World Wide Web is a network of HTML documents (pages) with hyperlinks between them. Consider a directed graph that consists of vertices representing pages and edges representing links between pages. For a given page, links from other pages to that page are known as backlinks. Backlinks are of significance to search engine ranking of the site, thus making them of importance to SEO people, digital marketers and growth hackers. Furthermore, OSINT practitioners and web scraper developers may want to find sites/pages linking to certain pages/files on the web as it would help traversing the data landscape. Major SEO SaaS apps (Ahrefs, SEMRush, Moz, etc.) are sourcing their data via large-scale web crawling operations that build up a fairly complete maps of the web and thus can be leveraged for this purpose. In this post we will go through an example of abusing a free Ahrefs Backlink Checker to show how a list of backlinks can be scraped from a SEO tool.
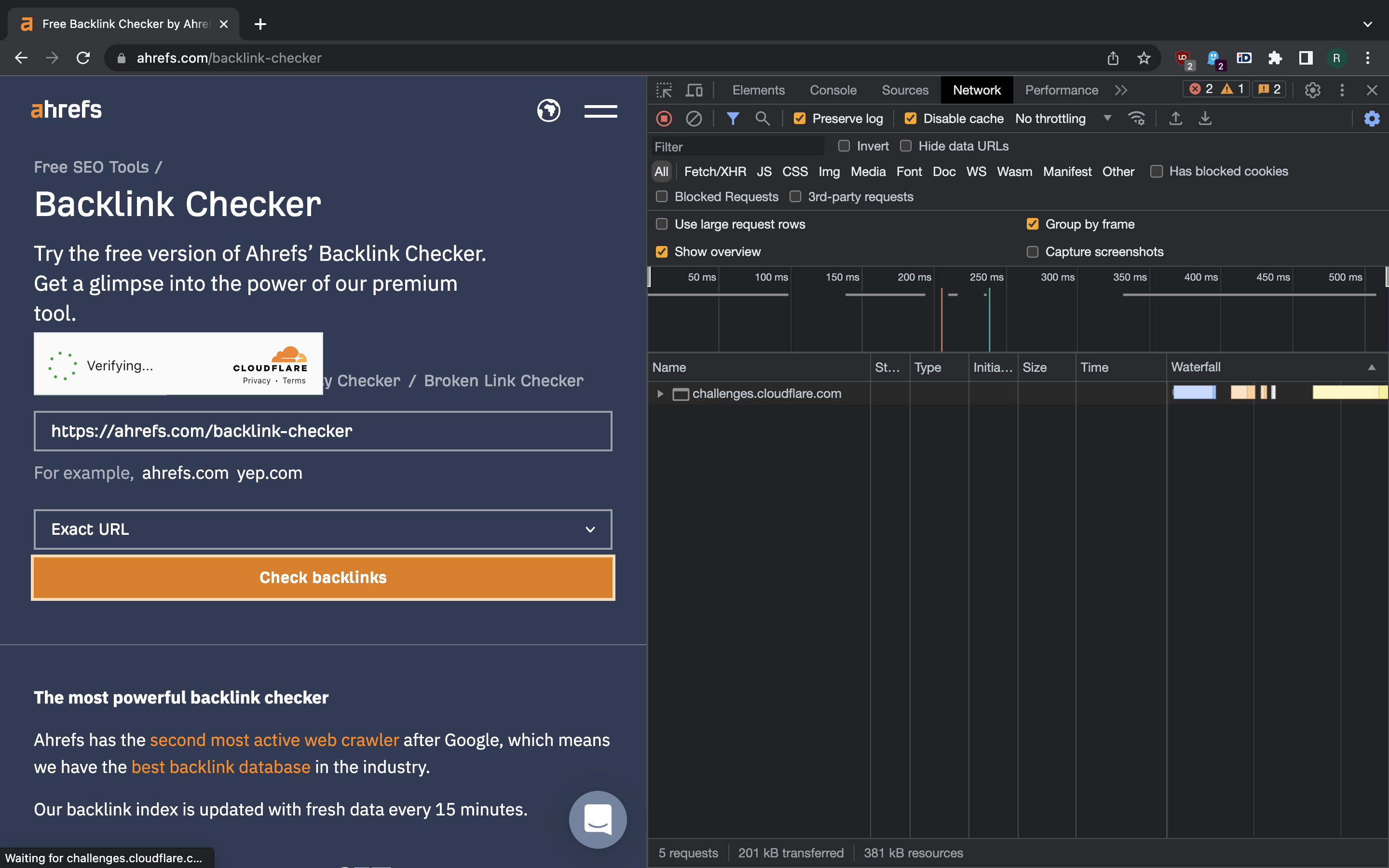
Let us explore the request flow that happens when the user pastes an URL into the form and presses the “Check backlinks” button. We are dealing with Cloudflare Turnstile - a drop-in alternative to Google reCaptcha that may ask for checkbox to be clicked, but largely tries to separate bots from humans by non-interactive means - probing the JS environment in the browser, JavaScript challenges, gathering a sample of user activity and so on. Since it is kind of captcha, we can use Anti-captcha service to solve it. For $2 we can buy a thousand solutions. In Chrome DevTools we can see a GET request to:
Value 0x4AAAAAAAAzi9ITzSN9xKMi is a site key - a unique value that identifies
this site in API interactions with Cloudflare. We will be passing it into the
Anti-captcha API.
{kind=link}
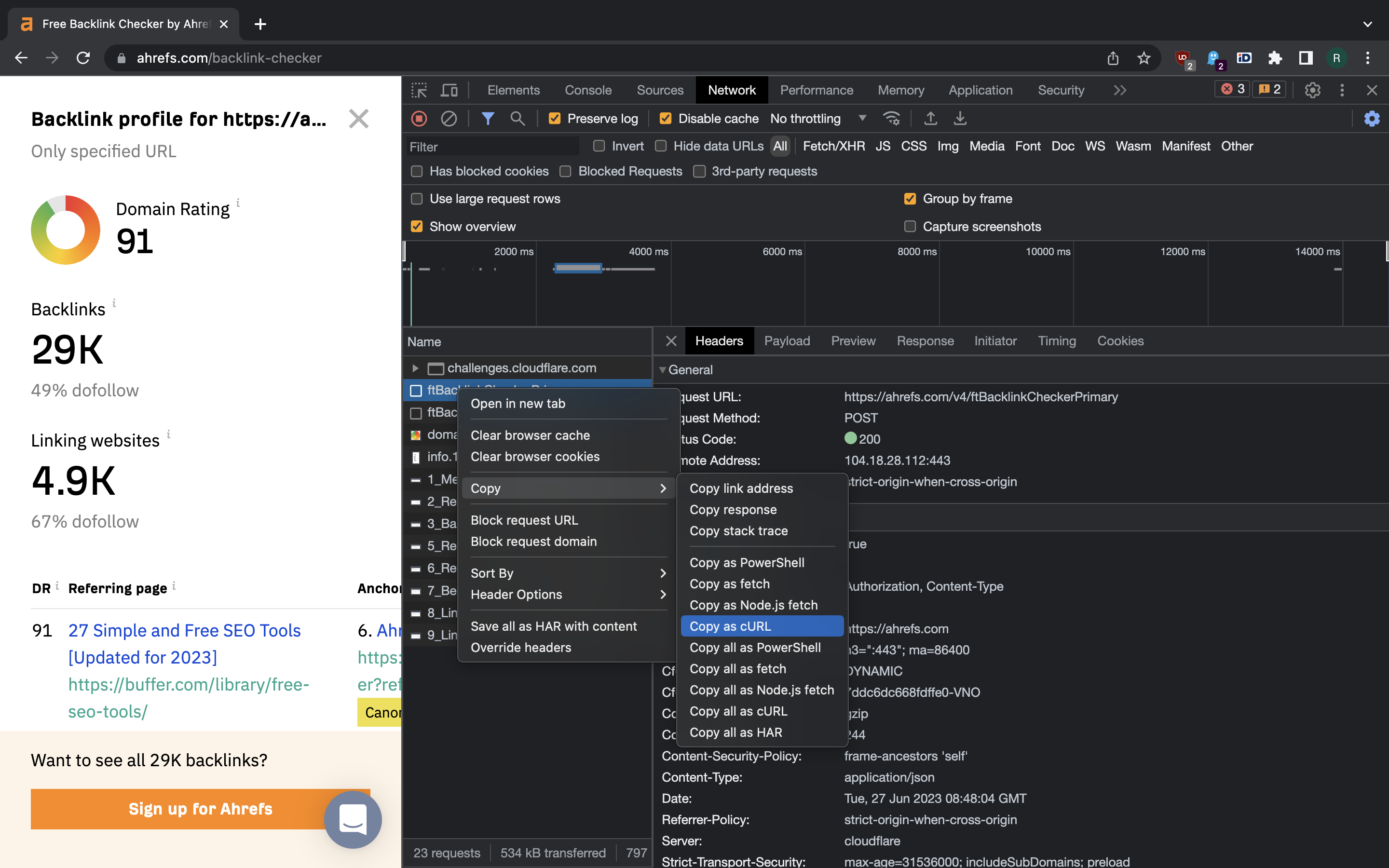
Once the site gets a captcha token from Cloudflare it launches two HTTP POST requests to the API. We extract both of them as curl snippets to be converted into Python code later.
{kind=link}
Curl command for the first request is:
curl 'https://ahrefs.com/v4/ftBacklinkCheckerPrimary' \
-H 'authority: ahrefs.com' \
-H 'accept: */*' \
-H 'accept-language: en-GB,en-US;q=0.9,en;q=0.8' \
-H 'cache-control: no-cache' \
-H 'content-type: application/json; charset=utf-8' \
-H 'cookie: __cf_bm=n2OYqOmarAhgWDxD3Tad6v1BAgLYFTtI3J8RxY9yapc-1687855654-0-AaF8nuZhwZT9A7zWj+Ojn1N58AhPC9jyUi+3Mfbpk/3pXYXEfdmpahcomXy/Bjv/TF6Qu3agnbRSquDnmjFC9RvKXWdwH50W/qipBYlv9DsD' \
-H 'origin: https://ahrefs.com' \
-H 'pragma: no-cache' \
-H 'referer: https://ahrefs.com/backlink-checker' \
-H 'sec-ch-ua: "Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: same-origin' \
-H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36' \
--data-raw '{"captcha":"0.wsyuoTAQbPdempTdrWisjoNqxj6LRJwGyP4nnYteWF9mHnSQZ-v5ofEyoc1MVEMuUz-N04E5CpdhwBaY9tPpAbDxNjnLKqdvF54VxppzncFjDg7JEbS3KSFxL-9Zkzk_lBx9DiuID2Ojn8s5N7X2BUCMtITXLqHt5kdJhgYphmtRHB4F8w6zXXaqi7830p1pKD17lRxiKIqCTJowy6Q5J-0vx-OqWtN1NN6sv6uGLBvOhyWVcxPO3GGSjnxisXwF5Y2Tzjbr7gGjnOrePZH2adWbJlxFbgQ0gyT-qul6dR7xq6-2IYUPp8ud0ZJ9qomq2xJinE5d_TCF_4is-5kpW4ovGBFbreotGh5sR_6vAEn2nq-SjovnxMya0fA9XreX5lUtU3yxymOa7BWWYZoQJg.s2MS2XLcbogodDf16-NyPA.1b163e522a4349cf7556af8134812e0f3e9d53c0dca934b6a60010e558162db8","mode":"exact","url":"https://ahrefs.com/backlink-checker"}' \
--compressed
In HTTP request payload there’s JSON object with captcha token and URL the user provided.
The JSON string in a response is of following form (reformatted for readability):
[
"Ok",
{
"data": {
"domainRating": 91.0,
"urlRating": 41,
"backlinks": 29409,
"refdomains": 4917,
"dofollowBacklinks": 49,
"dofollowRefdomains": 67
},
"signedInput": {
"input": {
"url": "ahrefs.com/backlink-checker",
"mode": "exact",
"validUntil": "2023-06-27T20:48:03Z"
},
"signature": "ed9ead2b3e58fc3f45374cd562c51c5ba563d560206d9870b4d7695ff5a14652"
}
}
]
This provides a status (Ok) and some SEO-related numbers about the URL/domain,
including a number of backlinks. If it was zero we could quit the API flow at
this point.
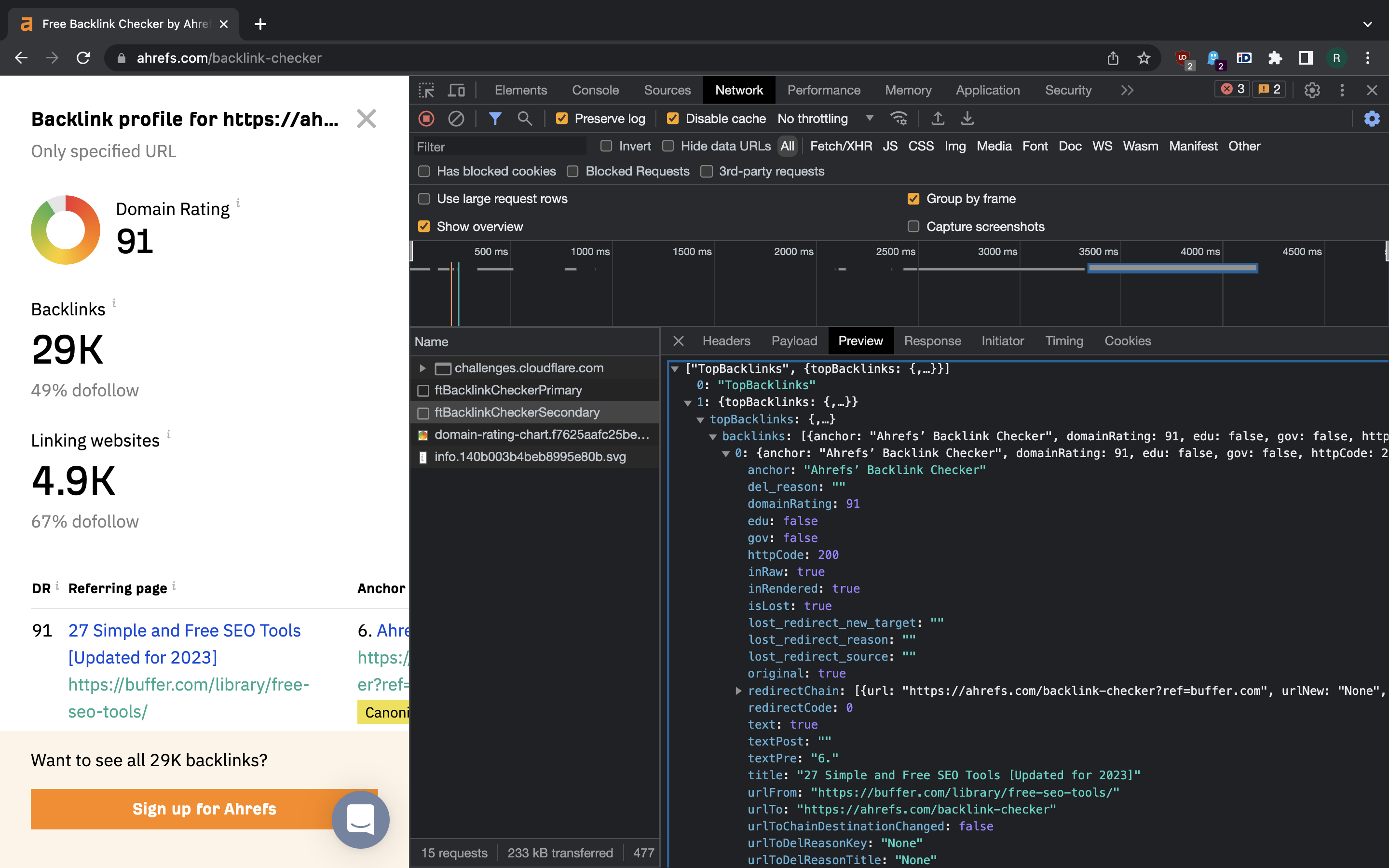
The signedInput object goes into the second API request:
curl 'https://ahrefs.com/v4/ftBacklinkCheckerSecondary' \
-H 'authority: ahrefs.com' \
-H 'accept: */*' \
-H 'accept-language: en-GB,en-US;q=0.9,en;q=0.8' \
-H 'cache-control: no-cache' \
-H 'content-type: application/json; charset=utf-8' \
-H 'cookie: __cf_bm=n2OYqOmarAhgWDxD3Tad6v1BAgLYFTtI3J8RxY9yapc-1687855654-0-AaF8nuZhwZT9A7zWj+Ojn1N58AhPC9jyUi+3Mfbpk/3pXYXEfdmpahcomXy/Bjv/TF6Qu3agnbRSquDnmjFC9RvKXWdwH50W/qipBYlv9DsD' \
-H 'origin: https://ahrefs.com' \
-H 'pragma: no-cache' \
-H 'referer: https://ahrefs.com/backlink-checker' \
-H 'sec-ch-ua: "Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: same-origin' \
-H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36' \
--data-raw '{"reportType":"TopBacklinks","signedInput":{"signature":"ed9ead2b3e58fc3f45374cd562c51c5ba563d560206d9870b4d7695ff5a14652","input":{"validUntil":"2023-06-27T20:48:03.000Z","mode":"exact","url":"ahrefs.com/backlink-checker"}}}' \
--compressed
The latter API call yields the data we can extract and save somewhere. The JSON string in the response is something like this:
[
"TopBacklinks",
{
"topBacklinks": {
"backlinks": [
{
"anchor": "Ahrefs’ Backlink Checker",
"domainRating": 91,
"edu": false,
"gov": false,
"httpCode": 200,
"redirectChain": [
{
"url": "https://ahrefs.com/backlink-checker?ref=buffer.com",
"urlNew": "None",
"redirectCode": 0,
"mustBeGray": false,
"httpCodeCross": false,
"chainDestinationChanged": false,
"hasDelReason": false,
"delReasonTitle": "None",
"delReasonKey": "None",
"lostRedirectReason": "None",
"isLost": true
}
],
"text": true,
"textPost": "",
"textPre": "6.",
"title": "27 Simple and Free SEO Tools [Updated for 2023]",
"urlFrom": "https://buffer.com/library/free-seo-tools/",
"urlTo": "https://ahrefs.com/backlink-checker",
"inRendered": true,
"inRaw": true,
"redirectCode": 0,
"original": true,
"urlToMustBeGray": false,
"urlToHttpCodeCross": false,
"urlToNew": "None",
"urlToChainDestinationChanged": false,
"urlToDelReasonTitle": "None",
"urlToDelReasonKey": "None",
"urlToHasDelReason": false,
"lost_redirect_reason": "",
"del_reason": "",
"lost_redirect_source": "",
"lost_redirect_new_target": "",
"isLost": true
},
...
],
"total": 100
}
}
]
{kind=link}
Also notice that API calls made from client side JS code have
__cf_bm cookie
added to them. This suggests that at least one of Cloudflare’s antibot
products aside from Turnstile is
deployed.
Since Ahrefs Backlink Checker is a growth tool meant to provide a potential user of Ahrefs a taste of what would be possible upon becoming a paying customer, the result list is limited to 100 entries. But that is not a problem for use cases involving exploration of obscure corners of the web.
So we want to develop the script now. But Ahrefs is using at least one feature of Cloudflare CDN that is meant to prevent or at least hinder the exact thing we want to do now. So I did some experimentation to get the details right:
- For Turnstile part, both proxied and proxyless solutions from Anti-captcha work fine. Since proxy is not needed in this case, I chose a proxyless solution.
- There is no need to talk HTTP/2, but TLS fingerprint has to be normalized to match the one from real browser.
- We don’t need to worry about
__cf_bmcookie, as it does not seem to matter much. First step of API flow works properly once we have TLS fingerprint normalised and captcha solved. - No proxies are needed as generating requests from DC IP did not cause any problems.
The complete script that does backlink scraping for a given list of pages is as follows:
#!/usr/bin/python3
import csv
from pprint import pprint
import os
import sys
from anticaptchaofficial.turnstileproxyless import *
import requests
import tls_client
FIELDNAMES = ["url", "backlink_url", "anchor", "page_title"]
def create_solver():
solver = turnstileProxyless()
solver.set_verbose(1)
solver.set_key(os.getenv("ANTICAPTCHA_KEY"))
solver.set_website_url("https://ahrefs.com/backlink-checker")
solver.set_website_key("0x4AAAAAAAAzi9ITzSN9xKMi")
return solver
def get_turnstile_token(solver):
token = solver.solve_and_return_solution()
if token != 0:
print(token)
return token
else:
print("task finished with error " + solver.error_code)
return None
def create_session():
session = tls_client.Session(
client_identifier="chrome112", random_tls_extension_order=True
)
session.headers = {
"authority": "ahrefs.com",
"accept": "*/*",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
"cache-control": "no-cache",
"content-type": "application/json; charset=utf-8",
"origin": "https://ahrefs.com",
"pragma": "no-cache",
"referer": "https://ahrefs.com/backlink-checker",
"sec-ch-ua": '"Google Chrome";v="113", "Chromium";v="113", "Not-A.Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"macOS"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
}
resp = session.get("https://ahrefs.com/backlink-checker")
print(resp)
return session
def get_backlinks(session, solver, url):
token = get_turnstile_token(solver)
if token is None:
print("Failed to get turnstile token - retrying")
token = get_turnstile_token(solver)
if token is None:
return
json_data = {"captcha": token, "mode": "exact", "url": url}
resp1 = session.post(
"https://ahrefs.com/v4/ftBacklinkCheckerPrimary", json=json_data
)
print(resp1.url)
print(resp1.text)
pprint(resp1.json())
json_arr = resp1.json()
if len(json_arr) != 2:
return None
n_backlinks = json_arr[1].get("data", dict()).get("backlinks")
if n_backlinks is None or n_backlinks == 0:
return None
signed_input = json_arr[1].get("signedInput")
json_data2 = {"reportType": "TopBacklinks", "signedInput": signed_input}
resp2 = session.post(
"https://ahrefs.com/v4/ftBacklinkCheckerSecondary", json=json_data2
)
print(resp2.url)
pprint(resp2.json())
if len(resp2.json()) != 2:
return None
return resp2.json()[1].get("topBacklinks", dict()).get("backlinks")
def main():
if len(sys.argv) != 3:
print("Usage:")
print("{} <url_list_file> <out_file>".format(sys.argv[0]))
return
url_list_file = sys.argv[1]
out_file = sys.argv[2]
solver = create_solver()
session = create_session()
in_f = open(url_list_file, "r")
urls = in_f.read().strip().split("\n")
in_f.close()
out_f = open(out_file, "w", encoding="utf-8")
csv_writer = csv.DictWriter(out_f, fieldnames=FIELDNAMES, lineterminator="\n")
csv_writer.writeheader()
for url in urls:
url = url.strip()
try:
raw_backlinks = get_backlinks(session, solver, url)
except Exception as e:
print(e)
continue
if raw_backlinks is None:
continue
for backlink_dict in raw_backlinks:
backlink_url = backlink_dict.get("urlFrom")
anchor = backlink_dict.get("anchor")
page_title = backlink_dict.get("title")
row = {
"url": url,
"backlink_url": backlink_url,
"anchor": anchor,
"page_title": page_title,
}
pprint(row)
csv_writer.writerow(row)
out_f.close()
if __name__ == "__main__":
main()
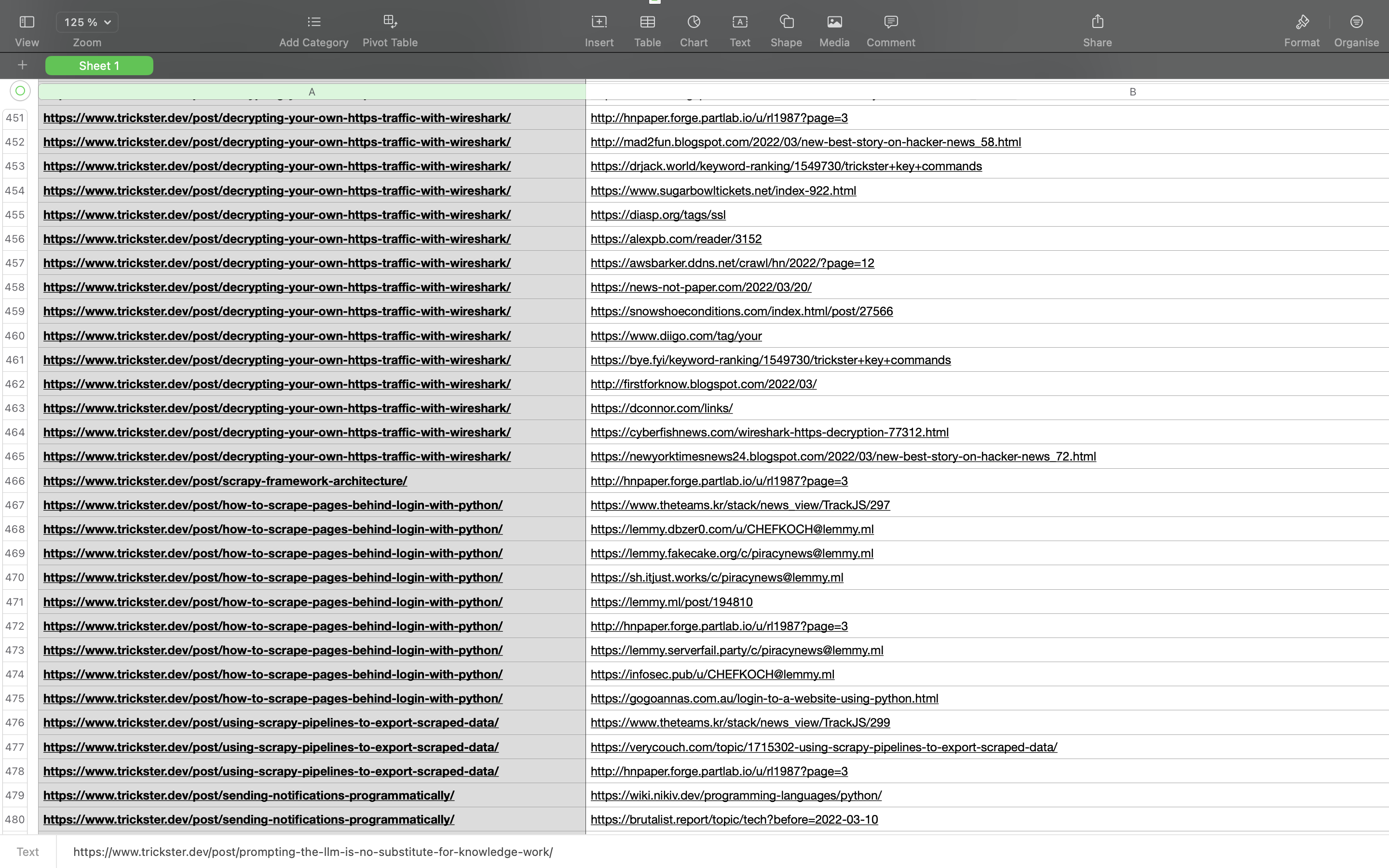
Results are saved into CSV file:
$ head res.csv
url,backlink_url,anchor,page_title
https://www.trickster.dev/post/dont-jsfuck-with-me-part-3/,https://geek.ds3783.com/2023/06/%E5%88%AB%E8%B7%9F%E6%88%91%E6%9D%A5jsfuck%EF%BC%9A%E7%AC%AC%E4%B8%89%E9%83%A8%E5%88%86/,详情参考,别跟我来JSFuck:第三部分 - 偏执的码农
https://www.trickster.dev/post/prompting-the-llm-is-no-substitute-for-knowledge-work/,https://www.theteams.kr/stack/news_view/TrackJS/10,Prompting the LLM is no substitute for knowledge work 2023-05-31,TrackJS 해외 소식 | 더팀스
https://www.trickster.dev/post/prompting-the-llm-is-no-substitute-for-knowledge-work/,https://hacker.martintudor.com/user?id=rl1987,Prompting the LLM is no substitute for knowledge work,Hacker news
https://www.trickster.dev/post/prompting-the-llm-is-no-substitute-for-knowledge-work/,https://geek.ds3783.com/2023/05/%E6%BF%80%E5%8A%B1llm%E4%B8%8D%E8%83%BD%E6%9B%BF%E4%BB%A3%E7%9F%A5%E8%AF%86%E5%B7%A5%E4%BD%9C%E3%80%82/,详情参考,激励LLM不能替代知识工作。 - 偏执的码农
https://www.trickster.dev/post/understanding-javascript-packers/,https://www.theteams.kr/stack/news_view/Packet/4,Understanding JavaScript Packers 2023-05-30,Packet 해외 소식 | 더팀스
https://www.trickster.dev/post/understanding-javascript-packers/,https://geek.ds3783.com/2023/05/%E7%90%86%E8%A7%A3javascript%E6%89%93%E5%8C%85%E5%99%A8/,详情参考,理解JavaScript打包器 - 偏执的码农
https://www.trickster.dev/post/understanding-javascript-packers/,https://hacker.martintudor.com/user?id=rl1987,Understanding JavaScript Packers,Hacker news
https://www.trickster.dev/post/understanding-javascript-packers/,https://lampfull.com/news.php,Understanding JavaScript Packers,News - Gliath
https://www.trickster.dev/post/understanding-javascript-packers/,https://lr.relyma.com/r/javascript,trickster.dev,𝚓𝚊𝚟𝚊𝚜𝚌𝚛𝚒𝚙𝚝
{kind=link}