point.
A simple Python script to implement GOAT mobile API scraping is as follows:
#!/usr/bin/python3
import csv
import sys
from pprint import pprint
from urllib.parse import quote
import time
import requests
# ISP proxy URL
PROXY_URL = "[REDACTED]"
COUNTRY_CODE = "US"
CURRENCY = "USD"
FIELDNAMES = [
"template_id",
"slug",
"name",
"img_url",
"brand",
"sku",
"box_condition",
"shoe_condition",
"size",
"stock_status",
"lowest_price",
]
RETRIES = 5
def create_session():
session = requests.Session()
session.headers = {
"x-px-authorization": "3",
"accept": "application/json",
"authorization": 'Token token=""',
"accept-language": "en-GB,en;q=0.9",
"x-emb-st": "1691934124434",
"user-agent": "GOAT/2.62.0 (iPhone; iOS 16.6; Scale/2.00) Locale/en",
"x-emb-id": "A131256965044D838D97E9AEC3CC32DE",
"x-px-original-token": "3:7b9f8feffc454bb265869bb69319201a10c0733ded5f64415904867ca6015448:V3kOFKugd0IYEzhYfgTK4QOh8dWCzZH04C4uoGYEfOekVmjMvCYLle7yVImUv8bSOoVChlY3FPELVmFZLboPxA==:1000:V6naWWAGfhIA54bPIFXyWPSpd7e9WmoWghqXoB1xwiAb0TVePEULt5nHoZFhWkpg1E4ZjMtwt1N9yfV2HCYOklHUqUy+oaAlYkACXQLwqsD21d70W55yb0UY9qHQHxY9zQcr6th//3ckUVLU/v1yWhZt/GV9jNyf6EesLG9fw+gqMWPhrpi8bDT1j5eeTR9BLmWMqrY3hmQSYRc9C7K5pQ==",
}
session.proxies = {"http": PROXY_URL, "https": PROXY_URL}
session.cookies.set("currency", CURRENCY)
return session
def get_product_template_data(session, product_slug):
url = "https://www.goat.com/api/v1/product_templates/{}/show_v2".format(product_slug)
resp = session.get(url)
print(resp.url)
return resp.json()
def get_buy_bar_data(session, product_slug):
url = "https://www.goat.com/api/v1/product_variants/buy_bar_data"
params = {
'countryCode': COUNTRY_CODE,
'productTemplateId': product_slug
}
tries_left = RETRIES
while tries_left > 0:
resp = session.get(url, params=params)
print(resp.url)
if resp.status_code == 200:
break
tries_left -= 1
time.sleep(1)
if resp.status_code == 200:
return resp.json()
else:
return None
def scrape_search(session, search_query):
page = 1
url = "https://goat.cnstrc.com/search/" + quote(search_query)
params = {
"key": "key_XT7bjdbvjgECO5d8",
"page": str(page),
"fmt_options[hidden_fields]": "gp_instant_ship_lowest_price_cents_2",
"fmt_options[hidden_facets]": "gp_instant_ship_lowest_price_cents_2",
"features[display_variations]": "true",
"feature_variants[display_variations]": "matched",
"variations_map": '{"dtype":"object","group_by":[{"name":"product_condition","field":"data.product_condition"},{"name":"box_condition","field":"data.box_condition"}],"values":{"min_regional_instant_ship_price":{"field":"data.gp_instant_ship_lowest_price_cents_2","aggregation":"min"},"min_regional_price":{"field":"data.gp_lowest_price_cents_2","aggregation":"min"}}}',
}
while True:
resp = session.get(url, params=params)
print(resp.url)
json_dict = resp.json()
per_page = json_dict.get("request", dict()).get("num_results_per_page")
results = json_dict.get("response", dict()).get("results", [])
for result_dict in results:
slug = result_dict.get("data", dict()).get("slug")
yield slug
if len(results) < per_page:
break
page += 1
params['page'] = str(page)
def main():
if len(sys.argv) != 2:
print("Usage:")
print("{} <query>".format(sys.argv[0]))
return
query = sys.argv[1]
session = create_session()
out_f = open("results.csv", "w", encoding="utf-8")
csv_writer = csv.DictWriter(out_f, fieldnames=FIELDNAMES, lineterminator="\n")
csv_writer.writeheader()
for slug in scrape_search(session, query):
print(slug)
template_data = get_product_template_data(session, slug)
template_id = template_data.get("id")
name = template_data.get("name")
img_url = template_data.get("mainPictureUrl")
brand = template_data.get("sizeBrand")
sku = template_data.get("sku")
buy_bar_data = get_buy_bar_data(session, slug)
for buy_bar_dict in buy_bar_data:
box_condition = buy_bar_dict.get("boxCondition")
shoe_condition = buy_bar_dict.get("shoeCondition")
size = buy_bar_dict.get("sizeOption", dict()).get("value")
stock_status = buy_bar_dict.get("stockStatus")
lowest_price = buy_bar_dict.get("lowestPriceCents", dict()).get("amount")
if type(lowest_price) == int:
lowest_price = lowest_price / 100.0
row = {
"template_id": template_id,
"slug": slug,
"name": name,
"img_url": img_url,
"brand": brand,
"sku": sku,
"box_condition": box_condition,
"shoe_condition": shoe_condition,
"size": size,
"stock_status": stock_status,
"lowest_price": lowest_price
}
pprint(row)
csv_writer.writerow(row)
out_f.close()
if __name__ == "__main__":
main()
Let us go through the code. The script gets the search query via CLI parameter
(sys.argv[1]) and uses that to scrape URL slugs from the search API. This
is done in scrape_search() function. The code here is based on the first
Python snippet we got earlier. We implement page traversal by incrementing
page parameter until the current page has less results that a full page
would (threshold value is in request.num_results_per_page). This function is
a generator function - by using yield instead of return we make it so
that search API requests are done on as-needed basis and the function call
can be iterated upon (which we do in main(), as technically the return
value is an iterable generator object).
When we get the slug, scrape the two other endpoints for product template and
pricing/availability/product condition data (a requests.Session object
is used to keep the HTTP headers, cookies and proxy settings between requests).
Since GOAT is a two-sided marketplace that allows reselling of used or defective
shoes we also grab the fields about shoe and box condition. Data is merged into
Python dict and written out into CSV file.
{kind=link}
Now, there is PerimeterX SDK being integrated into GOAT mobile app. But as long
we generate our traffic through good-enough proxies and reproduce the original
headers we can scrape the data just fine, more or less. One problem is that
sometimes 5 retries are not enough to get the data from buy_bar_data endpoint
when PerimeterX starts asking for captcha solution. Modifying get_buy_bar_data()
function to force proxy rotation on failed request is left as an exercise for
the reader. But the larger point here is that anti-automation security measures
on mobile app APIs are often not very tight and can be easily defeated even for
prominent, well funded targets such as GOAT. To be fair it is harder to scrape
behind login, but that’s a topic for another post.